 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Pre-trained Vision-Language Models in a Human-Annotation-Free Manner
Feb 04, 2026Large-scale vision-language models (VLMs) such as CLIP exhibit strong zero-shot generalization, but adapting them to downstream tasks typically requires costly labeled data. Existing unsupervised self-training methods rely on pseudo-labeling, yet often suffer from unreliable confidence filtering, confirmation bias, and underutilization of low-confidence samples. We propose Collaborative Fine-Tuning (CoFT), an unsupervised adaptation framework that leverages unlabeled data through a dual-model, cross-modal collaboration mechanism. CoFT introduces a dual-prompt learning strategy with positive and negative textual prompts to explicitly model pseudo-label cleanliness in a sample-dependent manner, removing the need for hand-crafted thresholds or noise assumptions. The negative prompt also regularizes lightweight visual adaptation modules, improving robustness under noisy supervision. CoFT employs a two-phase training scheme, transitioning from parameter-efficient fine-tuning on high-confidence samples to full fine-tuning guided by collaboratively filtered pseudo-labels. Building on CoFT, CoFT+ further enhances adaptation via iterative fine-tuning, momentum contrastive learning, and LLM-generated prompts. Extensive experiments demonstrate consistent gains over existing unsupervised methods and even few-shot supervised baselines.
Heterogeneous Uncertainty-Guided Composed Image Retrieval with Fine-Grained Probabilistic Learning
Jan 16, 2026Composed Image Retrieval (CIR) enables image search by combining a reference image with modification text. Intrinsic noise in CIR triplets incurs intrinsic uncertainty and threatens the model's robustness. Probabilistic learning approaches have shown promise in addressing such issues; however, they fall short for CIR due to their instance-level holistic modeling and homogeneous treatment of queries and targets. This paper introduces a Heterogeneous Uncertainty-Guided (HUG) paradigm to overcome these limitations. HUG utilizes a fine-grained probabilistic learning framework, where queries and targets are represented by Gaussian embeddings that capture detailed concepts and uncertainties. We customize heterogeneous uncertainty estimations for multi-modal queries and uni-modal targets. Given a query, we capture uncertainties not only regarding uni-modal content quality but also multi-modal coordination, followed by a provable dynamic weighting mechanism to derive comprehensive query uncertainty. We further design uncertainty-guided objectives, including query-target holistic contrast and fine-grained contrasts with comprehensive negative sampling strategies, which effectively enhance discriminative learning. Experiments on benchmarks demonstrate HUG's effectiveness beyond state-of-the-art baselines, with faithful analysis justifying the technical contributions.
Enhancing Retrieval Augmentation via Adversarial Collaboration
Sep 18, 2025Retrieval-augmented Generation (RAG) is a prevalent approach for domain-specific LLMs, yet it is often plagued by "Retrieval Hallucinations"--a phenomenon where fine-tuned models fail to recognize and act upon poor-quality retrieved documents, thus undermining performance. To address this, we propose the Adversarial Collaboration RAG (AC-RAG) framework. AC-RAG employs two heterogeneous agents: a generalist Detector that identifies knowledge gaps, and a domain-specialized Resolver that provides precise solutions. Guided by a moderator, these agents engage in an adversarial collaboration, where the Detector's persistent questioning challenges the Resolver's expertise. This dynamic process allows for iterative problem dissection and refined knowledge retrieval. Extensive experiments show that AC-RAG significantly improves retrieval accuracy and outperforms state-of-the-art RAG methods across various vertical domains.
One-stage Low-resolution Text Recognition with High-resolution Knowledge Transfer
Aug 05, 2023



Recognizing characters from low-resolution (LR) text images poses a significant challenge due to the information deficiency as well as the noise and blur in low-quality images. Current solutions for low-resolution text recognition (LTR) typically rely on a two-stage pipeline that involves super-resolution as the first stage followed by the second-stage recognition. Although this pipeline is straightforward and intuitive, it has to use an additional super-resolution network, which causes inefficiencies during training and testing. Moreover, the recognition accuracy of the second stage heavily depends on the reconstruction quality of the first stage, causing ineffectiveness. In this work, we attempt to address these challenges from a novel perspective: adapting the recognizer to low-resolution inputs by transferring the knowledge from the high-resolution. Guided by this idea, we propose an efficient and effective knowledge distillation framework to achieve multi-level knowledge transfer. Specifically, the visual focus loss is proposed to extract the character position knowledge with resolution gap reduction and character region focus, the semantic contrastive loss is employed to exploit the contextual semantic knowledge with contrastive learning, and the soft logits loss facilitates both local word-level and global sequence-level learning from the soft teacher label. Extensive experiments show that the proposed one-stage pipeline significantly outperforms super-resolution based two-stage frameworks in terms of effectiveness and efficiency, accompanied by favorable robustness. Code is available at https://github.com/csguoh/KD-LTR.
Towards Robust Scene Text Image Super-resolution via Explicit Location Enhancement
Jul 30, 2023

