 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Your Benchmark (Still) Useful? Dynamic Benchmarking for Code Language Models
Mar 09, 2025In this paper, we tackle a critical challenge in model evaluation: how to keep code benchmarks useful when models might have already seen them during training. We introduce a novel solution, dynamic benchmarking framework, to address this challenge. Given a code understanding or reasoning benchmark, our framework dynamically transforms each input, i.e., programs, with various semantic-preserving mutations to build a syntactically new while semantically identical benchmark. We evaluated ten popular language models on our dynamic benchmarks. Our evaluation reveals several interesting or surprising findings: (1) all models perform significantly worse than before, (2) the ranking between some models shifts dramatically, and (3) our dynamic benchmarks can resist against the data contamination problem.
Eliminating Information Leakage in Hard Concept Bottleneck Models with Supervised, Hierarchical Concept Learning
Feb 03, 2024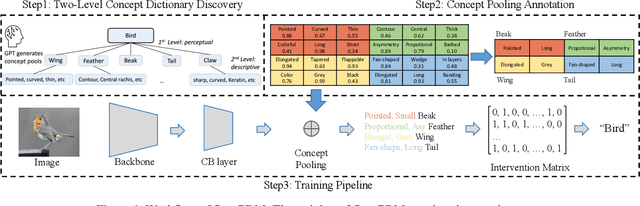
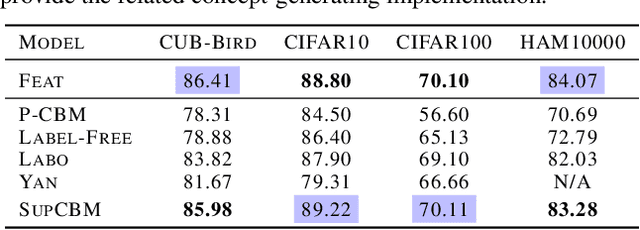
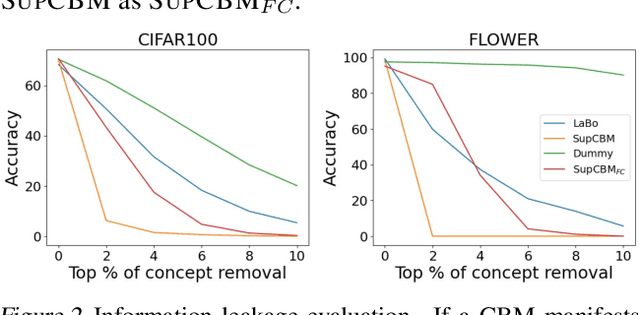

Concept Bottleneck Models (CBMs) aim to deliver interpretable and interventionable predictions by bridging features and labels with human-understandable concepts. While recent CBMs show promising potential, they suffer from information leakage, where unintended information beyond the concepts (either when concepts are represented with probabilities or binary states) are leaked to the subsequent label prediction. Consequently, distinct classes are falsely classified via indistinguishable concepts, undermining the interpretation and intervention of CBMs. This paper alleviates the information leakage issue by introducing label supervision in concept predication and constructing a hierarchical concept set. Accordingly, we propose a new paradigm of CBMs, namely SupCBM, which achieves label predication via predicted concepts and a deliberately-designed intervention matrix. SupCBM focuses on concepts that are mostly relevant to the predicted label and only distinguishes classes when different concepts are presented. Our evaluations show that SupCBM outperforms SOTA CBMs over diverse datasets. It also manifests better generality across different backbone models. With proper quantification of information leakage in different CBMs, we demonstrate that SupCBM significantly reduces the information leakage.
