 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral Image Fusion with Spectral-Band and Fusion-Scale Agnosticism
Feb 02, 2026Current deep learning models for Multispectral and Hyperspectral Image Fusion (MS/HS fusion) are typically designed for fixed spectral bands and spatial scales, which limits their transferability across diverse sensors. To address this, we propose SSA, a universal framework for MS/HS fusion with spectral-band and fusion-scale agnosticism. Specifically, we introduce Matryoshka Kernel (MK), a novel operator that enables a single model to adapt to arbitrary numbers of spectral channels. Meanwhile, we build SSA upon an Implicit Neural Representation (INR) backbone that models the HS signal as a continuous function, enabling reconstruction at arbitrary spatial resolutions. Together, these two forms of agnosticism enable a single MS/HS fusion model that generalizes effectively to unseen sensors and spatial scales. Extensive experiments demonstrate that our single model achieves state-of-the-art performance while generalizing well to unseen sensors and scales, paving the way toward future HS foundation models.
Kernel Space Diffusion Model for Efficient Remote Sensing Pansharpening
May 25, 2025Pansharpening is a fundamental task in remote sensing that integrates high-resolution panchromatic imagery (PAN) with low-resolution multispectral imagery (LRMS) to produce an enhanced image with both high spatial and spectral resolution. Despite significant progress in deep learning-based approaches, existing methods often fail to capture the global priors inherent in remote sensing data distributions. Diffusion-based models have recently emerged as promising solutions due to their powerful distribution mapping capabilities; however, they suffer from significant inference latency, which limits their practical applicability. In this work, we propose the Kernel Space Diffusion Model (KSDiff), a novel approach that leverages diffusion processes in a latent space to generate convolutional kernels enriched with global contextual information, thereby improving pansharpening quality while enabling faster inference. Specifically, KSDiff constructs these kernels through the integration of a low-rank core tensor generator and a unified factor generator, orchestrated by a structure-aware multi-head attention mechanism. We further introduce a two-stage training strategy tailored for pansharpening, enabling KSDiff to serve as a framework for enhancing existing pansharpening architectures. Experiments on three widely used datasets, including WorldView-3, GaoFen-2, and QuickBird, demonstrate the superior performance of KSDiff both qualitatively and quantitatively. Code will be released upon possible acceptance.
Taming Flow Matching with Unbalanced Optimal Transport into Fast Pansharpening
Mar 19, 2025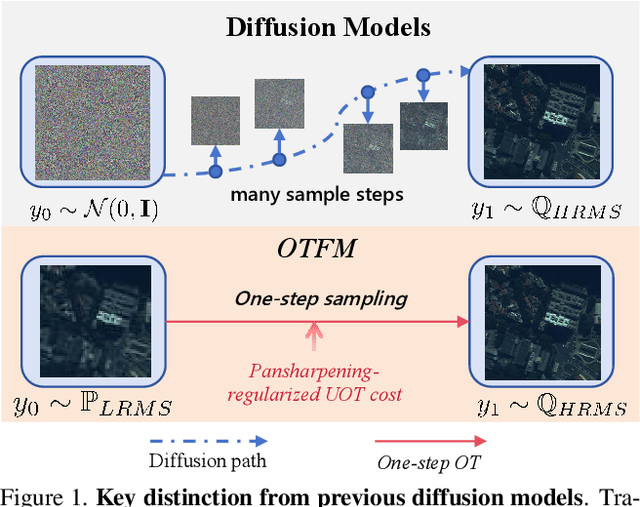
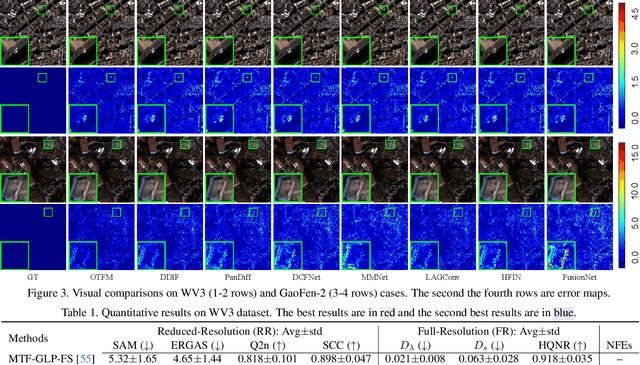
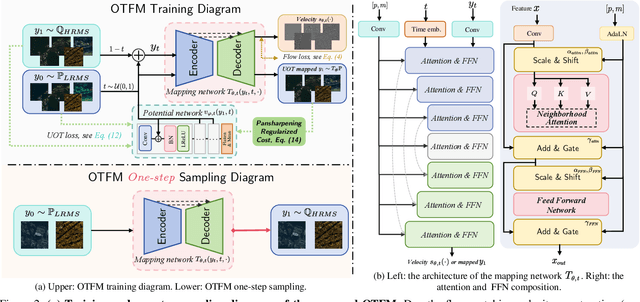
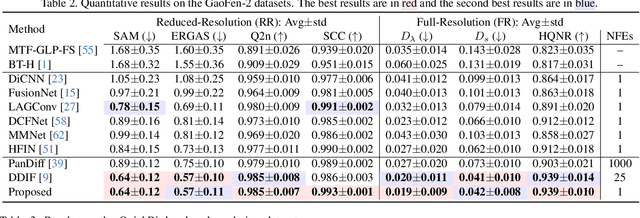
