 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMelodia: Training-Free Music Editing Guided by Attention Probing in Diffusion Models
Nov 18, 2025



Text-to-music generation technology is progressing rapidly, creating new opportunities for musical composition and editing. However, existing music editing methods often fail to preserve the source music's temporal structure, including melody and rhythm, when altering particular attributes like instrument, genre, and mood. To address this challenge, this paper conducts an in-depth probing analysis on attention maps within AudioLDM 2, a diffusion-based model commonly used as the backbone for existing music editing methods. We reveal a key finding: cross-attention maps encompass details regarding distinct musical characteristics, and interventions on these maps frequently result in ineffective modifications. In contrast, self-attention maps are essential for preserving the temporal structure of the source music during its conversion into the target music. Building upon this understanding, we present Melodia, a training-free technique that selectively manipulates self-attention maps in particular layers during the denoising process and leverages an attention repository to store source music information, achieving accurate modification of musical characteristics while preserving the original structure without requiring textual descriptions of the source music. Additionally, we propose two novel metrics to better evaluate music editing methods. Both objective and subjective experiments demonstrate that our approach achieves superior results in terms of textual adherence and structural integrity across various datasets. This research enhances comprehension of internal mechanisms within music generation models and provides improved control for music creation.
Enhancing IoT Communication and Localization via Smarter Antenna
Oct 15, 2024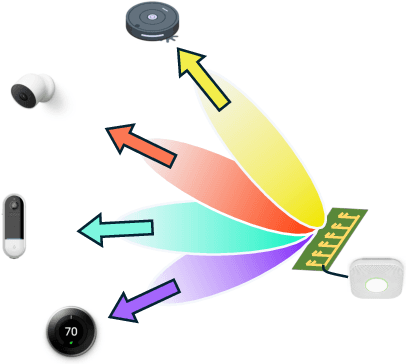
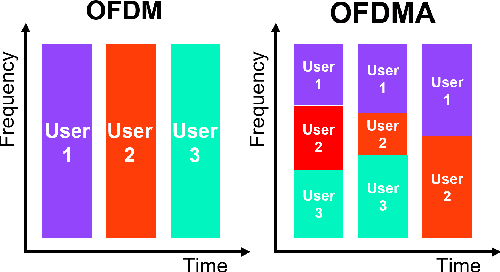
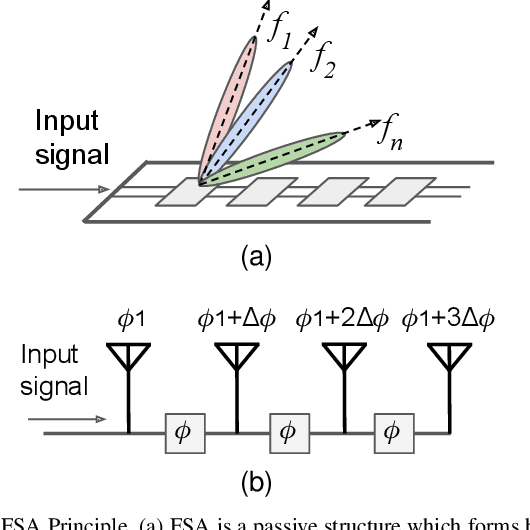
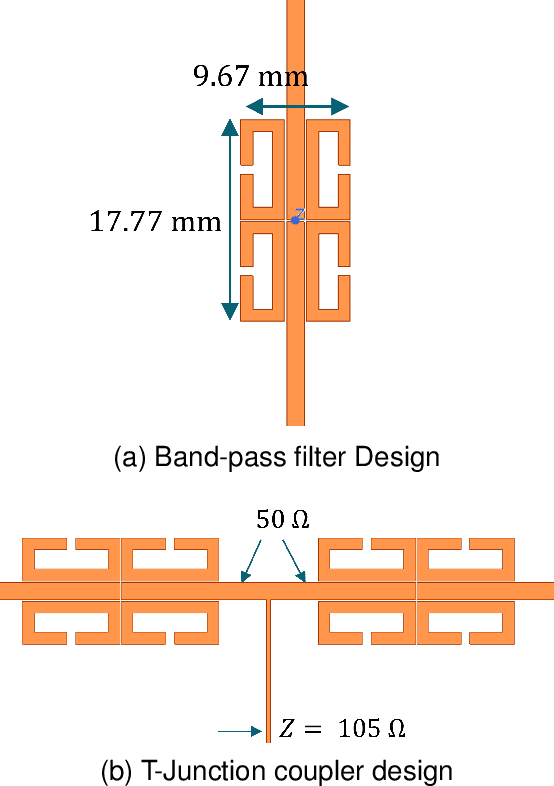
The convergence of sensing and communication functionalities is poised to become a pivotal feature of the sixth-generation (6G) wireless networks. This vision represents a paradigm shift in wireless network design, moving beyond mere communication to a holistic integration of sensing and communication capabilities, thereby further narrowing the gap between the physical and digital worlds. While Internet of Things (IoT) devices are integral to future wireless networks, their current capabilities in sensing and communication are constrained by their power and resource limitations. On one hand, their restricted power budget limits their transmission power, leading to reduced communication range and data rates. On the other hand, their limited hardware and processing abilities hinder the adoption of sophisticated sensing technologies, such as direction finding and localization. In this work, we introduce Wi-Pro, a system which seamlessly integrates today's WiFi protocol with smart antenna design to enhance the communication and sensing capabilities of existing IoT devices. This plug-and-play system can be easily installed by replacing the IoT device's antenna. Wi-Pro seamlessly integrates smart antenna hardware with current WiFi protocols, utilizing their inherent features to not only enhance communication but also to enable precise localization on low-cost IoT devices. Our evaluation results demonstrate that Wi-Pro achieves up to 150\% data rate improvement, up to five times range improvement, accurate direction finding, and localization on single-chain IoT devices.