No Privacy Left Outside: On the Security of TEE-Shielded DNN Partition for On-Device ML
Oct 11, 2023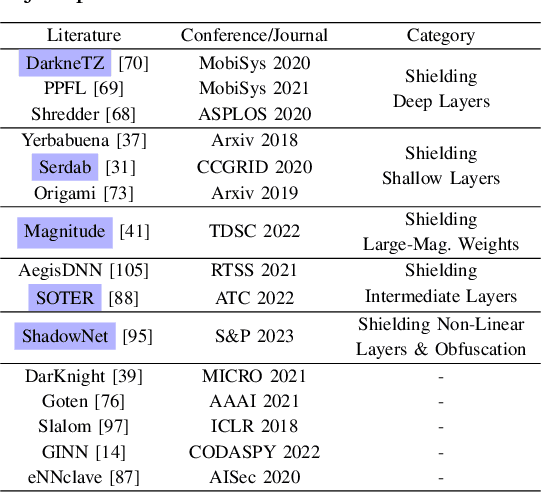
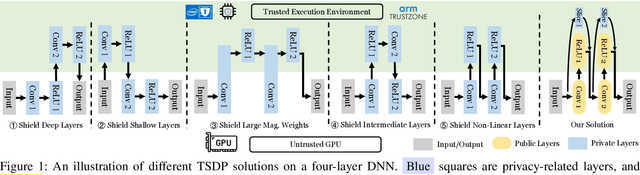
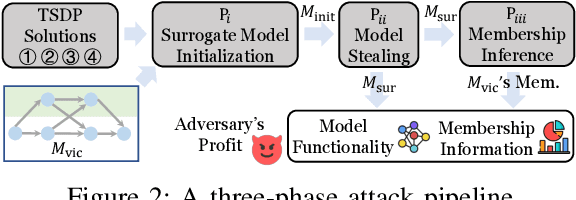
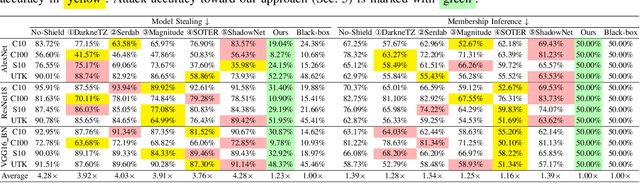
On-device ML introduces new security challenges: DNN models become white-box accessible to device users. Based on white-box information, adversaries can conduct effective model stealing (MS) and membership inference attack (MIA). Using Trusted Execution Environments (TEEs) to shield on-device DNN models aims to downgrade (easy) white-box attacks to (harder) black-box attacks. However, one major shortcoming is the sharply increased latency (up to 50X). To accelerate TEE-shield DNN computation with GPUs, researchers proposed several model partition techniques. These solutions, referred to as TEE-Shielded DNN Partition (TSDP), partition a DNN model into two parts, offloading the privacy-insensitive part to the GPU while shielding the privacy-sensitive part within the TEE. This paper benchmarks existing TSDP solutions using both MS and MIA across a variety of DNN models, datasets, and metrics. We show important findings that existing TSDP solutions are vulnerable to privacy-stealing attacks and are not as safe as commonly believed. We also unveil the inherent difficulty in deciding optimal DNN partition configurations (i.e., the highest security with minimal utility cost) for present TSDP solutions. The experiments show that such ``sweet spot'' configurations vary across datasets and models. Based on lessons harvested from the experiments, we present TEESlice, a novel TSDP method that defends against MS and MIA during DNN inference. TEESlice follows a partition-before-training strategy, which allows for accurate separation between privacy-related weights from public weights. TEESlice delivers the same security protection as shielding the entire DNN model inside TEE (the ``upper-bound'' security guarantees) with over 10X less overhead (in both experimental and real-world environments) than prior TSDP solutions and no accuracy loss.