Pansharpening, a pivotal task in remote sensing for fusing high-resolution panchromatic and multispectral imagery, has garnered significant research interest. Recent advancements employing diffusion models based on stochastic differential equations (SDEs) have demonstrated state-of-the-art performance. However, the inherent multi-step sampling process of SDEs imposes substantial computational overhead, hindering practical deployment. While existing methods adopt efficient samplers, knowledge distillation, or retraining to reduce sampling steps (e.g., from 1,000 to fewer steps), such approaches often compromise fusion quality. In this work, we propose the Optimal Transport Flow Matching (OTFM) framework, which integrates the dual formulation of unbalanced optimal transport (UOT) to achieve one-step, high-quality pansharpening. Unlike conventional OT formulations that enforce rigid distribution alignment, UOT relaxes marginal constraints to enhance modeling flexibility, accommodating the intrinsic spectral and spatial disparities in remote sensing data. Furthermore, we incorporate task-specific regularization into the UOT objective, enhancing the robustness of the flow model. The OTFM framework enables simulation-free training and single-step inference while maintaining strict adherence to pansharpening constraints. Experimental evaluations across multiple datasets demonstrate that OTFM matches or exceeds the performance of previous regression-based models and leading diffusion-based methods while only needing one sampling step. Codes are available at https://github.com/294coder/PAN-OTFM.
MMAIF: Multi-task and Multi-degradation All-in-One for Image Fusion with Language Guidance
Mar 19, 2025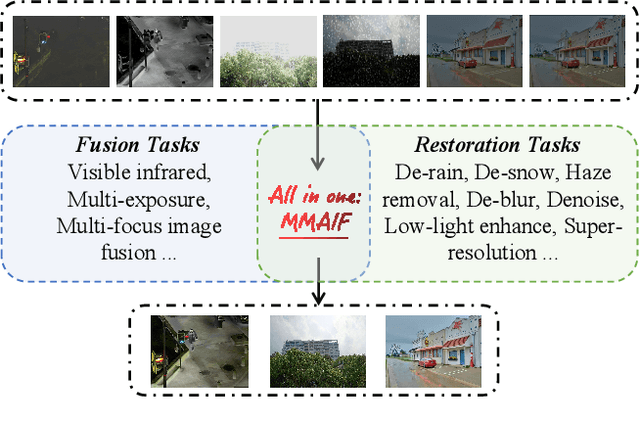

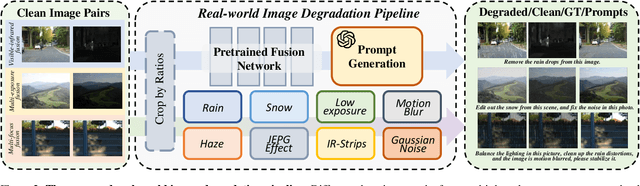
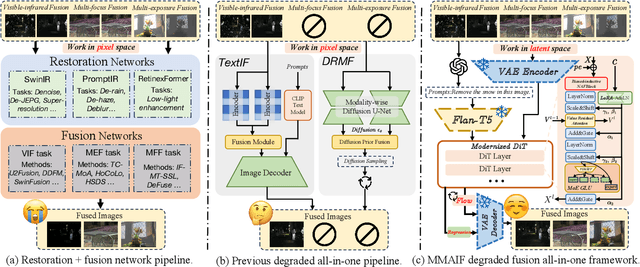
Image fusion, a fundamental low-level vision task, aims to integrate multiple image sequences into a single output while preserving as much information as possible from the input. However, existing methods face several significant limitations: 1) requiring task- or dataset-specific models; 2) neglecting real-world image degradations (\textit{e.g.}, noise), which causes failure when processing degraded inputs; 3) operating in pixel space, where attention mechanisms are computationally expensive; and 4) lacking user interaction capabilities. To address these challenges, we propose a unified framework for multi-task, multi-degradation, and language-guided image fusion. Our framework includes two key components: 1) a practical degradation pipeline that simulates real-world image degradations and generates interactive prompts to guide the model; 2) an all-in-one Diffusion Transformer (DiT) operating in latent space, which fuses a clean image conditioned on both the degraded inputs and the generated prompts. Furthermore, we introduce principled modifications to the original DiT architecture to better suit the fusion task. Based on this framework, we develop two versions of the model: Regression-based and Flow Matching-based variants. Extensive qualitative and quantitative experiments demonstrate that our approach effectively addresses the aforementioned limitations and outperforms previous restoration+fusion and all-in-one pipelines. Codes are available at https://github.com/294coder/MMAIF.
