 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoCom: Kilobyte-Scale Communication-Efficient Collaborative Perception with Information Bottleneck
Dec 11, 2025Precise environmental perception is critical for the reliability of autonomous driving systems. While collaborative perception mitigates the limitations of single-agent perception through information sharing, it encounters a fundamental communication-performance trade-off. Existing communication-efficient approaches typically assume MB-level data transmission per collaboration, which may fail due to practical network constraints. To address these issues, we propose InfoCom, an information-aware framework establishing the pioneering theoretical foundation for communication-efficient collaborative perception via extended Information Bottleneck principles. Departing from mainstream feature manipulation, InfoCom introduces a novel information purification paradigm that theoretically optimizes the extraction of minimal sufficient task-critical information under Information Bottleneck constraints. Its core innovations include: i) An Information-Aware Encoding condensing features into minimal messages while preserving perception-relevant information; ii) A Sparse Mask Generation identifying spatial cues with negligible communication cost; and iii) A Multi-Scale Decoding that progressively recovers perceptual information through mask-guided mechanisms rather than simple feature reconstruction. Comprehensive experiments across multiple datasets demonstrate that InfoCom achieves near-lossless perception while reducing communication overhead from megabyte to kilobyte-scale, representing 440-fold and 90-fold reductions per agent compared to Where2comm and ERMVP, respectively.
A Knowledge-driven Adaptive Collaboration of LLMs for Enhancing Medical Decision-making
Sep 18, 2025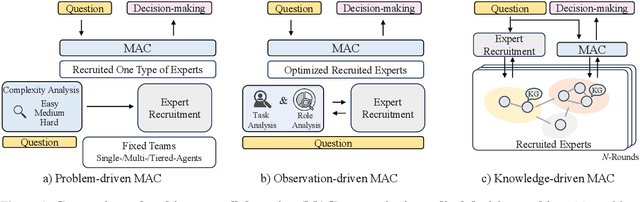
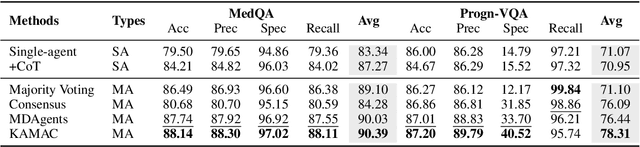
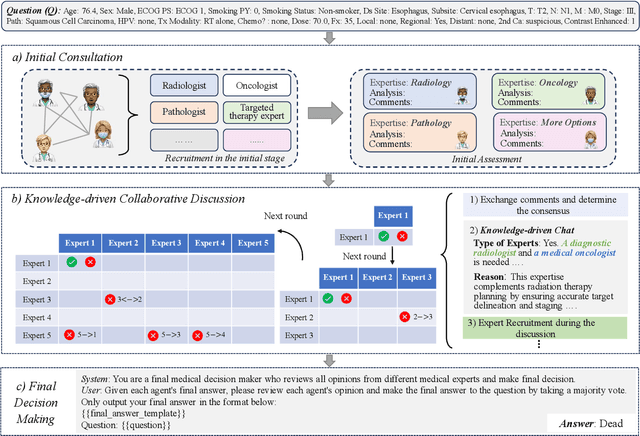
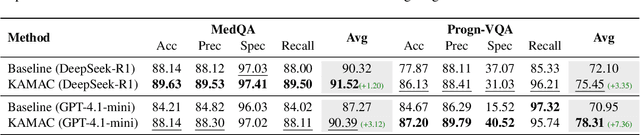
Medical decision-making often involves integrating knowledge from multiple clinical specialties, typically achieved through multidisciplinary teams. Inspired by this collaborative process, recent work has leveraged large language models (LLMs) in multi-agent collaboration frameworks to emulate expert teamwork. While these approaches improve reasoning through agent interaction, they are limited by static, pre-assigned roles, which hinder adaptability and dynamic knowledge integration. To address these limitations, we propose KAMAC, a Knowledge-driven Adaptive Multi-Agent Collaboration framework that enables LLM agents to dynamically form and expand expert teams based on the evolving diagnostic context. KAMAC begins with one or more expert agents and then conducts a knowledge-driven discussion to identify and fill knowledge gaps by recruiting additional specialists as needed. This supports flexible, scalable collaboration in complex clinical scenarios, with decisions finalized through reviewing updated agent comments. Experiments on two real-world medical benchmarks demonstrate that KAMAC significantly outperforms both single-agent and advanced multi-agent methods, particularly in complex clinical scenarios (i.e., cancer prognosis) requiring dynamic, cross-specialty expertise. Our code is publicly available at: https://github.com/XiaoXiao-Woo/KAMAC.
