 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Jailbreaking Strategies Based on the Semantic Understanding Capabilities of Large Language Models
May 29, 2025Adversarial attacks on Large Language Models (LLMs) via jailbreaking techniques-methods that circumvent their built-in safety and ethical constraints-have emerged as a critical challenge in AI security. These attacks compromise the reliability of LLMs by exploiting inherent weaknesses in their comprehension capabilities. This paper investigates the efficacy of jailbreaking strategies that are specifically adapted to the diverse levels of understanding exhibited by different LLMs. We propose the Adaptive Jailbreaking Strategies Based on the Semantic Understanding Capabilities of Large Language Models, a novel framework that classifies LLMs into Type I and Type II categories according to their semantic comprehension abilities. For each category, we design tailored jailbreaking strategies aimed at leveraging their vulnerabilities to facilitate successful attacks. Extensive experiments conducted on multiple LLMs demonstrate that our adaptive strategy markedly improves the success rate of jailbreaking. Notably, our approach achieves an exceptional 98.9% success rate in jailbreaking GPT-4o(29 May 2025 release)
Dual-View Pyramid Pooling in Deep Neural Networks for Improved Medical Image Classification and Confidence Calibration
Aug 06, 2024



Spatial pooling (SP) and cross-channel pooling (CCP) operators have been applied to aggregate spatial features and pixel-wise features from feature maps in deep neural networks (DNNs), respectively. Their main goal is to reduce computation and memory overhead without visibly weakening the performance of DNNs. However, SP often faces the problem of losing the subtle feature representations, while CCP has a high possibility of ignoring salient feature representations, which may lead to both miscalibration of confidence issues and suboptimal medical classification results. To address these problems, we propose a novel dual-view framework, the first to systematically investigate the relative roles of SP and CCP by analyzing the difference between spatial features and pixel-wise features. Based on this framework, we propose a new pooling method, termed dual-view pyramid pooling (DVPP), to aggregate multi-scale dual-view features. DVPP aims to boost both medical image classification and confidence calibration performance by fully leveraging the merits of SP and CCP operators from a dual-axis perspective. Additionally, we discuss how to fulfill DVPP with five parameter-free implementations. Extensive experiments on six 2D/3D medical image classification tasks show that our DVPP surpasses state-of-the-art pooling methods in terms of medical image classification results and confidence calibration across different DNNs.
Autism Spectrum Disorder Classification in Children based on Structural MRI Features Extracted using Contrastive Variational Autoencoder
Jul 03, 2023


Autism spectrum disorder (ASD) is a highly disabling mental disease that brings significant impairments of social interaction ability to the patients, making early screening and intervention of ASD critical. With the development of the machine learning and neuroimaging technology, extensive research has been conducted on machine classification of ASD based on structural MRI (s-MRI). However, most studies involve with datasets where participants' age are above 5. Few studies conduct machine classification of ASD for participants below 5-year-old, but, with mediocre predictive accuracy. In this paper, we push the boundary of predictive accuracy (above 0.97) of machine classification of ASD in children (age range: 0.92-4.83 years), based on s-MRI features extracted using contrastive variational autoencoder (CVAE). 78 s-MRI, collected from Shenzhen Children's Hospital, are used for training CVAE, which consists of both ASD-specific feature channel and common shared feature channel. The ASD participants represented by ASD-specific features can be easily discriminated from TC participants represented by the common shared features, leading to high classification accuracy. In case of degraded predictive accuracy when data size is extremely small, a transfer learning strategy is proposed here as a potential solution. Finally, we conduct neuroanatomical interpretation based on the correlation between s-MRI features extracted from CVAE and surface area of different cortical regions, which discloses potential biomarkers that could help target treatments of ASD in the future.
