 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel State Space Model with Local Enhancement and State Sharing for Image Fusion
Paper and Code
Apr 14, 2024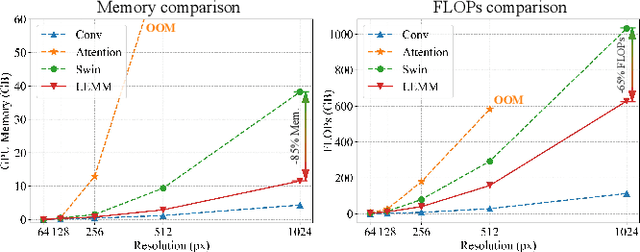

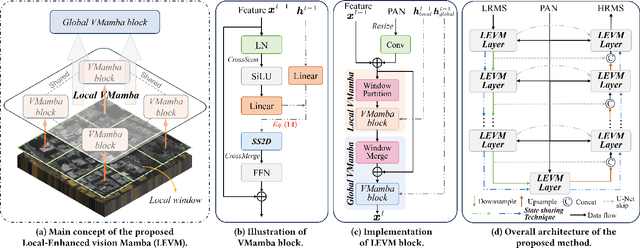
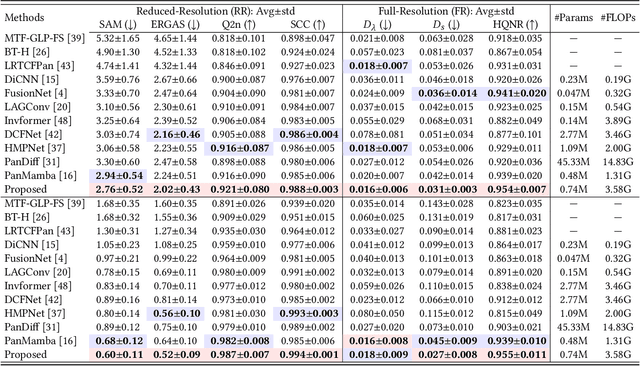
In image fusion tasks, images from different sources possess distinct characteristics. This has driven the development of numerous methods to explore better ways of fusing them while preserving their respective characteristics. Mamba, as a state space model, has emerged in the field of natural language processing. Recently, many studies have attempted to extend Mamba to vision tasks. However, due to the nature of images different from casual language sequences, the limited state capacity of Mamba weakens its ability to model image information. Additionally, the sequence modeling ability of Mamba is only capable of spatial information and cannot effectively capture the rich spectral information in images. Motivated by these challenges, we customize and improve the vision Mamba network designed for the image fusion task. Specifically, we propose the local-enhanced vision Mamba block, dubbed as LEVM. The LEVM block can improve local information perception of the network and simultaneously learn local and global spatial information. Furthermore, we propose the state sharing technique to enhance spatial details and integrate spatial and spectral information. Finally, the overall network is a multi-scale structure based on vision Mamba, called LE-Mamba. Extensive experiments show the proposed methods achieve state-of-the-art results on multispectral pansharpening and multispectral and hyperspectral image fusion datasets, and demonstrate the effectiveness of the proposed approach. Code will be made available.