Adaptive Confidence-Wise Loss for Improved Lens Structure Segmentation in AS-OCT
Aug 12, 2025Precise lens structure segmentation is essential for the design of intraocular lenses (IOLs) in cataract surgery. Existing deep segmentation networks typically weight all pixels equally under cross-entropy (CE) loss, overlooking the fact that sub-regions of lens structures are inhomogeneous (e.g., some regions perform better than others) and that boundary regions often suffer from poor segmentation calibration at the pixel level. Clinically, experts annotate different sub-regions of lens structures with varying confidence levels, considering factors such as sub-region proportions, ambiguous boundaries, and lens structure shapes. Motivated by this observation, we propose an Adaptive Confidence-Wise (ACW) loss to group each lens structure sub-region into different confidence sub-regions via a confidence threshold from the unique region aspect, aiming to exploit the potential of expert annotation confidence prior. Specifically, ACW clusters each target region into low-confidence and high-confidence groups and then applies a region-weighted loss to reweigh each confidence group. Moreover, we design an adaptive confidence threshold optimization algorithm to adjust the confidence threshold of ACW dynamically. Additionally, to better quantify the miscalibration errors in boundary region segmentation, we propose a new metric, termed Boundary Expected Calibration Error (BECE). Extensive experiments on a clinical lens structure AS-OCT dataset and other multi-structure datasets demonstrate that our ACW significantly outperforms competitive segmentation loss methods across different deep segmentation networks (e.g., MedSAM). Notably, our method surpasses CE with 6.13% IoU gain, 4.33% DSC increase, and 4.79% BECE reduction in lens structure segmentation under U-Net. The code of this paper is available at https://github.com/XiaoLing12138/Adaptive-Confidence-Wise-Loss.
Expert-Like Reparameterization of Heterogeneous Pyramid Receptive Fields in Efficient CNNs for Fair Medical Image Classification
May 19, 2025Efficient convolutional neural network (CNN) architecture designs have attracted growing research interests. However, they usually apply single receptive field (RF), small asymmetric RFs, or pyramid RFs to learn different feature representations, still encountering two significant challenges in medical image classification tasks: 1) They have limitations in capturing diverse lesion characteristics efficiently, e.g., tiny, coordination, small and salient, which have unique roles on results, especially imbalanced medical image classification. 2) The predictions generated by those CNNs are often unfair/biased, bringing a high risk by employing them to real-world medical diagnosis conditions. To tackle these issues, we develop a new concept, Expert-Like Reparameterization of Heterogeneous Pyramid Receptive Fields (ERoHPRF), to simultaneously boost medical image classification performance and fairness. This concept aims to mimic the multi-expert consultation mode by applying the well-designed heterogeneous pyramid RF bags to capture different lesion characteristics effectively via convolution operations with multiple heterogeneous kernel sizes. Additionally, ERoHPRF introduces an expert-like structural reparameterization technique to merge its parameters with the two-stage strategy, ensuring competitive computation cost and inference speed through comparisons to a single RF. To manifest the effectiveness and generalization ability of ERoHPRF, we incorporate it into mainstream efficient CNN architectures. The extensive experiments show that our method maintains a better trade-off than state-of-the-art methods in terms of medical image classification, fairness, and computation overhead. The codes of this paper will be released soon.
CAST: Time-Varying Treatment Effects with Application to Chemotherapy and Radiotherapy on Head and Neck Squamous Cell Carcinoma
May 09, 2025Causal machine learning (CML) enables individualized estimation of treatment effects, offering critical advantages over traditional correlation-based methods. However, existing approaches for medical survival data with censoring such as causal survival forests estimate effects at fixed time points, limiting their ability to capture dynamic changes over time. We introduce Causal Analysis for Survival Trajectories (CAST), a novel framework that models treatment effects as continuous functions of time following treatment. By combining parametric and non-parametric methods, CAST overcomes the limitations of discrete time-point analysis to estimate continuous effect trajectories. Using the RADCURE dataset [1] of 2,651 patients with head and neck squamous cell carcinoma (HNSCC) as a clinically relevant example, CAST models how chemotherapy and radiotherapy effects evolve over time at the population and individual levels. By capturing the temporal dynamics of treatment response, CAST reveals how treatment effects rise, peak, and decline over the follow-up period, helping clinicians determine when and for whom treatment benefits are maximized. This framework advances the application of CML to personalized care in HNSCC and other life-threatening medical conditions. Source code/data available at: https://github.com/CAST-FW/HNSCC
FM-LoRA: Factorized Low-Rank Meta-Prompting for Continual Learning
Apr 09, 2025How to adapt a pre-trained model continuously for sequential tasks with different prediction class labels and domains and finally learn a generalizable model across diverse tasks is a long-lasting challenge. Continual learning (CL) has emerged as a promising approach to leverage pre-trained models (e.g., Transformers) for sequential tasks. While many existing CL methods incrementally store additional learned structures, such as Low-Rank Adaptation (LoRA) adapters or prompts and sometimes even preserve features from previous samples to maintain performance. This leads to unsustainable parameter growth and escalating storage costs as the number of tasks increases. Moreover, current approaches often lack task similarity awareness, which further hinders the models ability to effectively adapt to new tasks without interfering with previously acquired knowledge. To address these challenges, we propose FM-LoRA, a novel and efficient low-rank adaptation method that integrates both a dynamic rank selector (DRS) and dynamic meta-prompting (DMP). This framework allocates model capacity more effectively across tasks by leveraging a shared low-rank subspace critical for preserving knowledge, thereby avoiding continual parameter expansion. Extensive experiments on various CL benchmarks, including ImageNet-R, CIFAR100, and CUB200 for class-incremental learning (CIL), and DomainNet for domain-incremental learning (DIL), with Transformers backbone demonstrate that FM-LoRA effectively mitigates catastrophic forgetting while delivering robust performance across a diverse range of tasks and domains.