Meta-data Study in Autism Spectrum Disorder Classification Based on Structural MRI
Jun 09, 2022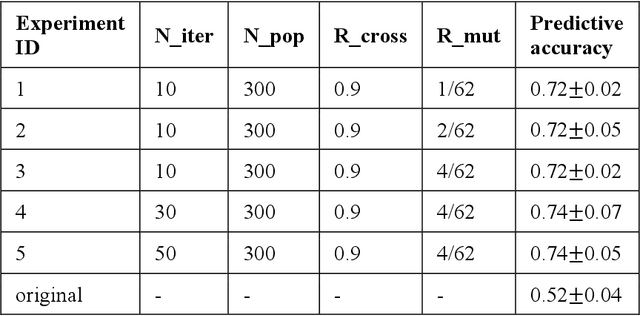
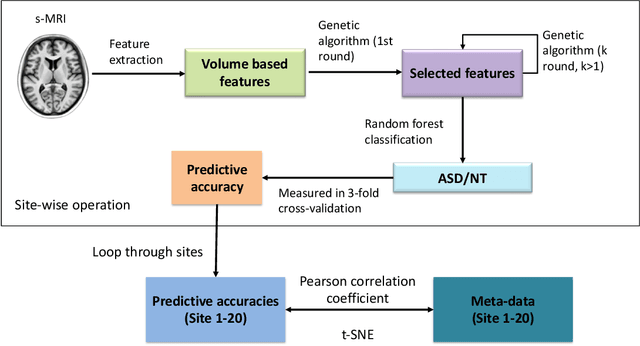
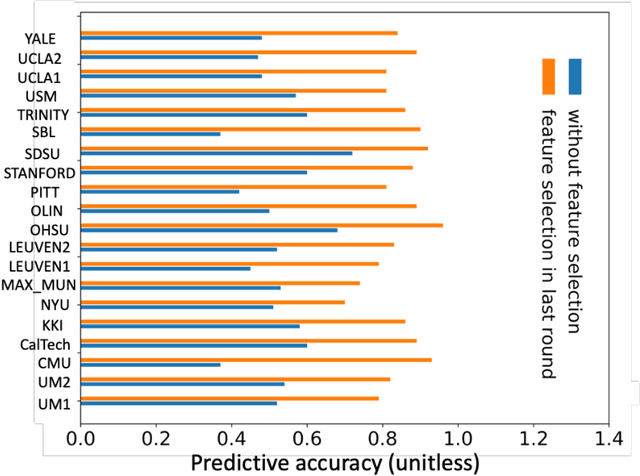
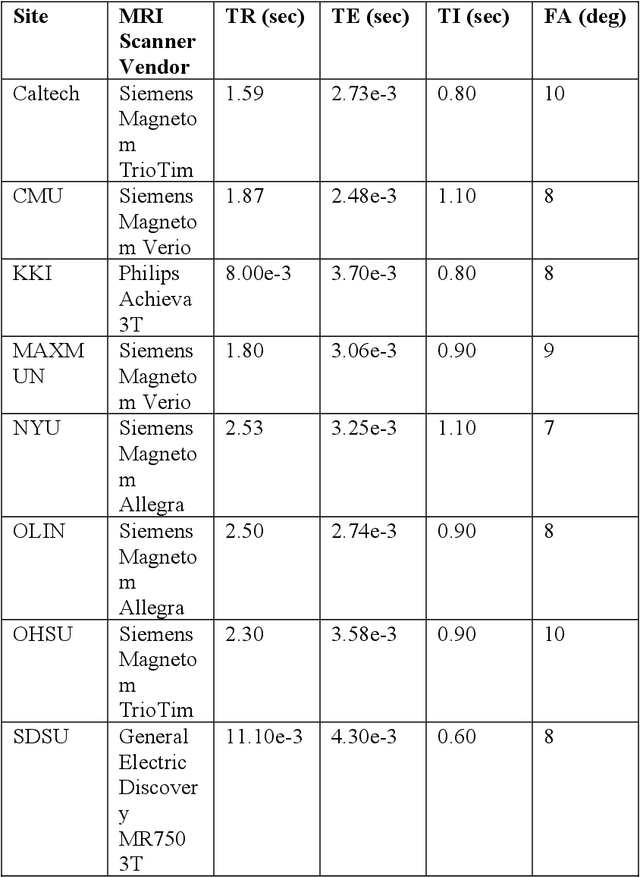
Accurate diagnosis of autism spectrum disorder (ASD) based on neuroimaging data has significant implications, as extracting useful information from neuroimaging data for ASD detection is challenging. Even though machine learning techniques have been leveraged to improve the information extraction from neuroimaging data, the varying data quality caused by different meta-data conditions (i.e., data collection strategies) limits the effective information that can be extracted, thus leading to data-dependent predictive accuracies in ASD detection, which can be worse than random guess in some cases. In this work, we systematically investigate the impact of three kinds of meta-data on the predictive accuracy of classifying ASD based on structural MRI collected from 20 different sites, where meta-data conditions vary.
