 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResPanDiff: Diffusion Model for Pansharpening by Inferring Residual Inference
Jan 10, 2025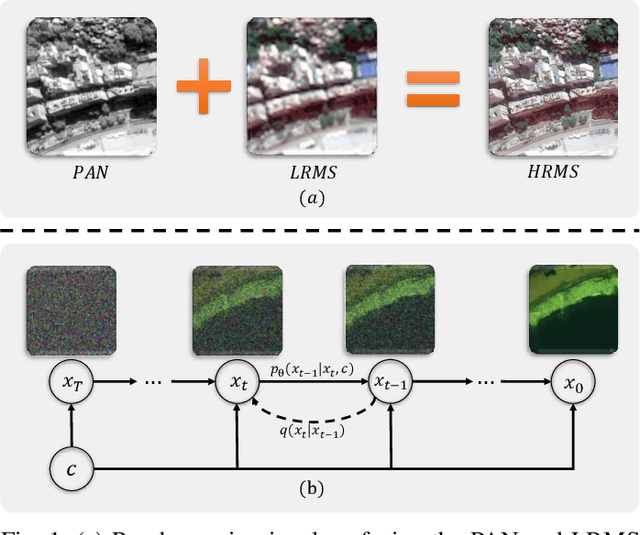


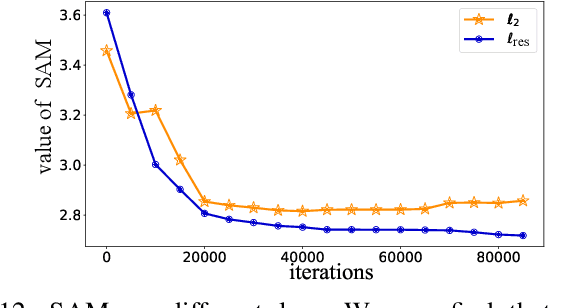
The implementation of diffusion-based pansharpening task is predominantly constrained by its slow inference speed, which results from numerous sampling steps. Despite the existing techniques aiming to accelerate sampling, they often compromise performance when fusing multi-source images. To ease this limitation, we introduce a novel and efficient diffusion model named Diffusion Model for Pansharpening by Inferring Residual Inference (ResPanDiff), which significantly reduces the number of diffusion steps without sacrificing the performance to tackle pansharpening task. In ResPanDiff, we innovatively propose a Markov chain that transits from noisy residuals to the residuals between the LRMS and HRMS images, thereby reducing the number of sampling steps and enhancing performance. Additionally, we design the latent space to help model extract more features at the encoding stage, Shallow Cond-Injection~(SC-I) to help model fetch cond-injected hidden features with higher dimensions, and loss functions to give a better guidance for the residual generation task. enabling the model to achieve superior performance in residual generation. Furthermore, experimental evaluations on pansharpening datasets demonstrate that the proposed method achieves superior outcomes compared to recent state-of-the-art~(SOTA) techniques, requiring only 15 sampling steps, which reduces over $90\%$ step compared with the benchmark diffusion models. Our experiments also include thorough discussions and ablation studies to underscore the effectiveness of our approach.
APLA: Additional Perturbation for Latent Noise with Adversarial Training Enables Consistency
Aug 24, 2023



Diffusion models have exhibited promising progress in video generation. However, they often struggle to retain consistent details within local regions across frames. One underlying cause is that traditional diffusion models approximate Gaussian noise distribution by utilizing predictive noise, without fully accounting for the impact of inherent information within the input itself. Additionally, these models emphasize the distinction between predictions and references, neglecting information intrinsic to the videos. To address this limitation, inspired by the self-attention mechanism, we propose a novel text-to-video (T2V) generation network structure based on diffusion models, dubbed Additional Perturbation for Latent noise with Adversarial training (APLA). Our approach only necessitates a single video as input and builds upon pre-trained stable diffusion networks. Notably, we introduce an additional compact network, known as the Video Generation Transformer (VGT). This auxiliary component is designed to extract perturbations from the inherent information contained within the input, thereby refining inconsistent pixels during temporal predictions. We leverage a hybrid architecture of transformers and convolutions to compensate for temporal intricacies, enhancing consistency between different frames within the video. Experiments demonstrate a noticeable improvement in the consistency of the generated videos both qualitatively and quantitatively.