Unveiling Signle-Bit-Flip Attacks on DNN Executables
Sep 12, 2023Recent research has shown that bit-flip attacks (BFAs) can manipulate deep neural networks (DNNs) via DRAM Rowhammer exploitations. Existing attacks are primarily launched over high-level DNN frameworks like PyTorch and flip bits in model weight files. Nevertheless, DNNs are frequently compiled into low-level executables by deep learning (DL) compilers to fully leverage low-level hardware primitives. The compiled code is usually high-speed and manifests dramatically distinct execution paradigms from high-level DNN frameworks. In this paper, we launch the first systematic study on the attack surface of BFA specifically for DNN executables compiled by DL compilers. We design an automated search tool to identify vulnerable bits in DNN executables and identify practical attack vectors that exploit the model structure in DNN executables with BFAs (whereas prior works make likely strong assumptions to attack model weights). DNN executables appear more "opaque" than models in high-level DNN frameworks. Nevertheless, we find that DNN executables contain extensive, severe (e.g., single-bit flip), and transferrable attack surfaces that are not present in high-level DNN models and can be exploited to deplete full model intelligence and control output labels. Our finding calls for incorporating security mechanisms in future DNN compilation toolchains.
MISSRec: Pre-training and Transferring Multi-modal Interest-aware Sequence Representation for Recommendation
Aug 22, 2023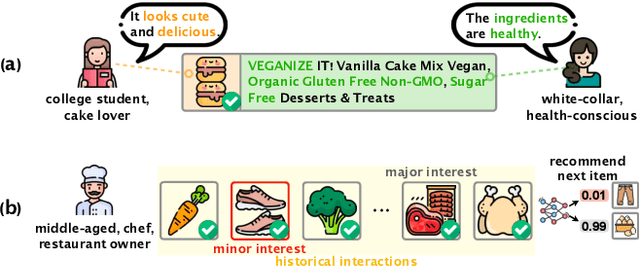

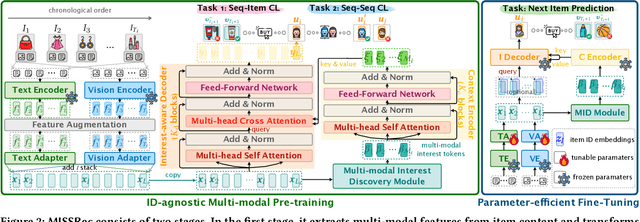

The goal of sequential recommendation (SR) is to predict a user's potential interested items based on her/his historical interaction sequences. Most existing sequential recommenders are developed based on ID features, which, despite their widespread use, often underperform with sparse IDs and struggle with the cold-start problem. Besides, inconsistent ID mappings hinder the model's transferability, isolating similar recommendation domains that could have been co-optimized. This paper aims to address these issues by exploring the potential of multi-modal information in learning robust and generalizable sequence representations. We propose MISSRec, a multi-modal pre-training and transfer learning framework for SR. On the user side, we design a Transformer-based encoder-decoder model, where the contextual encoder learns to capture the sequence-level multi-modal synergy while a novel interest-aware decoder is developed to grasp item-modality-interest relations for better sequence representation. On the candidate item side, we adopt a dynamic fusion module to produce user-adaptive item representation, providing more precise matching between users and items. We pre-train the model with contrastive learning objectives and fine-tune it in an efficient manner. Extensive experiments demonstrate the effectiveness and flexibility of MISSRec, promising an practical solution for real-world recommendation scenarios.
