 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Soft Quantization: Bridging Full-Precision and Low-Bit Neural Networks
Aug 14, 2019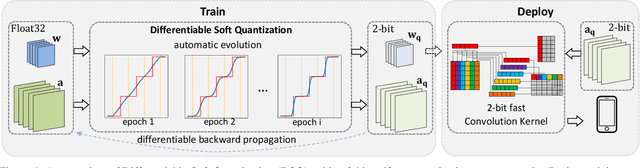
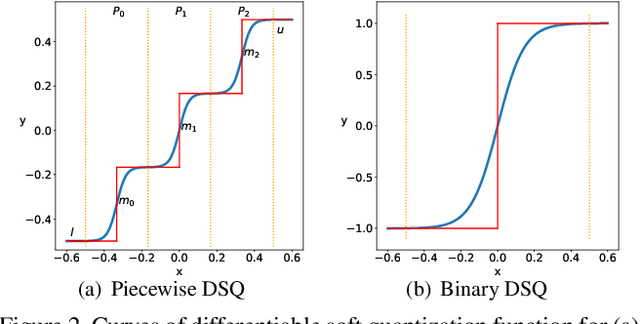
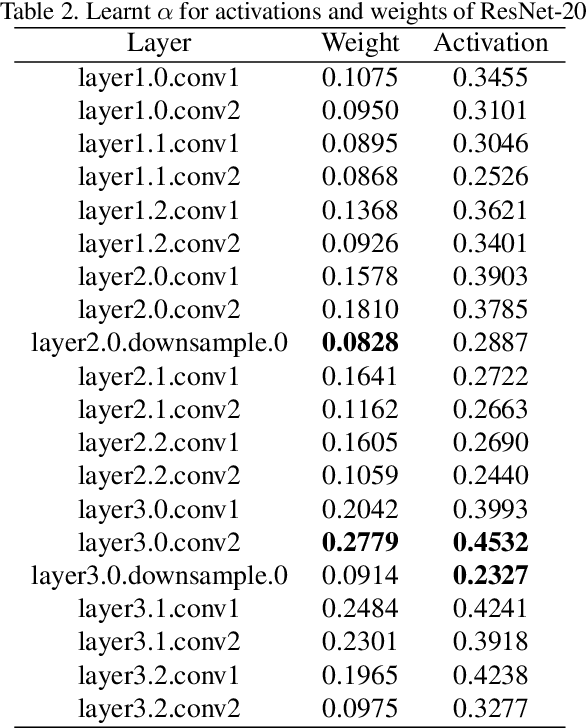
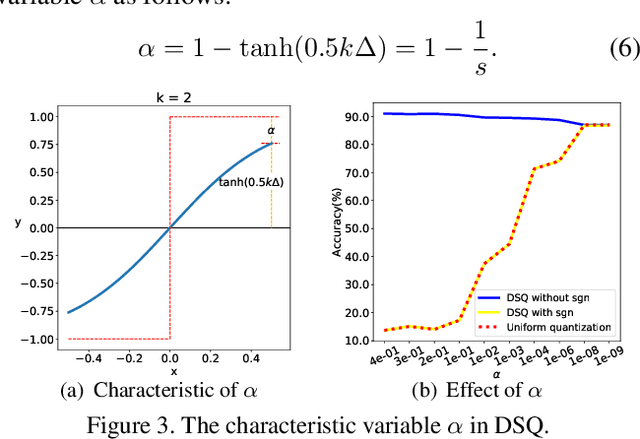
Hardware-friendly network quantization (e.g., binary/uniform quantization) can efficiently accelerate the inference and meanwhile reduce memory consumption of the deep neural networks, which is crucial for model deployment on resource-limited devices like mobile phones. However, due to the discreteness of low-bit quantization, existing quantization methods often face the unstable training process and severe performance degradation. To address this problem, in this paper we propose Differentiable Soft Quantization (DSQ) to bridge the gap between the full-precision and low-bit networks. DSQ can automatically evolve during training to gradually approximate the standard quantization. Owing to its differentiable property, DSQ can help pursue the accurate gradients in backward propagation, and reduce the quantization loss in forward process with an appropriate clipping range. Extensive experiments over several popular network structures show that training low-bit neural networks with DSQ can consistently outperform state-of-the-art quantization methods. Besides, our first efficient implementation for deploying 2 to 4-bit DSQ on devices with ARM architecture achieves up to 1.7$\times$ speed up, compared with the open-source 8-bit high-performance inference framework NCNN. [31]