 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Sample-specific Backdoor Attack with Clean Labels via Attribute Trigger
Dec 03, 2023



Currently, sample-specific backdoor attacks (SSBAs) are the most advanced and malicious methods since they can easily circumvent most of the current backdoor defenses. In this paper, we reveal that SSBAs are not sufficiently stealthy due to their poisoned-label nature, where users can discover anomalies if they check the image-label relationship. In particular, we demonstrate that it is ineffective to directly generalize existing SSBAs to their clean-label variants by poisoning samples solely from the target class. We reveal that it is primarily due to two reasons, including \textbf{(1)} the `antagonistic effects' of ground-truth features and \textbf{(2)} the learning difficulty of sample-specific features. Accordingly, trigger-related features of existing SSBAs cannot be effectively learned under the clean-label setting due to their mild trigger intensity required for ensuring stealthiness. We argue that the intensity constraint of existing SSBAs is mostly because their trigger patterns are `content-irrelevant' and therefore act as `noises' for both humans and DNNs. Motivated by this understanding, we propose to exploit content-relevant features, $a.k.a.$ (human-relied) attributes, as the trigger patterns to design clean-label SSBAs. This new attack paradigm is dubbed backdoor attack with attribute trigger (BAAT). Extensive experiments are conducted on benchmark datasets, which verify the effectiveness of our BAAT and its resistance to existing defenses.
One-stage Low-resolution Text Recognition with High-resolution Knowledge Transfer
Aug 05, 2023



Recognizing characters from low-resolution (LR) text images poses a significant challenge due to the information deficiency as well as the noise and blur in low-quality images. Current solutions for low-resolution text recognition (LTR) typically rely on a two-stage pipeline that involves super-resolution as the first stage followed by the second-stage recognition. Although this pipeline is straightforward and intuitive, it has to use an additional super-resolution network, which causes inefficiencies during training and testing. Moreover, the recognition accuracy of the second stage heavily depends on the reconstruction quality of the first stage, causing ineffectiveness. In this work, we attempt to address these challenges from a novel perspective: adapting the recognizer to low-resolution inputs by transferring the knowledge from the high-resolution. Guided by this idea, we propose an efficient and effective knowledge distillation framework to achieve multi-level knowledge transfer. Specifically, the visual focus loss is proposed to extract the character position knowledge with resolution gap reduction and character region focus, the semantic contrastive loss is employed to exploit the contextual semantic knowledge with contrastive learning, and the soft logits loss facilitates both local word-level and global sequence-level learning from the soft teacher label. Extensive experiments show that the proposed one-stage pipeline significantly outperforms super-resolution based two-stage frameworks in terms of effectiveness and efficiency, accompanied by favorable robustness. Code is available at https://github.com/csguoh/KD-LTR.
High-Quality Supersampling via Mask-reinforced Deep Learning for Real-time Rendering
Jan 03, 2023To generate high quality rendering images for real time applications, it is often to trace only a few samples-per-pixel (spp) at a lower resolution and then supersample to the high resolution. Based on the observation that the rendered pixels at a low resolution are typically highly aliased, we present a novel method for neural supersampling based on ray tracing 1/4-spp samples at the high resolution. Our key insight is that the ray-traced samples at the target resolution are accurate and reliable, which makes the supersampling an interpolation problem. We present a mask-reinforced neural network to reconstruct and interpolate high-quality image sequences. First, a novel temporal accumulation network is introduced to compute the correlation between current and previous features to significantly improve their temporal stability. Then a reconstruct network based on a multi-scale U-Net with skip connections is adopted for reconstruction and generation of the desired high-resolution image. Experimental results and comparisons have shown that our proposed method can generate higher quality results of supersampling, without increasing the total number of ray-tracing samples, over current state-of-the-art methods.
Towards Mitigating the Problem of Insufficient and Ambiguous Supervision in Online Crowdsourcing Annotation
Oct 20, 2022
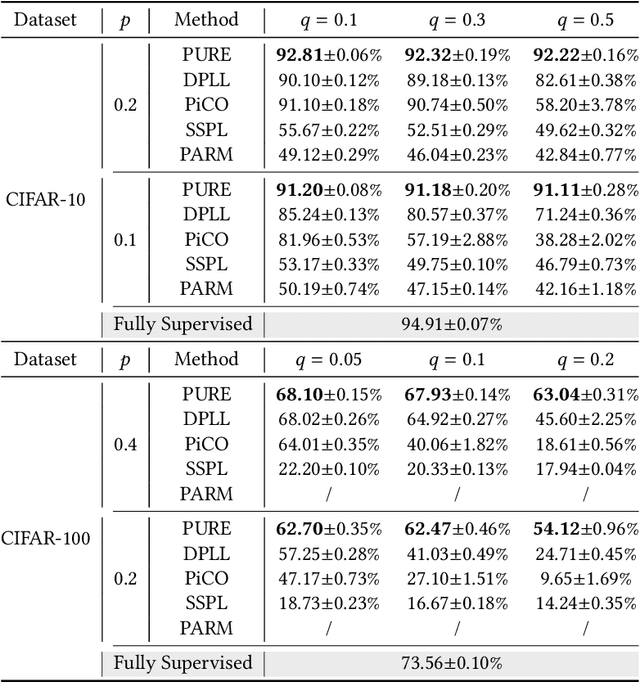

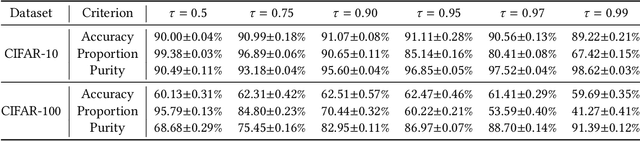
In real-world crowdsourcing annotation systems, due to differences in user knowledge and cultural backgrounds, as well as the high cost of acquiring annotation information, the supervision information we obtain might be insufficient and ambiguous. To mitigate the negative impacts, in this paper, we investigate a more general and broadly applicable learning problem, i.e. \emph{semi-supervised partial label learning}, and propose a novel method based on pseudo-labeling and contrastive learning. Following the key inventing principle, our method facilitate the partial label disambiguation process with unlabeled data and at the same time assign reliable pseudo-labels to weakly supervised examples. Specifically, our method learns from the ambiguous labeling information via partial cross-entropy loss. Meanwhile, high-accuracy pseudo-labels are generated for both partial and unlabeled examples through confidence-based thresholding and contrastive learning is performed in a hybrid unsupervised and supervised manner for more discriminative representations, while its supervision increases curriculumly. The two main components systematically work as a whole and reciprocate each other. In experiments, our method consistently outperforms all comparing methods by a significant margin and set up the first state-of-the-art performance for semi-supervised partial label learning on image benchmarks.