New Adversarial Image Detection Based on Sentiment Analysis
May 03, 2023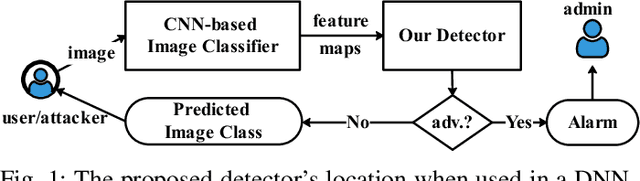
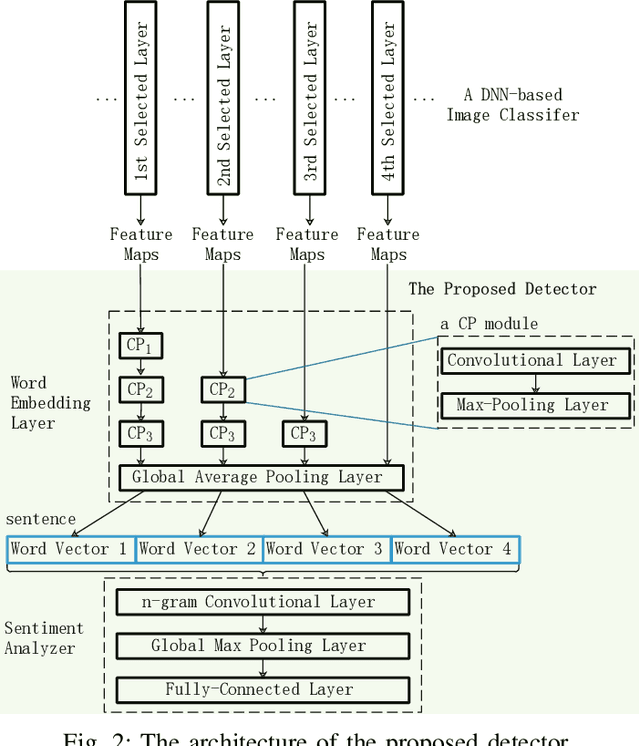
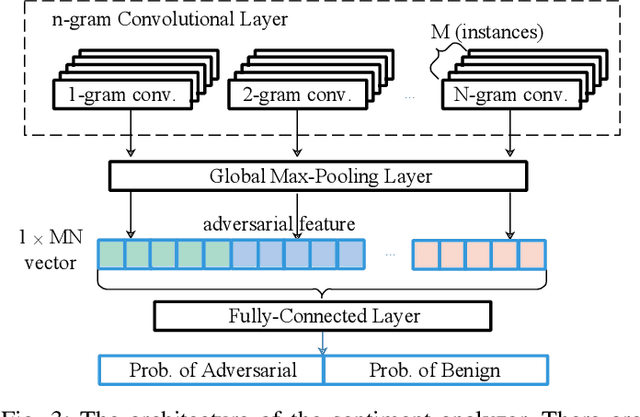

Deep Neural Networks (DNNs) are vulnerable to adversarial examples, while adversarial attack models, e.g., DeepFool, are on the rise and outrunning adversarial example detection techniques. This paper presents a new adversarial example detector that outperforms state-of-the-art detectors in identifying the latest adversarial attacks on image datasets. Specifically, we propose to use sentiment analysis for adversarial example detection, qualified by the progressively manifesting impact of an adversarial perturbation on the hidden-layer feature maps of a DNN under attack. Accordingly, we design a modularized embedding layer with the minimum learnable parameters to embed the hidden-layer feature maps into word vectors and assemble sentences ready for sentiment analysis. Extensive experiments demonstrate that the new detector consistently surpasses the state-of-the-art detection algorithms in detecting the latest attacks launched against ResNet and Inception neutral networks on the CIFAR-10, CIFAR-100 and SVHN datasets. The detector only has about 2 million parameters, and takes shorter than 4.6 milliseconds to detect an adversarial example generated by the latest attack models using a Tesla K80 GPU card.