Unveiling Signle-Bit-Flip Attacks on DNN Executables
Sep 12, 2023Recent research has shown that bit-flip attacks (BFAs) can manipulate deep neural networks (DNNs) via DRAM Rowhammer exploitations. Existing attacks are primarily launched over high-level DNN frameworks like PyTorch and flip bits in model weight files. Nevertheless, DNNs are frequently compiled into low-level executables by deep learning (DL) compilers to fully leverage low-level hardware primitives. The compiled code is usually high-speed and manifests dramatically distinct execution paradigms from high-level DNN frameworks. In this paper, we launch the first systematic study on the attack surface of BFA specifically for DNN executables compiled by DL compilers. We design an automated search tool to identify vulnerable bits in DNN executables and identify practical attack vectors that exploit the model structure in DNN executables with BFAs (whereas prior works make likely strong assumptions to attack model weights). DNN executables appear more "opaque" than models in high-level DNN frameworks. Nevertheless, we find that DNN executables contain extensive, severe (e.g., single-bit flip), and transferrable attack surfaces that are not present in high-level DNN models and can be exploited to deplete full model intelligence and control output labels. Our finding calls for incorporating security mechanisms in future DNN compilation toolchains.
Precise and Generalized Robustness Certification for Neural Networks
Jun 11, 2023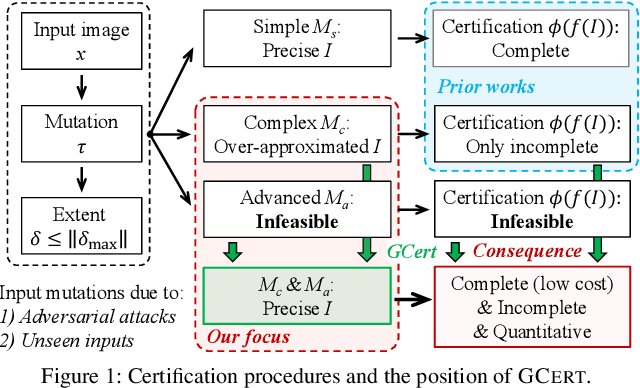
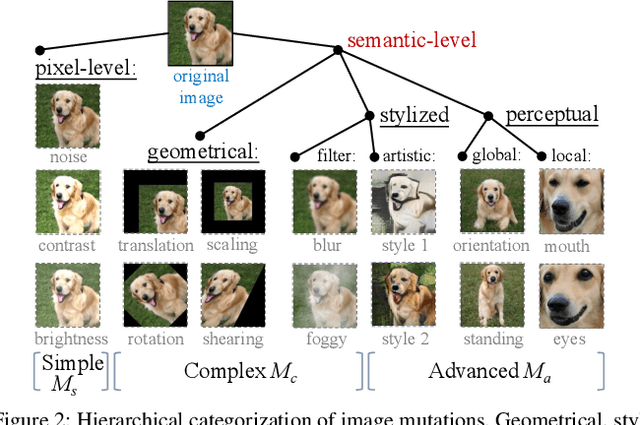
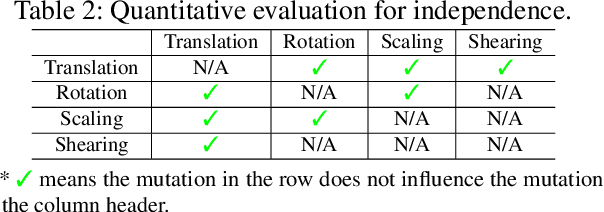
The objective of neural network (NN) robustness certification is to determine if a NN changes its predictions when mutations are made to its inputs. While most certification research studies pixel-level or a few geometrical-level and blurring operations over images, this paper proposes a novel framework, GCERT, which certifies NN robustness under a precise and unified form of diverse semantic-level image mutations. We formulate a comprehensive set of semantic-level image mutations uniformly as certain directions in the latent space of generative models. We identify two key properties, independence and continuity, that convert the latent space into a precise and analysis-friendly input space representation for certification. GCERT can be smoothly integrated with de facto complete, incomplete, or quantitative certification frameworks. With its precise input space representation, GCERT enables for the first time complete NN robustness certification with moderate cost under diverse semantic-level input mutations, such as weather-filter, style transfer, and perceptual changes (e.g., opening/closing eyes). We show that GCERT enables certifying NN robustness under various common and security-sensitive scenarios like autonomous driving.
