 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAG: A Unified Native Architecture for Encoder-free Text-Graph Modeling in Language Models
Jan 30, 2026Prevailing methods for integrating graphs into Language Models (LMs) typically rely on a segregated architecture: external Graph Neural Networks (GNNs) encode structural topology, while LMs process textual semantics. We argue this approach is suboptimal for text-graphs: it creates a conceptually disjointed interaction paradigm. By segregating structural encoding from semantic processing, these systems must perform a complex implicit alignment between abstract graph tokens and concrete textual elements. Challenging the necessity of external encoders, we propose NAG (Native Architecture for Graphs), a unified framework that internalizes graph processing within the LM's native manifold. Instead of bridging disparate embedding spaces, NAG repurposes the self-attention mechanism to enforce topological dependencies and recalibrates positional IDs to ensure structural equivalence. This allows the model to harness its intrinsic linguistic capability to simultaneously comprehend node and edge content alongside structural topology. We introduce two efficient implementations: NAG-Zero for absolute preservation of the base model's linguistic capabilities, and NAG-LoRA for enhanced structural adaptation. Experiments across diverse graph tasks validate that NAG achieves robust graph comprehension without the overhead of external encoders, offering a simpler, more coherent paradigm for text-graph modeling.
Unveiling Signle-Bit-Flip Attacks on DNN Executables
Sep 12, 2023Recent research has shown that bit-flip attacks (BFAs) can manipulate deep neural networks (DNNs) via DRAM Rowhammer exploitations. Existing attacks are primarily launched over high-level DNN frameworks like PyTorch and flip bits in model weight files. Nevertheless, DNNs are frequently compiled into low-level executables by deep learning (DL) compilers to fully leverage low-level hardware primitives. The compiled code is usually high-speed and manifests dramatically distinct execution paradigms from high-level DNN frameworks. In this paper, we launch the first systematic study on the attack surface of BFA specifically for DNN executables compiled by DL compilers. We design an automated search tool to identify vulnerable bits in DNN executables and identify practical attack vectors that exploit the model structure in DNN executables with BFAs (whereas prior works make likely strong assumptions to attack model weights). DNN executables appear more "opaque" than models in high-level DNN frameworks. Nevertheless, we find that DNN executables contain extensive, severe (e.g., single-bit flip), and transferrable attack surfaces that are not present in high-level DNN models and can be exploited to deplete full model intelligence and control output labels. Our finding calls for incorporating security mechanisms in future DNN compilation toolchains.
Decompiling x86 Deep Neural Network Executables
Oct 04, 2022
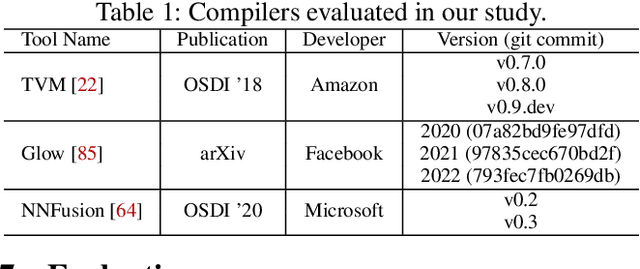
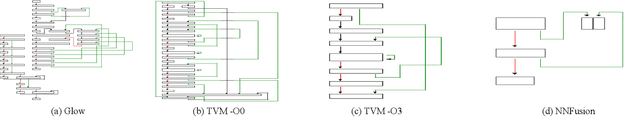
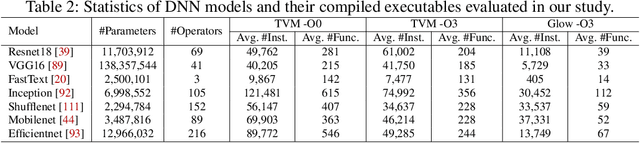
Due to their widespread use on heterogeneous hardware devices, deep learning (DL) models are compiled into executables by DL compilers to fully leverage low-level hardware primitives. This approach allows DL computations to be undertaken at low cost across a variety of computing platforms, including CPUs, GPUs, and various hardware accelerators. We present BTD (Bin to DNN), a decompiler for deep neural network (DNN) executables. BTD takes DNN executables and outputs full model specifications, including types of DNN operators, network topology, dimensions, and parameters that are (nearly) identical to those of the input models. BTD delivers a practical framework to process DNN executables compiled by different DL compilers and with full optimizations enabled on x86 platforms. It employs learning-based techniques to infer DNN operators, dynamic analysis to reveal network architectures, and symbolic execution to facilitate inferring dimensions and parameters of DNN operators. Our evaluation reveals that BTD enables accurate recovery of full specifications of complex DNNs with millions of parameters (e.g., ResNet). The recovered DNN specifications can be re-compiled into a new DNN executable exhibiting identical behavior to the input executable. We show that BTD can boost two representative attacks, adversarial example generation and knowledge stealing, against DNN executables. We also demonstrate cross-architecture legacy code reuse using BTD, and envision BTD being used for other critical downstream tasks like DNN security hardening and patching.
A Generative Adversarial Network for AI-Aided Chair Design
Jan 31, 2020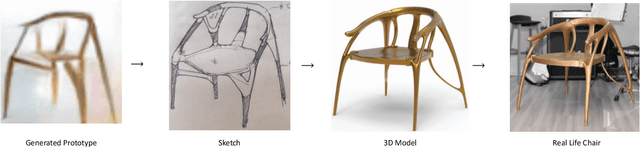
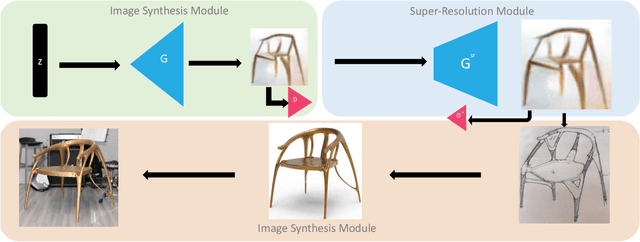


We present a method for improving human design of chairs. The goal of the method is generating enormous chair candidates in order to facilitate human designer by creating sketches and 3d models accordingly based on the generated chair design. It consists of an image synthesis module, which learns the underlying distribution of training dataset, a super-resolution module, which improve quality of generated image and human involvements. Finally, we manually pick one of the generated candidates to create a real life chair for illustration.