RCCFormer: A Robust Crowd Counting Network Based on Transformer
Apr 07, 2025



Crowd counting, which is a key computer vision task, has emerged as a fundamental technology in crowd analysis and public safety management. However, challenges such as scale variations and complex backgrounds significantly impact the accuracy of crowd counting. To mitigate these issues, this paper proposes a robust Transformer-based crowd counting network, termed RCCFormer, specifically designed for background suppression and scale awareness. The proposed method incorporates a Multi-level Feature Fusion Module (MFFM), which meticulously integrates features extracted at diverse stages of the backbone architecture. It establishes a strong baseline capable of capturing intricate and comprehensive feature representations, surpassing traditional baselines. Furthermore, the introduced Detail-Embedded Attention Block (DEAB) captures contextual information and local details through global self-attention and local attention along with a learnable manner for efficient fusion. This enhances the model's ability to focus on foreground regions while effectively mitigating background noise interference. Additionally, we develop an Adaptive Scale-Aware Module (ASAM), with our novel Input-dependent Deformable Convolution (IDConv) as its fundamental building block. This module dynamically adapts to changes in head target shapes and scales, significantly improving the network's capability to accommodate large-scale variations. The effectiveness of the proposed method is validated on the ShanghaiTech Part_A and Part_B, NWPU-Crowd, and QNRF datasets. The results demonstrate that our RCCFormer achieves excellent performance across all four datasets, showcasing state-of-the-art outcomes.
Is Your Benchmark (Still) Useful? Dynamic Benchmarking for Code Language Models
Mar 09, 2025In this paper, we tackle a critical challenge in model evaluation: how to keep code benchmarks useful when models might have already seen them during training. We introduce a novel solution, dynamic benchmarking framework, to address this challenge. Given a code understanding or reasoning benchmark, our framework dynamically transforms each input, i.e., programs, with various semantic-preserving mutations to build a syntactically new while semantically identical benchmark. We evaluated ten popular language models on our dynamic benchmarks. Our evaluation reveals several interesting or surprising findings: (1) all models perform significantly worse than before, (2) the ranking between some models shifts dramatically, and (3) our dynamic benchmarks can resist against the data contamination problem.
Exploring Temporal Event Cues for Dense Video Captioning in Cyclic Co-learning
Dec 16, 2024



Dense video captioning aims to detect and describe all events in untrimmed videos. This paper presents a dense video captioning network called Multi-Concept Cyclic Learning (MCCL), which aims to: (1) detect multiple concepts at the frame level, using these concepts to enhance video features and provide temporal event cues; and (2) design cyclic co-learning between the generator and the localizer within the captioning network to promote semantic perception and event localization. Specifically, we perform weakly supervised concept detection for each frame, and the detected concept embeddings are integrated into the video features to provide event cues. Additionally, video-level concept contrastive learning is introduced to obtain more discriminative concept embeddings. In the captioning network, we establish a cyclic co-learning strategy where the generator guides the localizer for event localization through semantic matching, while the localizer enhances the generator's event semantic perception through location matching, making semantic perception and event localization mutually beneficial. MCCL achieves state-of-the-art performance on the ActivityNet Captions and YouCook2 datasets. Extensive experiments demonstrate its effectiveness and interpretability.
POPoS: Improving Efficient and Robust Facial Landmark Detection with Parallel Optimal Position Search
Oct 15, 2024



Achieving a balance between accuracy and efficiency is a critical challenge in facial landmark detection (FLD). This paper introduces the Parallel Optimal Position Search (POPoS), a high-precision encoding-decoding framework designed to address the fundamental limitations of traditional FLD methods. POPoS employs three key innovations: (1) Pseudo-range multilateration is utilized to correct heatmap errors, enhancing the precision of landmark localization. By integrating multiple anchor points, this approach minimizes the impact of individual heatmap inaccuracies, leading to robust overall positioning. (2) To improve the pseudo-range accuracy of selected anchor points, a new loss function, named multilateration anchor loss, is proposed. This loss function effectively enhances the accuracy of the distance map, mitigates the risk of local optima, and ensures optimal solutions. (3) A single-step parallel computation algorithm is introduced, significantly enhancing computational efficiency and reducing processing time. Comprehensive evaluations across five benchmark datasets demonstrate that POPoS consistently outperforms existing methods, particularly excelling in low-resolution scenarios with minimal computational overhead. These features establish POPoS as a highly efficient and accurate tool for FLD, with broad applicability in real-world scenarios. The code is available at https://github.com/teslatasy/PoPoS