Explain Any Concept: Segment Anything Meets Concept-Based Explanation
May 17, 2023EXplainable AI (XAI) is an essential topic to improve human understanding of deep neural networks (DNNs) given their black-box internals. For computer vision tasks, mainstream pixel-based XAI methods explain DNN decisions by identifying important pixels, and emerging concept-based XAI explore forming explanations with concepts (e.g., a head in an image). However, pixels are generally hard to interpret and sensitive to the imprecision of XAI methods, whereas "concepts" in prior works require human annotation or are limited to pre-defined concept sets. On the other hand, driven by large-scale pre-training, Segment Anything Model (SAM) has been demonstrated as a powerful and promotable framework for performing precise and comprehensive instance segmentation, enabling automatic preparation of concept sets from a given image. This paper for the first time explores using SAM to augment concept-based XAI. We offer an effective and flexible concept-based explanation method, namely Explain Any Concept (EAC), which explains DNN decisions with any concept. While SAM is highly effective and offers an "out-of-the-box" instance segmentation, it is costly when being integrated into defacto XAI pipelines. We thus propose a lightweight per-input equivalent (PIE) scheme, enabling efficient explanation with a surrogate model. Our evaluation over two popular datasets (ImageNet and COCO) illustrate the highly encouraging performance of EAC over commonly-used XAI methods.
Decompiling x86 Deep Neural Network Executables
Oct 04, 2022
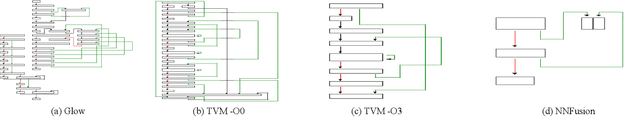
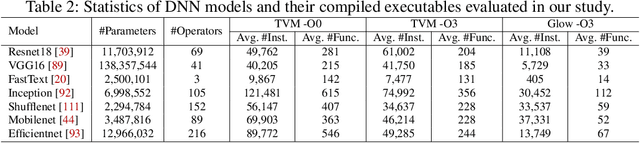
Due to their widespread use on heterogeneous hardware devices, deep learning (DL) models are compiled into executables by DL compilers to fully leverage low-level hardware primitives. This approach allows DL computations to be undertaken at low cost across a variety of computing platforms, including CPUs, GPUs, and various hardware accelerators. We present BTD (Bin to DNN), a decompiler for deep neural network (DNN) executables. BTD takes DNN executables and outputs full model specifications, including types of DNN operators, network topology, dimensions, and parameters that are (nearly) identical to those of the input models. BTD delivers a practical framework to process DNN executables compiled by different DL compilers and with full optimizations enabled on x86 platforms. It employs learning-based techniques to infer DNN operators, dynamic analysis to reveal network architectures, and symbolic execution to facilitate inferring dimensions and parameters of DNN operators. Our evaluation reveals that BTD enables accurate recovery of full specifications of complex DNNs with millions of parameters (e.g., ResNet). The recovered DNN specifications can be re-compiled into a new DNN executable exhibiting identical behavior to the input executable. We show that BTD can boost two representative attacks, adversarial example generation and knowledge stealing, against DNN executables. We also demonstrate cross-architecture legacy code reuse using BTD, and envision BTD being used for other critical downstream tasks like DNN security hardening and patching.