Identification of Autism spectrum disorder based on a novel feature selection method and Variational Autoencoder
Apr 07, 2022
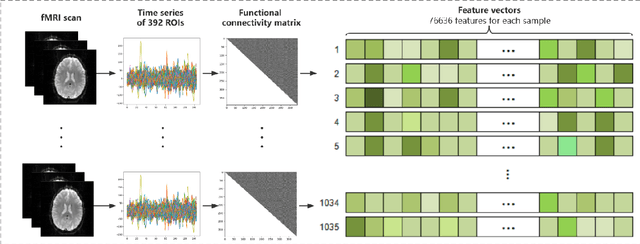
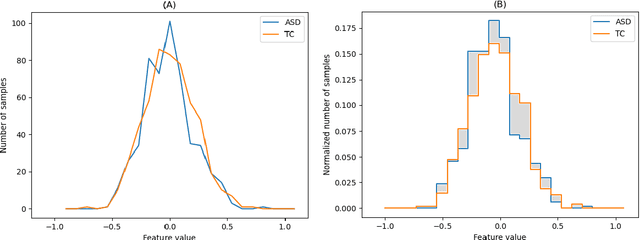
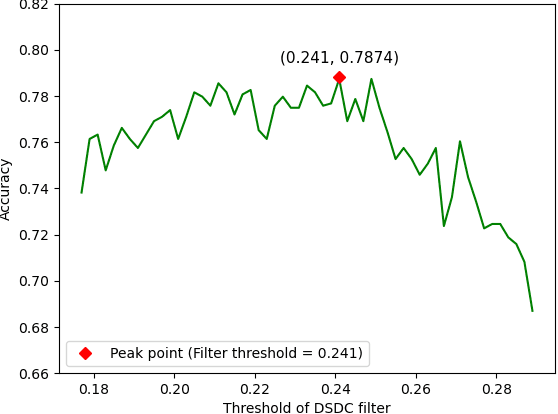
The development of noninvasive brain imaging such as resting-state functional magnetic resonance imaging (rs-fMRI) and its combination with AI algorithm provides a promising solution for the early diagnosis of Autism spectrum disorder (ASD). However, the performance of the current ASD classification based on rs-fMRI still needs to be improved. This paper introduces a classification framework to aid ASD diagnosis based on rs-fMRI. In the framework, we proposed a novel filter feature selection method based on the difference between step distribution curves (DSDC) to select remarkable functional connectivities (FCs) and utilized a multilayer perceptron (MLP) which was pretrained by a simplified Variational Autoencoder (VAE) for classification. We also designed a pipeline consisting of a normalization procedure and a modified hyperbolic tangent (tanh) activation function to replace the original tanh function, further improving the model accuracy. Our model was evaluated by 10 times 10-fold cross-validation and achieved an average accuracy of 78.12%, outperforming the state-of-the-art methods reported on the same dataset. Given the importance of sensitivity and specificity in disease diagnosis, two constraints were designed in our model which can improve the model's sensitivity and specificity by up to 9.32% and 10.21%, respectively. The added constraints allow our model to handle different application scenarios and can be used broadly.
Autoregressive-Model-Based Methods for Online Time Series Prediction with Missing Values: an Experimental Evaluation
Aug 27, 2019



Time series prediction with missing values is an important problem of time series analysis since complete data is usually hard to obtain in many real-world applications. To model the generation of time series, autoregressive (AR) model is a basic and widely used one, which assumes that each observation in the time series is a noisy linear combination of some previous observations along with a constant shift. To tackle the problem of prediction with missing values, a number of methods were proposed based on various data models. For real application scenarios, how do these methods perform over different types of time series with different levels of data missing remains to be investigated. In this paper, we focus on online methods for AR-model-based time series prediction with missing values. We adapted five mainstream methods to fit in such a scenario. We make detailed discussion on each of them by introducing their core ideas about how to estimate the AR coefficients and their different strategies to deal with missing values. We also present algorithmic implementations for better understanding. In order to comprehensively evaluate these methods and do the comparison, we conduct experiments with various configurations of relative parameters over both synthetic and real data. From the experimental results, we derived several noteworthy conclusions and shows that imputation is a simple but reliable strategy to handle missing values in online prediction tasks.