 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Temporal Event Cues for Dense Video Captioning in Cyclic Co-learning
Dec 16, 2024



Dense video captioning aims to detect and describe all events in untrimmed videos. This paper presents a dense video captioning network called Multi-Concept Cyclic Learning (MCCL), which aims to: (1) detect multiple concepts at the frame level, using these concepts to enhance video features and provide temporal event cues; and (2) design cyclic co-learning between the generator and the localizer within the captioning network to promote semantic perception and event localization. Specifically, we perform weakly supervised concept detection for each frame, and the detected concept embeddings are integrated into the video features to provide event cues. Additionally, video-level concept contrastive learning is introduced to obtain more discriminative concept embeddings. In the captioning network, we establish a cyclic co-learning strategy where the generator guides the localizer for event localization through semantic matching, while the localizer enhances the generator's event semantic perception through location matching, making semantic perception and event localization mutually beneficial. MCCL achieves state-of-the-art performance on the ActivityNet Captions and YouCook2 datasets. Extensive experiments demonstrate its effectiveness and interpretability.
Trustworthy Multimodal Fusion for Sentiment Analysis in Ordinal Sentiment Space
Apr 13, 2024Multimodal video sentiment analysis aims to integrate multiple modal information to analyze the opinions and attitudes of speakers. Most previous work focuses on exploring the semantic interactions of intra- and inter-modality. However, these works ignore the reliability of multimodality, i.e., modalities tend to contain noise, semantic ambiguity, missing modalities, etc. In addition, previous multimodal approaches treat different modalities equally, largely ignoring their different contributions. Furthermore, existing multimodal sentiment analysis methods directly regress sentiment scores without considering ordinal relationships within sentiment categories, with limited performance. To address the aforementioned problems, we propose a trustworthy multimodal sentiment ordinal network (TMSON) to improve performance in sentiment analysis. Specifically, we first devise a unimodal feature extractor for each modality to obtain modality-specific features. Then, an uncertainty distribution estimation network is customized, which estimates the unimodal uncertainty distributions. Next, Bayesian fusion is performed on the learned unimodal distributions to obtain multimodal distributions for sentiment prediction. Finally, an ordinal-aware sentiment space is constructed, where ordinal regression is used to constrain the multimodal distributions. Our proposed TMSON outperforms baselines on multimodal sentiment analysis tasks, and empirical results demonstrate that TMSON is capable of reducing uncertainty to obtain more robust predictions.
USL-Net: Uncertainty Self-Learning Network for Unsupervised Skin Lesion Segmentation
Sep 23, 2023Unsupervised skin lesion segmentation offers several benefits, including conserving expert human resources, reducing discrepancies due to subjective human labeling, and adapting to novel environments. However, segmenting dermoscopic images without manual labeling guidance presents significant challenges due to dermoscopic image artifacts such as hair noise, blister noise, and subtle edge differences. To address these challenges, we introduce an innovative Uncertainty Self-Learning Network (USL-Net) designed for skin lesion segmentation. The USL-Net can effectively segment a range of lesions, eliminating the need for manual labeling guidance. Initially, features are extracted using contrastive learning, followed by the generation of Class Activation Maps (CAMs) as saliency maps using these features. The different CAM locations correspond to the importance of the lesion region based on their saliency. High-saliency regions in the map serve as pseudo-labels for lesion regions while low-saliency regions represent the background. However, intermediate regions can be hard to classify, often due to their proximity to lesion edges or interference from hair or blisters. Rather than risk potential pseudo-labeling errors or learning confusion by forcefully classifying these regions, we consider them as uncertainty regions, exempting them from pseudo-labeling and allowing the network to self-learn. Further, we employ connectivity detection and centrality detection to refine foreground pseudo-labels and reduce noise-induced errors. The application of cycle refining enhances performance further. Our method underwent thorough experimental validation on the ISIC-2017, ISIC-2018, and PH2 datasets, demonstrating that its performance is on par with weakly supervised and supervised methods, and exceeds that of other existing unsupervised methods.
Point Clouds Learning with Attention-based Graph Convolution Networks
May 31, 2019
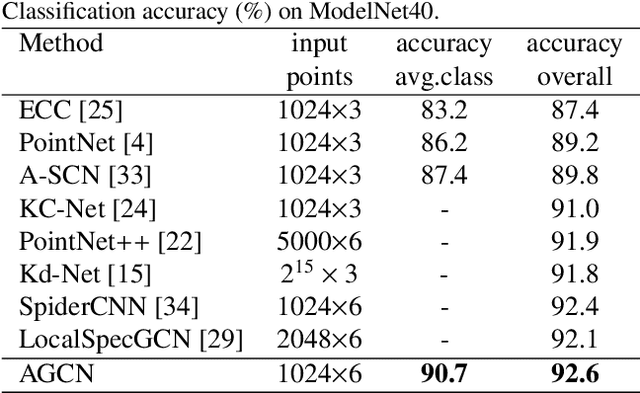
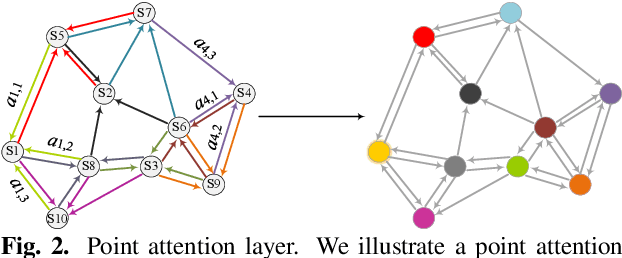
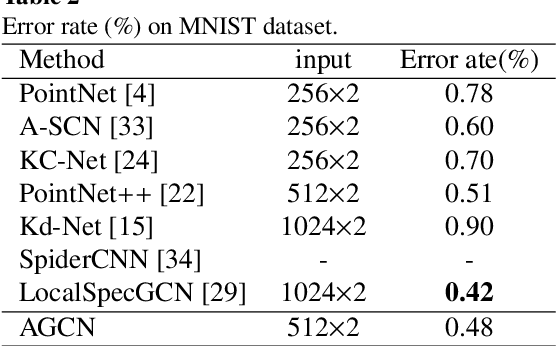
Point clouds data, as one kind of representation of 3D objects, are the most primitive output obtained by 3D sensors. Unlike 2D images, point clouds are disordered and unstructured. Hence it is not straightforward to apply classification techniques such as the convolution neural network to point clouds analysis directly. To solve this problem, we propose a novel network structure, named Attention-based Graph Convolution Networks (AGCN), to extract point clouds features. Taking the learning process as a message propagation between adjacent points, we introduce an attention mechanism to AGCN for analyzing the relationships between local features of the points. In addition, we introduce an additional global graph structure network to compensate for the relative information of the individual points in the graph structure network. The proposed network is also extended to an encoder-decoder structure for segmentation tasks. Experimental results show that the proposed network can achieve state-of-the-art performance in both classification and segmentation tasks.