Attacking Vertical Collaborative Learning System Using Adversarial Dominating Inputs
Jan 08, 2022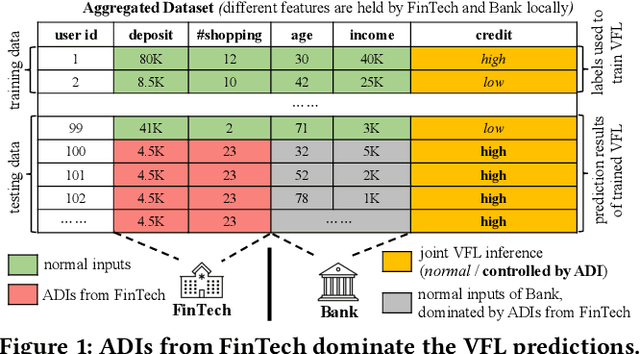
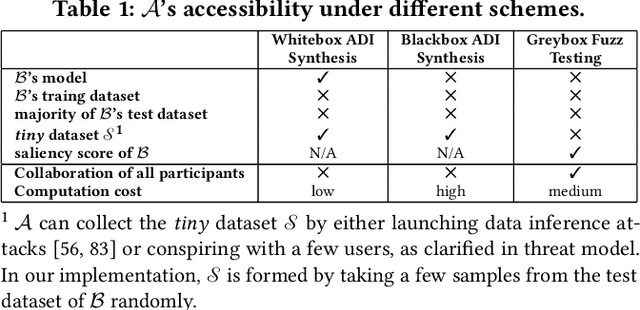
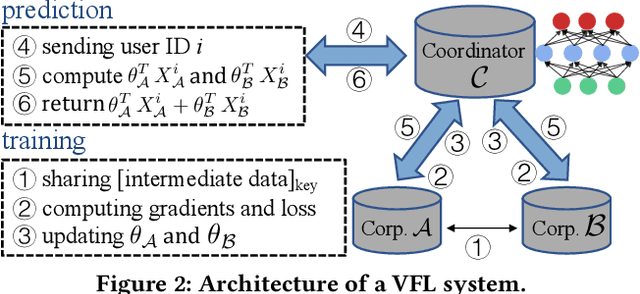

Vertical collaborative learning system also known as vertical federated learning (VFL) system has recently become prominent as a concept to process data distributed across many individual sources without the need to centralize it. Multiple participants collaboratively train models based on their local data in a privacy-preserving manner. To date, VFL has become a de facto solution to securely learn a model among organizations, allowing knowledge to be shared without compromising privacy of any individual organizations. Despite the prosperous development of VFL systems, we find that certain inputs of a participant, named adversarial dominating inputs (ADIs), can dominate the joint inference towards the direction of the adversary's will and force other (victim) participants to make negligible contributions, losing rewards that are usually offered regarding the importance of their contributions in collaborative learning scenarios. We conduct a systematic study on ADIs by first proving their existence in typical VFL systems. We then propose gradient-based methods to synthesize ADIs of various formats and exploit common VFL systems. We further launch greybox fuzz testing, guided by the resiliency score of "victim" participants, to perturb adversary-controlled inputs and systematically explore the VFL attack surface in a privacy-preserving manner. We conduct an in-depth study on the influence of critical parameters and settings in synthesizing ADIs. Our study reveals new VFL attack opportunities, promoting the identification of unknown threats before breaches and building more secure VFL systems.
MDPFuzzer: Finding Crash-Triggering State Sequences in Models Solving the Markov Decision Process
Dec 12, 2021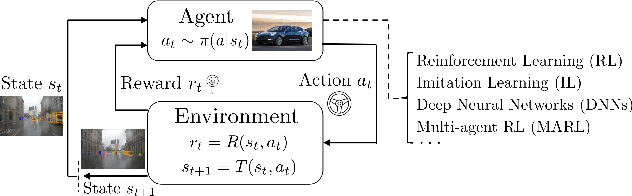
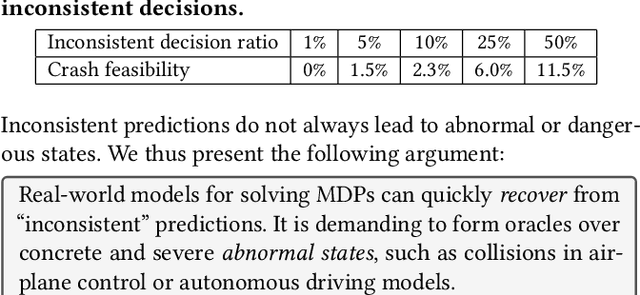


The Markov decision process (MDP) provides a mathematical framework for modeling sequential decision-making problems, many of which are crucial to security and safety, such as autonomous driving and robot control. The rapid development of artificial intelligence research has created efficient methods for solving MDPs, such as deep neural networks (DNNs), reinforcement learning (RL), and imitation learning (IL). However, these popular models for solving MDPs are neither thoroughly tested nor rigorously reliable. We present MDPFuzzer, the first blackbox fuzz testing framework for models solving MDPs. MDPFuzzer forms testing oracles by checking whether the target model enters abnormal and dangerous states. During fuzzing, MDPFuzzer decides which mutated state to retain by measuring if it can reduce