Fourier-enhanced Implicit Neural Fusion Network for Multispectral and Hyperspectral Image Fusion
Apr 23, 2024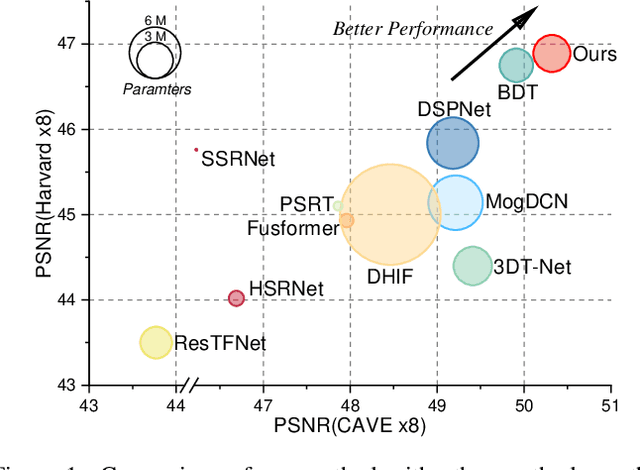
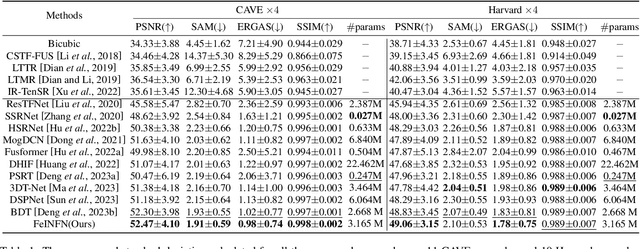
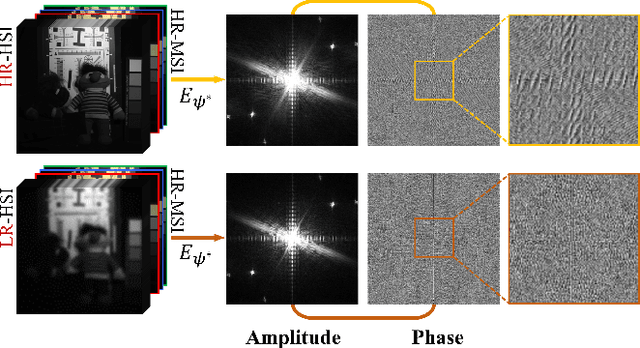
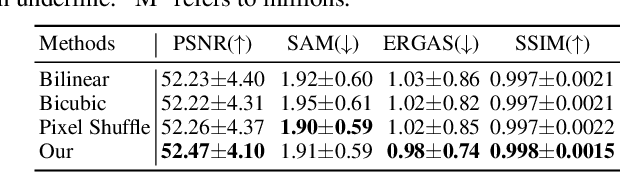
Recently, implicit neural representations (INR) have made significant strides in various vision-related domains, providing a novel solution for Multispectral and Hyperspectral Image Fusion (MHIF) tasks. However, INR is prone to losing high-frequency information and is confined to the lack of global perceptual capabilities. To address these issues, this paper introduces a Fourier-enhanced Implicit Neural Fusion Network (FeINFN) specifically designed for MHIF task, targeting the following phenomena: The Fourier amplitudes of the HR-HSI latent code and LR-HSI are remarkably similar; however, their phases exhibit different patterns. In FeINFN, we innovatively propose a spatial and frequency implicit fusion function (Spa-Fre IFF), helping INR capture high-frequency information and expanding the receptive field. Besides, a new decoder employing a complex Gabor wavelet activation function, called Spatial-Frequency Interactive Decoder (SFID), is invented to enhance the interaction of INR features. Especially, we further theoretically prove that the Gabor wavelet activation possesses a time-frequency tightness property that favors learning the optimal bandwidths in the decoder. Experiments on two benchmark MHIF datasets verify the state-of-the-art (SOTA) performance of the proposed method, both visually and quantitatively. Also, ablation studies demonstrate the mentioned contributions. The code will be available on Anonymous GitHub (https://anonymous.4open.science/r/FeINFN-15C9/) after possible acceptance.
