 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMAIF: Multi-task and Multi-degradation All-in-One for Image Fusion with Language Guidance
Paper and Code
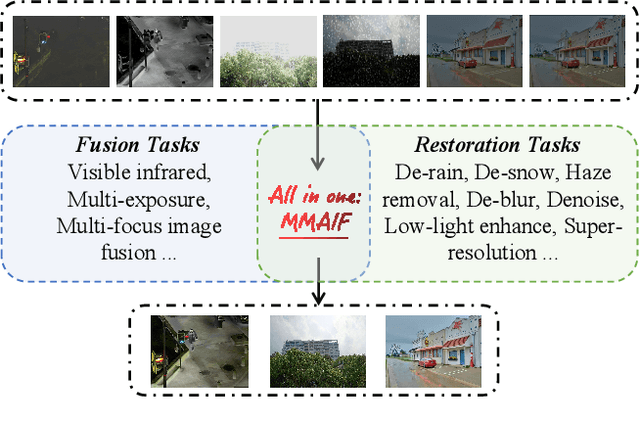

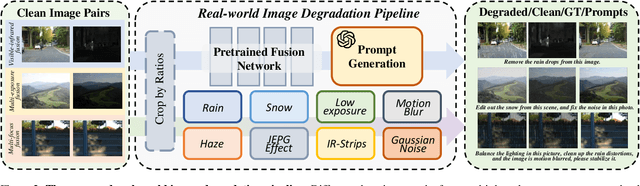
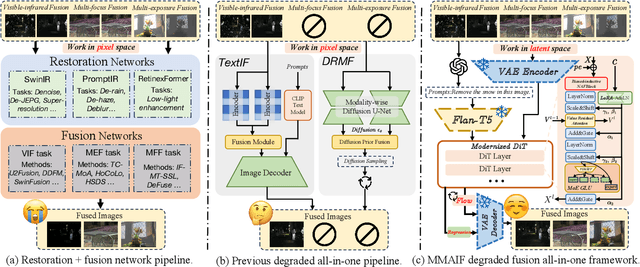
Image fusion, a fundamental low-level vision task, aims to integrate multiple image sequences into a single output while preserving as much information as possible from the input. However, existing methods face several significant limitations: 1) requiring task- or dataset-specific models; 2) neglecting real-world image degradations (\textit{e.g.}, noise), which causes failure when processing degraded inputs; 3) operating in pixel space, where attention mechanisms are computationally expensive; and 4) lacking user interaction capabilities. To address these challenges, we propose a unified framework for multi-task, multi-degradation, and language-guided image fusion. Our framework includes two key components: 1) a practical degradation pipeline that simulates real-world image degradations and generates interactive prompts to guide the model; 2) an all-in-one Diffusion Transformer (DiT) operating in latent space, which fuses a clean image conditioned on both the degraded inputs and the generated prompts. Furthermore, we introduce principled modifications to the original DiT architecture to better suit the fusion task. Based on this framework, we develop two versions of the model: Regression-based and Flow Matching-based variants. Extensive qualitative and quantitative experiments demonstrate that our approach effectively addresses the aforementioned limitations and outperforms previous restoration+fusion and all-in-one pipelines. Codes are available at https://github.com/294coder/MMAIF.