cumulative rewards or form a new state sequence. We design efficient techniques to quantify the "freshness" of a state sequence using Gaussian mixture models (GMMs) and dynamic expectation-maximization (DynEM). We also prioritize states with high potential of revealing crashes by estimating the local sensitivity of target models over states. MDPFuzzer is evaluated on five state-of-the-art models for solving MDPs, including supervised DNN, RL, IL, and multi-agent RL. Our evaluation includes scenarios of autonomous driving, aircraft collision avoidance, and two games that are often used to benchmark RL. During a 12-hour run, we find over 80 crash-triggering state sequences on each model. We show inspiring findings that crash-triggering states, though look normal, induce distinct neuron activation patterns compared with normal states. We further develop an abnormal behavior detector to harden all the evaluated models and repair them with the findings of MDPFuzzer to significantly enhance their robustness without sacrificing accuracy.
Automated Side Channel Analysis of Media Software with Manifold Learning
Dec 10, 2021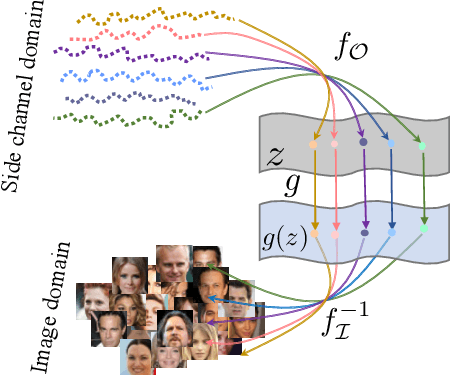

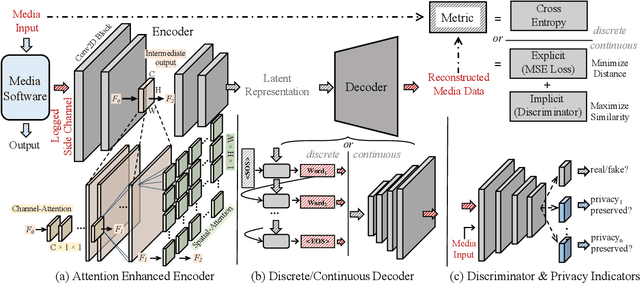

The prosperous development of cloud computing and machine learning as a service has led to the widespread use of media software to process confidential media data. This paper explores an adversary's ability to launch side channel analyses (SCA) against media software to reconstruct confidential media inputs. Recent advances in representation learning and perceptual learning inspired us to consider the reconstruction of media inputs from side channel traces as a cross-modality manifold learning task that can be addressed in a unified manner with an autoencoder framework trained to learn the mapping between media inputs and side channel observations. We further enhance the autoencoder with attention to localize the program points that make the primary contribution to SCA, thus automatically pinpointing information-leakage points in media software. We also propose a novel and highly effective defensive technique called perception blinding that can perturb media inputs with perception masks and mitigate manifold learning-based SCA. Our evaluation exploits three popular media software to reconstruct inputs in image, audio, and text formats. We analyze three common side channels - cache bank, cache line, and page tables - and userspace-only cache set accesses logged by standard Prime+Probe. Our framework successfully reconstructs high-quality confidential inputs from the assessed media software and automatically pinpoint their vulnerable program points, many of which are unknown to the public. We further show that perception blinding can mitigate manifold learning-based SCA with negligible extra cost.