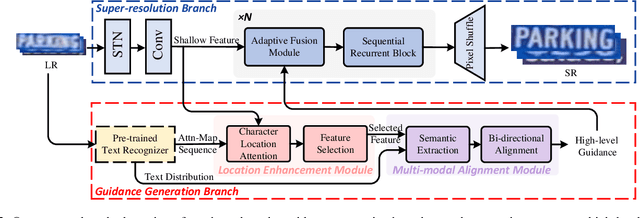

Scene text image super-resolution (STISR), aiming to improve image quality while boosting downstream scene text recognition accuracy, has recently achieved great success. However, most existing methods treat the foreground (character regions) and background (non-character regions) equally in the forward process, and neglect the disturbance from the complex background, thus limiting the performance. To address these issues, in this paper, we propose a novel method LEMMA that explicitly models character regions to produce high-level text-specific guidance for super-resolution. To model the location of characters effectively, we propose the location enhancement module to extract character region features based on the attention map sequence. Besides, we propose the multi-modal alignment module to perform bidirectional visual-semantic alignment to generate high-quality prior guidance, which is then incorporated into the super-resolution branch in an adaptive manner using the proposed adaptive fusion module. Experiments on TextZoom and four scene text recognition benchmarks demonstrate the superiority of our method over other state-of-the-art methods. Code is available at https://github.com/csguoh/LEMMA.
Multi-Objective Personalized Product Retrieval in Taobao Search
Oct 09, 2022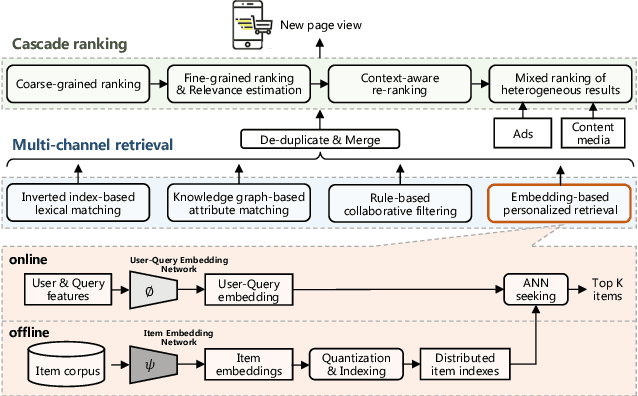

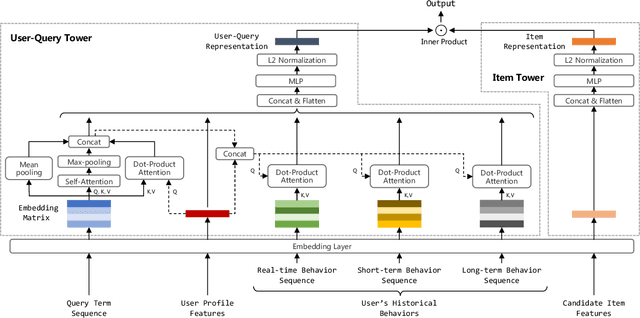

In large-scale e-commerce platforms like Taobao, it is a big challenge to retrieve products that satisfy users from billions of candidates. This has been a common concern of academia and industry. Recently, plenty of works in this domain have achieved significant improvements by enhancing embedding-based retrieval (EBR) methods, including the Multi-Grained Deep Semantic Product Retrieval (MGDSPR) model [16] in Taobao search engine. However, we find that MGDSPR still has problems of poor relevance and weak personalization compared to other retrieval methods in our online system, such as lexical matching and collaborative filtering. These problems promote us to further strengthen the capabilities of our EBR model in both relevance estimation and personalized retrieval. In this paper, we propose a novel Multi-Objective Personalized Product Retrieval (MOPPR) model with four hierarchical optimization objectives: relevance, exposure, click and purchase. We construct entire-space multi-positive samples to train MOPPR, rather than the single-positive samples for existing EBR models.We adopt a modified softmax loss for optimizing multiple objectives. Results of extensive offline and online experiments show that MOPPR outperforms the baseline MGDSPR on evaluation metrics of relevance estimation and personalized retrieval. MOPPR achieves 0.96% transaction and 1.29% GMV improvements in a 28-day online A/B test. Since the Double-11 shopping festival of 2021, MOPPR has been fully deployed in mobile Taobao search, replacing the previous MGDSPR. Finally, we discuss several advanced topics of our deeper explorations on multi-objective retrieval and ranking to contribute to the community.