 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoScaffold: Elastic-Scale Visual Hierarchies for Streaming Video Understanding in MLLMs
Dec 23, 2025Understanding long videos with multimodal large language models (MLLMs) remains challenging due to the heavy redundancy across frames and the need for temporally coherent representations. Existing static strategies, such as sparse sampling, frame compression, and clustering, are optimized for offline settings and often produce fragmented or over-compressed outputs when applied to continuous video streams. We present VideoScaffold, a dynamic representation framework designed for streaming video understanding. It adaptively adjusts event granularity according to video duration while preserving fine-grained visual semantics. VideoScaffold introduces two key components: Elastic-Scale Event Segmentation (EES), which performs prediction-guided segmentation to dynamically refine event boundaries, and Hierarchical Event Consolidation (HEC), which progressively aggregates semantically related segments into multi-level abstractions. Working in concert, EES and HEC enable VideoScaffold to transition smoothly from fine-grained frame understanding to abstract event reasoning as the video stream unfolds. Extensive experiments across both offline and streaming video understanding benchmarks demonstrate that VideoScaffold achieves state-of-the-art performance. The framework is modular and plug-and-play, seamlessly extending existing image-based MLLMs to continuous video comprehension. The code is available at https://github.com/zheng980629/VideoScaffold.
Linearly-evolved Transformer for Pan-sharpening
Apr 19, 2024



Vision transformer family has dominated the satellite pan-sharpening field driven by the global-wise spatial information modeling mechanism from the core self-attention ingredient. The standard modeling rules within these promising pan-sharpening methods are to roughly stack the transformer variants in a cascaded manner. Despite the remarkable advancement, their success may be at the huge cost of model parameters and FLOPs, thus preventing its application over low-resource satellites.To address this challenge between favorable performance and expensive computation, we tailor an efficient linearly-evolved transformer variant and employ it to construct a lightweight pan-sharpening framework. In detail, we deepen into the popular cascaded transformer modeling with cutting-edge methods and develop the alternative 1-order linearly-evolved transformer variant with the 1-dimensional linear convolution chain to achieve the same function. In this way, our proposed method is capable of benefiting the cascaded modeling rule while achieving favorable performance in the efficient manner. Extensive experiments over multiple satellite datasets suggest that our proposed method achieves competitive performance against other state-of-the-art with fewer computational resources. Further, the consistently favorable performance has been verified over the hyper-spectral image fusion task. Our main focus is to provide an alternative global modeling framework with an efficient structure. The code will be publicly available.
Singular Regularization with Information Bottleneck Improves Model's Adversarial Robustness
Dec 04, 2023Adversarial examples are one of the most severe threats to deep learning models. Numerous works have been proposed to study and defend adversarial examples. However, these works lack analysis of adversarial information or perturbation, which cannot reveal the mystery of adversarial examples and lose proper interpretation. In this paper, we aim to fill this gap by studying adversarial information as unstructured noise, which does not have a clear pattern. Specifically, we provide some empirical studies with singular value decomposition, by decomposing images into several matrices, to analyze adversarial information for different attacks. Based on the analysis, we propose a new module to regularize adversarial information and combine information bottleneck theory, which is proposed to theoretically restrict intermediate representations. Therefore, our method is interpretable. Moreover, the fashion of our design is a novel principle that is general and unified. Equipped with our new module, we evaluate two popular model structures on two mainstream datasets with various adversarial attacks. The results indicate that the improvement in robust accuracy is significant. On the other hand, we prove that our method is efficient with only a few additional parameters and able to be explained under regional faithfulness analysis.
Empowering Low-Light Image Enhancer through Customized Learnable Priors
Sep 05, 2023Deep neural networks have achieved remarkable progress in enhancing low-light images by improving their brightness and eliminating noise. However, most existing methods construct end-to-end mapping networks heuristically, neglecting the intrinsic prior of image enhancement task and lacking transparency and interpretability. Although some unfolding solutions have been proposed to relieve these issues, they rely on proximal operator networks that deliver ambiguous and implicit priors. In this work, we propose a paradigm for low-light image enhancement that explores the potential of customized learnable priors to improve the transparency of the deep unfolding paradigm. Motivated by the powerful feature representation capability of Masked Autoencoder (MAE), we customize MAE-based illumination and noise priors and redevelop them from two perspectives: 1) \textbf{structure flow}: we train the MAE from a normal-light image to its illumination properties and then embed it into the proximal operator design of the unfolding architecture; and m2) \textbf{optimization flow}: we train MAE from a normal-light image to its gradient representation and then employ it as a regularization term to constrain noise in the model output. These designs improve the interpretability and representation capability of the model.Extensive experiments on multiple low-light image enhancement datasets demonstrate the superiority of our proposed paradigm over state-of-the-art methods. Code is available at https://github.com/zheng980629/CUE.
Learned Image Reasoning Prior Penetrates Deep Unfolding Network for Panchromatic and Multi-Spectral Image Fusion
Aug 30, 2023The success of deep neural networks for pan-sharpening is commonly in a form of black box, lacking transparency and interpretability. To alleviate this issue, we propose a novel model-driven deep unfolding framework with image reasoning prior tailored for the pan-sharpening task. Different from existing unfolding solutions that deliver the proximal operator networks as the uncertain and vague priors, our framework is motivated by the content reasoning ability of masked autoencoders (MAE) with insightful designs. Specifically, the pre-trained MAE with spatial masking strategy, acting as intrinsic reasoning prior, is embedded into unfolding architecture. Meanwhile, the pre-trained MAE with spatial-spectral masking strategy is treated as the regularization term within loss function to constrain the spatial-spectral consistency. Such designs penetrate the image reasoning prior into deep unfolding networks while improving its interpretability and representation capability. The uniqueness of our framework is that the holistic learning process is explicitly integrated with the inherent physical mechanism underlying the pan-sharpening task. Extensive experiments on multiple satellite datasets demonstrate the superiority of our method over the existing state-of-the-art approaches. Code will be released at \url{https://manman1995.github.io/}.
Random Weights Networks Work as Loss Prior Constraint for Image Restoration
Mar 29, 2023