Linearly-evolved Transformer for Pan-sharpening
Apr 19, 2024



Vision transformer family has dominated the satellite pan-sharpening field driven by the global-wise spatial information modeling mechanism from the core self-attention ingredient. The standard modeling rules within these promising pan-sharpening methods are to roughly stack the transformer variants in a cascaded manner. Despite the remarkable advancement, their success may be at the huge cost of model parameters and FLOPs, thus preventing its application over low-resource satellites.To address this challenge between favorable performance and expensive computation, we tailor an efficient linearly-evolved transformer variant and employ it to construct a lightweight pan-sharpening framework. In detail, we deepen into the popular cascaded transformer modeling with cutting-edge methods and develop the alternative 1-order linearly-evolved transformer variant with the 1-dimensional linear convolution chain to achieve the same function. In this way, our proposed method is capable of benefiting the cascaded modeling rule while achieving favorable performance in the efficient manner. Extensive experiments over multiple satellite datasets suggest that our proposed method achieves competitive performance against other state-of-the-art with fewer computational resources. Further, the consistently favorable performance has been verified over the hyper-spectral image fusion task. Our main focus is to provide an alternative global modeling framework with an efficient structure. The code will be publicly available.
SSDiff: Spatial-spectral Integrated Diffusion Model for Remote Sensing Pansharpening
Apr 17, 2024



Pansharpening is a significant image fusion technique that merges the spatial content and spectral characteristics of remote sensing images to generate high-resolution multispectral images. Recently, denoising diffusion probabilistic models have been gradually applied to visual tasks, enhancing controllable image generation through low-rank adaptation (LoRA). In this paper, we introduce a spatial-spectral integrated diffusion model for the remote sensing pansharpening task, called SSDiff, which considers the pansharpening process as the fusion process of spatial and spectral components from the perspective of subspace decomposition. Specifically, SSDiff utilizes spatial and spectral branches to learn spatial details and spectral features separately, then employs a designed alternating projection fusion module (APFM) to accomplish the fusion. Furthermore, we propose a frequency modulation inter-branch module (FMIM) to modulate the frequency distribution between branches. The two components of SSDiff can perform favorably against the APFM when utilizing a LoRA-like branch-wise alternative fine-tuning method. It refines SSDiff to capture component-discriminating features more sufficiently. Finally, extensive experiments on four commonly used datasets, i.e., WorldView-3, WorldView-2, GaoFen-2, and QuickBird, demonstrate the superiority of SSDiff both visually and quantitatively. The code will be made open source after possible acceptance.
Neural Shrödinger Bridge Matching for Pansharpening
Apr 17, 2024Recent diffusion probabilistic models (DPM) in the field of pansharpening have been gradually gaining attention and have achieved state-of-the-art (SOTA) performance. In this paper, we identify shortcomings in directly applying DPMs to the task of pansharpening as an inverse problem: 1) initiating sampling directly from Gaussian noise neglects the low-resolution multispectral image (LRMS) as a prior; 2) low sampling efficiency often necessitates a higher number of sampling steps. We first reformulate pansharpening into the stochastic differential equation (SDE) form of an inverse problem. Building upon this, we propose a Schr\"odinger bridge matching method that addresses both issues. We design an efficient deep neural network architecture tailored for the proposed SB matching. In comparison to the well-established DL-regressive-based framework and the recent DPM framework, our method demonstrates SOTA performance with fewer sampling steps. Moreover, we discuss the relationship between SB matching and other methods based on SDEs and ordinary differential equations (ODEs), as well as its connection with optimal transport. Code will be available.
