 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Sentence Simplification with ESL Learner's Proficiency for Language Acquisition
Paper and Code
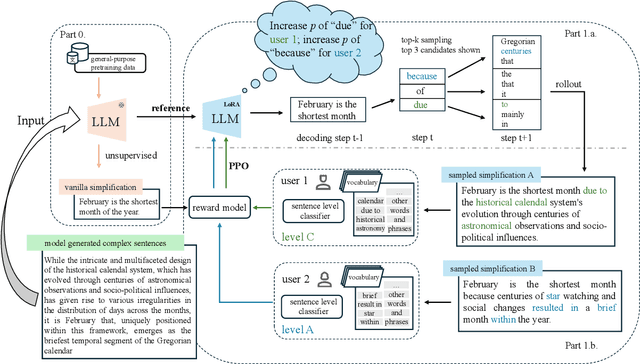
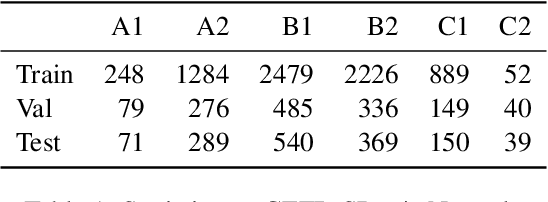
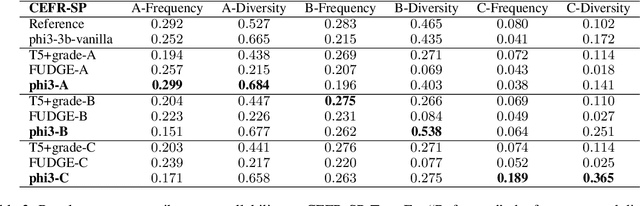
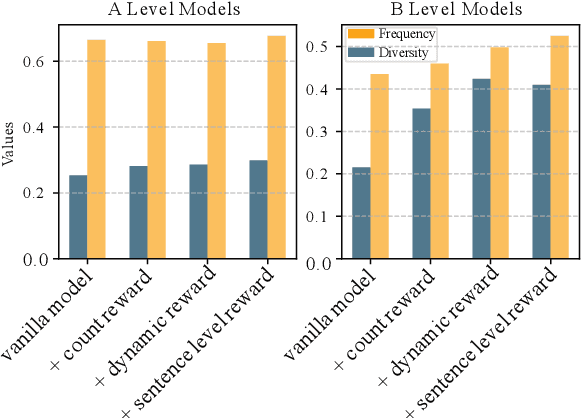
Text simplification is crucial for improving accessibility and comprehension for English as a Second Language (ESL) learners. This study goes a step further and aims to facilitate ESL learners' language acquisition by simplification. Specifically, we propose simplifying complex sentences to appropriate levels for learners while also increasing vocabulary coverage of the target level in the simplifications. We achieve this without a parallel corpus by conducting reinforcement learning on a large language model. Our method employs token-level and sentence-level rewards, and iteratively trains the model on its self-generated outputs to guide the model to search for simplification hypotheses that satisfy the target attributes. Experiment results on CEFR-SP and TurkCorpus datasets show that the proposed method can effectively increase the frequency and diversity of vocabulary of the target level by more than $20\%$ compared to baseline models, while maintaining high simplification quality.