In this paper, orthogonal to the existing data and model studies, we instead resort our efforts to investigate the potential of loss function in a new perspective and present our belief ``Random Weights Networks can Be Acted as Loss Prior Constraint for Image Restoration''. Inspired by Functional theory, we provide several alternative solutions to implement our belief in the strict mathematical manifolds including Taylor's Unfolding Network, Invertible Neural Network, Central Difference Convolution and Zero-order Filtering as ``random weights network prototype'' with respect of the following four levels: 1) the different random weights strategies; 2) the different network architectures, \emph{eg,} pure convolution layer or transformer; 3) the different network architecture depths; 4) the different numbers of random weights network combination. Furthermore, to enlarge the capability of the randomly initialized manifolds, we devise the manner of random weights in the following two variants: 1) the weights are randomly initialized only once during the whole training procedure; 2) the weights are randomly initialized at each training iteration epoch. Our propose belief can be directly inserted into existing networks without any training and testing computational cost. Extensive experiments across multiple image restoration tasks, including image de-noising, low-light image enhancement, guided image super-resolution demonstrate the consistent performance gains obtained by introducing our belief. To emphasize, our main focus is to spark the realms of loss function and save their current neglected status. Code will be publicly available.
Unlocking Masked Autoencoders as Loss Function for Image and Video Restoration
Mar 29, 2023



Image and video restoration has achieved a remarkable leap with the advent of deep learning. The success of deep learning paradigm lies in three key components: data, model, and loss. Currently, many efforts have been devoted to the first two while seldom study focuses on loss function. With the question ``are the de facto optimization functions e.g., $L_1$, $L_2$, and perceptual losses optimal?'', we explore the potential of loss and raise our belief ``learned loss function empowers the learning capability of neural networks for image and video restoration''. Concretely, we stand on the shoulders of the masked Autoencoders (MAE) and formulate it as a `learned loss function', owing to the fact the pre-trained MAE innately inherits the prior of image reasoning. We investigate the efficacy of our belief from three perspectives: 1) from task-customized MAE to native MAE, 2) from image task to video task, and 3) from transformer structure to convolution neural network structure. Extensive experiments across multiple image and video tasks, including image denoising, image super-resolution, image enhancement, guided image super-resolution, video denoising, and video enhancement, demonstrate the consistent performance improvements introduced by the learned loss function. Besides, the learned loss function is preferable as it can be directly plugged into existing networks during training without involving computations in the inference stage. Code will be publicly available.
CNSNet: A Cleanness-Navigated-Shadow Network for Shadow Removal
Sep 06, 2022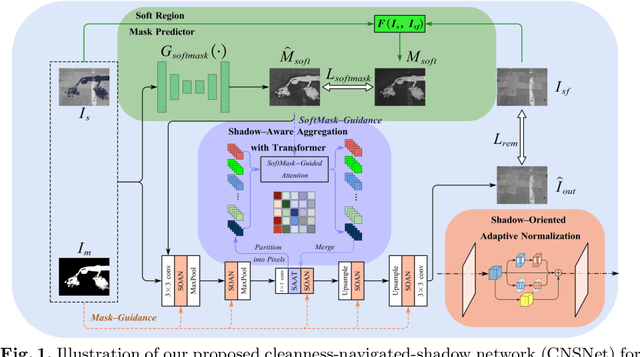
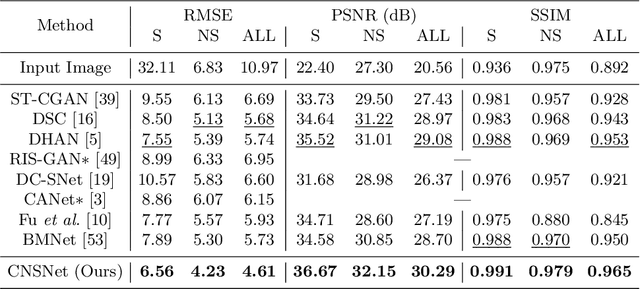