A Novel State Space Model with Local Enhancement and State Sharing for Image Fusion
Apr 14, 2024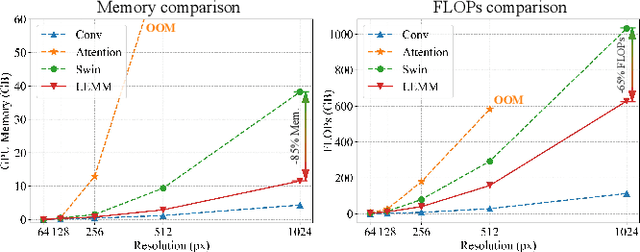

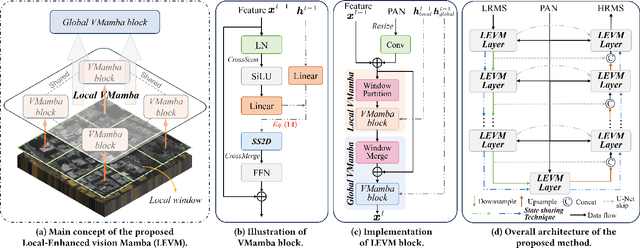
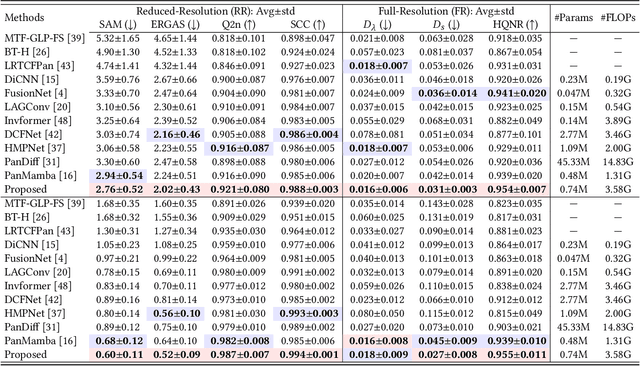
In image fusion tasks, images from different sources possess distinct characteristics. This has driven the development of numerous methods to explore better ways of fusing them while preserving their respective characteristics. Mamba, as a state space model, has emerged in the field of natural language processing. Recently, many studies have attempted to extend Mamba to vision tasks. However, due to the nature of images different from casual language sequences, the limited state capacity of Mamba weakens its ability to model image information. Additionally, the sequence modeling ability of Mamba is only capable of spatial information and cannot effectively capture the rich spectral information in images. Motivated by these challenges, we customize and improve the vision Mamba network designed for the image fusion task. Specifically, we propose the local-enhanced vision Mamba block, dubbed as LEVM. The LEVM block can improve local information perception of the network and simultaneously learn local and global spatial information. Furthermore, we propose the state sharing technique to enhance spatial details and integrate spatial and spectral information. Finally, the overall network is a multi-scale structure based on vision Mamba, called LE-Mamba. Extensive experiments show the proposed methods achieve state-of-the-art results on multispectral pansharpening and multispectral and hyperspectral image fusion datasets, and demonstrate the effectiveness of the proposed approach. Code will be made available.
APLA: Additional Perturbation for Latent Noise with Adversarial Training Enables Consistency
Aug 24, 2023



Diffusion models have exhibited promising progress in video generation. However, they often struggle to retain consistent details within local regions across frames. One underlying cause is that traditional diffusion models approximate Gaussian noise distribution by utilizing predictive noise, without fully accounting for the impact of inherent information within the input itself. Additionally, these models emphasize the distinction between predictions and references, neglecting information intrinsic to the videos. To address this limitation, inspired by the self-attention mechanism, we propose a novel text-to-video (T2V) generation network structure based on diffusion models, dubbed Additional Perturbation for Latent noise with Adversarial training (APLA). Our approach only necessitates a single video as input and builds upon pre-trained stable diffusion networks. Notably, we introduce an additional compact network, known as the Video Generation Transformer (VGT). This auxiliary component is designed to extract perturbations from the inherent information contained within the input, thereby refining inconsistent pixels during temporal predictions. We leverage a hybrid architecture of transformers and convolutions to compensate for temporal intricacies, enhancing consistency between different frames within the video. Experiments demonstrate a noticeable improvement in the consistency of the generated videos both qualitatively and quantitatively.