Towards Mitigating the Problem of Insufficient and Ambiguous Supervision in Online Crowdsourcing Annotation
Oct 20, 2022
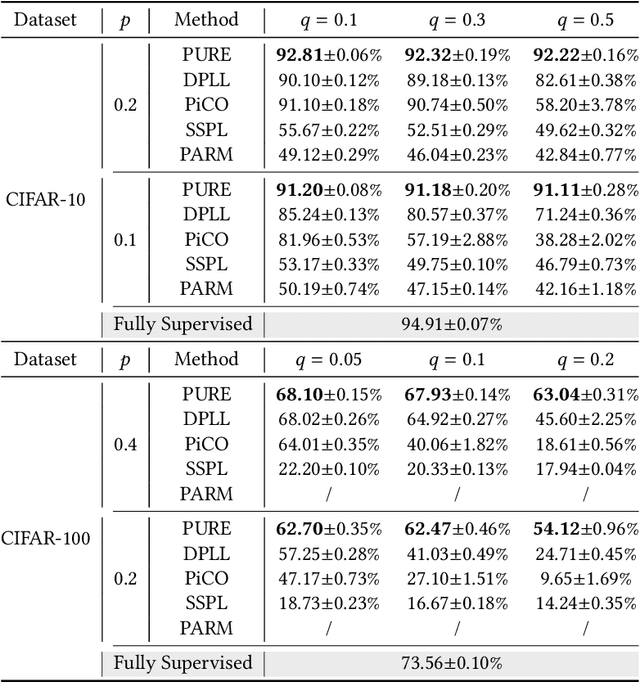

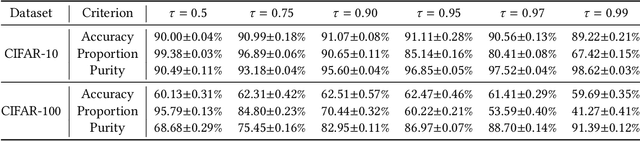
In real-world crowdsourcing annotation systems, due to differences in user knowledge and cultural backgrounds, as well as the high cost of acquiring annotation information, the supervision information we obtain might be insufficient and ambiguous. To mitigate the negative impacts, in this paper, we investigate a more general and broadly applicable learning problem, i.e. \emph{semi-supervised partial label learning}, and propose a novel method based on pseudo-labeling and contrastive learning. Following the key inventing principle, our method facilitate the partial label disambiguation process with unlabeled data and at the same time assign reliable pseudo-labels to weakly supervised examples. Specifically, our method learns from the ambiguous labeling information via partial cross-entropy loss. Meanwhile, high-accuracy pseudo-labels are generated for both partial and unlabeled examples through confidence-based thresholding and contrastive learning is performed in a hybrid unsupervised and supervised manner for more discriminative representations, while its supervision increases curriculumly. The two main components systematically work as a whole and reciprocate each other. In experiments, our method consistently outperforms all comparing methods by a significant margin and set up the first state-of-the-art performance for semi-supervised partial label learning on image benchmarks.