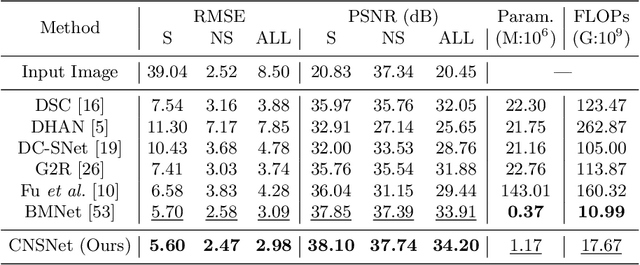
The key to shadow removal is recovering the contents of the shadow regions with the guidance of the non-shadow regions. Due to the inadequate long-range modeling, the CNN-based approaches cannot thoroughly investigate the information from the non-shadow regions. To solve this problem, we propose a novel cleanness-navigated-shadow network (CNSNet), with a shadow-oriented adaptive normalization (SOAN) module and a shadow-aware aggregation with transformer (SAAT) module based on the shadow mask. Under the guidance of the shadow mask, the SOAN module formulates the statistics from the non-shadow region and adaptively applies them to the shadow region for region-wise restoration. The SAAT module utilizes the shadow mask to precisely guide the restoration of each shadowed pixel by considering the highly relevant pixels from the shadow-free regions for global pixel-wise restoration. Extensive experiments on three benchmark datasets (ISTD, ISTD+, and SRD) show that our method achieves superior de-shadowing performance.
Enhancement by Your Aesthetic: An Intelligible Unsupervised Personalized Enhancer for Low-Light Images
Jul 15, 2022
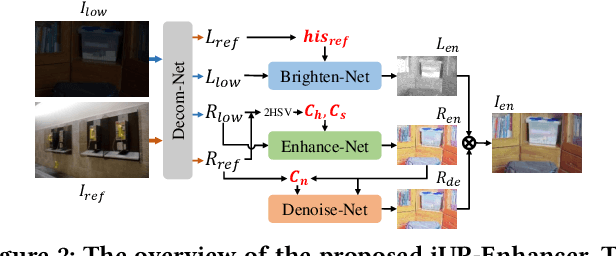
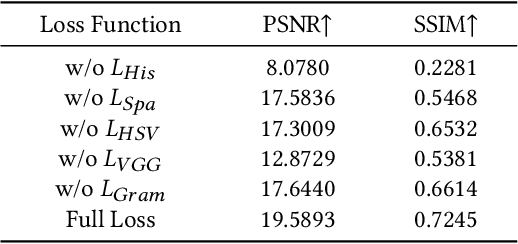

Low-light image enhancement is an inherently subjective process whose targets vary with the user's aesthetic. Motivated by this, several personalized enhancement methods have been investigated. However, the enhancement process based on user preferences in these techniques is invisible, i.e., a "black box". In this work, we propose an intelligible unsupervised personalized enhancer (iUPEnhancer) for low-light images, which establishes the correlations between the low-light and the unpaired reference images with regard to three user-friendly attributions (brightness, chromaticity, and noise). The proposed iUP-Enhancer is trained with the guidance of these correlations and the corresponding unsupervised loss functions. Rather than a "black box" process, our iUP-Enhancer presents an intelligible enhancement process with the above attributions. Extensive experiments demonstrate that the proposed algorithm produces competitive qualitative and quantitative results while maintaining excellent flexibility and scalability. This can be validated by personalization with single/multiple references, cross-attribution references, or merely adjusting parameters.