Differentiable Soft Quantization: Bridging Full-Precision and Low-Bit Neural Networks
Aug 14, 2019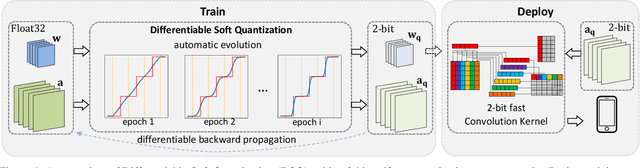
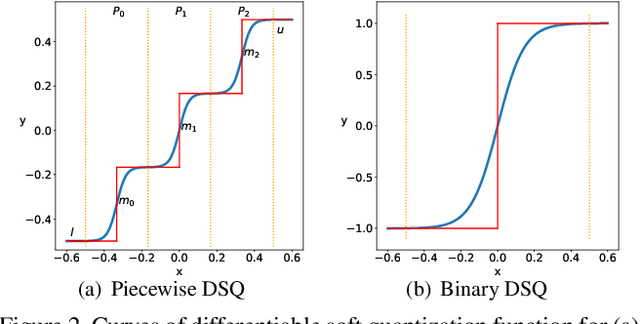
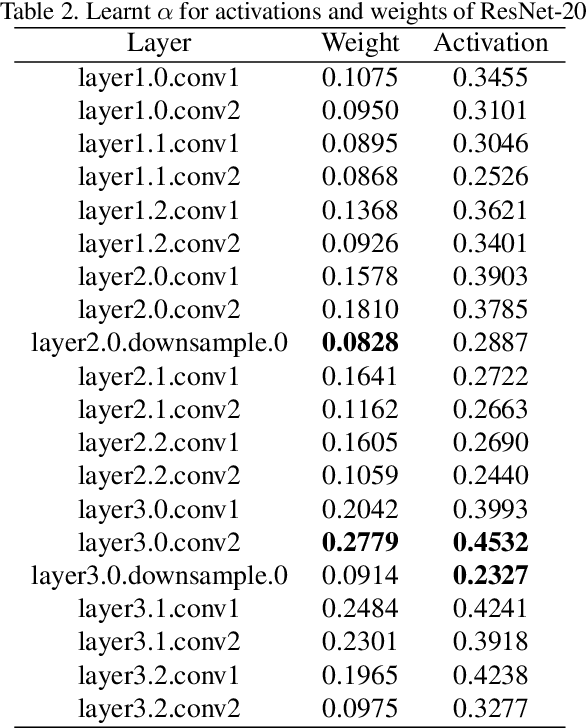
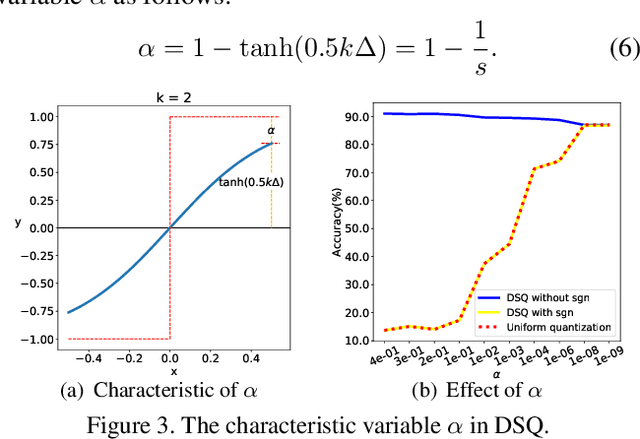
Hardware-friendly network quantization (e.g., binary/uniform quantization) can efficiently accelerate the inference and meanwhile reduce memory consumption of the deep neural networks, which is crucial for model deployment on resource-limited devices like mobile phones. However, due to the discreteness of low-bit quantization, existing quantization methods often face the unstable training process and severe performance degradation. To address this problem, in this paper we propose Differentiable Soft Quantization (DSQ) to bridge the gap between the full-precision and low-bit networks. DSQ can automatically evolve during training to gradually approximate the standard quantization. Owing to its differentiable property, DSQ can help pursue the accurate gradients in backward propagation, and reduce the quantization loss in forward process with an appropriate clipping range. Extensive experiments over several popular network structures show that training low-bit neural networks with DSQ can consistently outperform state-of-the-art quantization methods. Besides, our first efficient implementation for deploying 2 to 4-bit DSQ on devices with ARM architecture achieves up to 1.7$\times$ speed up, compared with the open-source 8-bit high-performance inference framework NCNN. [31]