 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSirens' Whisper: Inaudible Near-Ultrasonic Jailbreaks of Speech-Driven LLMs
Mar 14, 2026Speech-driven large language models (LLMs) are increasingly accessed through speech interfaces, introducing new security risks via open acoustic channels. We present Sirens' Whisper (SWhisper), the first practical framework for covert prompt-based attacks against speech-driven LLMs under realistic black-box conditions using commodity hardware. SWhisper enables robust, inaudible delivery of arbitrary target baseband audio-including long and structured prompts-on commodity devices by encoding it into near-ultrasound waveforms that demodulate faithfully after acoustic transmission and microphone nonlinearity. This is achieved through a simple yet effective approach to modeling nonlinear channel characteristics across devices and environments, combined with lightweight channel-inversion pre-compensation. Building on this high-fidelity covert channel, we design a voice-aware jailbreak generation method that ensures intelligibility, brevity, and transferability under speech-driven interfaces. Experiments across both commercial and open-source speech-driven LLMs demonstrate strong black-box effectiveness. On commercial models, SWhisper achieves up to 0.94 non-refusal (NR) and 0.925 specific-convincing (SC). A controlled user study further shows that the injected jailbreak audio is perceptually indistinguishable from background-only playback for human listeners. Although jailbreaks serve as a case study, the underlying covert acoustic channel enables a broader class of high-fidelity prompt-injection and commandexecution attacks.
Cross-Scale Pansharpening via ScaleFormer and the PanScale Benchmark
Feb 28, 2026Pansharpening aims to generate high-resolution multi-spectral images by fusing the spatial detail of panchromatic images with the spectral richness of low-resolution MS data. However, most existing methods are evaluated under limited, low-resolution settings, limiting their generalization to real-world, high-resolution scenarios. To bridge this gap, we systematically investigate the data, algorithmic, and computational challenges of cross-scale pansharpening. We first introduce PanScale, the first large-scale, cross-scale pansharpening dataset, accompanied by PanScale-Bench, a comprehensive benchmark for evaluating generalization across varying resolutions and scales. To realize scale generalization, we propose ScaleFormer, a novel architecture designed for multi-scale pansharpening. ScaleFormer reframes generalization across image resolutions as generalization across sequence lengths: it tokenizes images into patch sequences of the same resolution but variable length proportional to image scale. A Scale-Aware Patchify module enables training for such variations from fixed-size crops. ScaleFormer then decouples intra-patch spatial feature learning from inter-patch sequential dependency modeling, incorporating Rotary Positional Encoding to enhance extrapolation to unseen scales. Extensive experiments show that our approach outperforms SOTA methods in fusion quality and cross-scale generalization. The datasets and source code are available upon acceptance.
Distilling Textual Priors from LLM to Efficient Image Fusion
Apr 09, 2025



Multi-modality image fusion aims to synthesize a single, comprehensive image from multiple source inputs. Traditional approaches, such as CNNs and GANs, offer efficiency but struggle to handle low-quality or complex inputs. Recent advances in text-guided methods leverage large model priors to overcome these limitations, but at the cost of significant computational overhead, both in memory and inference time. To address this challenge, we propose a novel framework for distilling large model priors, eliminating the need for text guidance during inference while dramatically reducing model size. Our framework utilizes a teacher-student architecture, where the teacher network incorporates large model priors and transfers this knowledge to a smaller student network via a tailored distillation process. Additionally, we introduce spatial-channel cross-fusion module to enhance the model's ability to leverage textual priors across both spatial and channel dimensions. Our method achieves a favorable trade-off between computational efficiency and fusion quality. The distilled network, requiring only 10\% of the parameters and inference time of the teacher network, retains 90\% of its performance and outperforms existing SOTA methods. Extensive experiments demonstrate the effectiveness of our approach. The implementation will be made publicly available as an open-source resource.
Shuffle Mamba: State Space Models with Random Shuffle for Multi-Modal Image Fusion
Sep 03, 2024



Multi-modal image fusion integrates complementary information from different modalities to produce enhanced and informative images. Although State-Space Models, such as Mamba, are proficient in long-range modeling with linear complexity, most Mamba-based approaches use fixed scanning strategies, which can introduce biased prior information. To mitigate this issue, we propose a novel Bayesian-inspired scanning strategy called Random Shuffle, supplemented by an theoretically-feasible inverse shuffle to maintain information coordination invariance, aiming to eliminate biases associated with fixed sequence scanning. Based on this transformation pair, we customized the Shuffle Mamba Framework, penetrating modality-aware information representation and cross-modality information interaction across spatial and channel axes to ensure robust interaction and an unbiased global receptive field for multi-modal image fusion. Furthermore, we develop a testing methodology based on Monte-Carlo averaging to ensure the model's output aligns more closely with expected results. Extensive experiments across multiple multi-modal image fusion tasks demonstrate the effectiveness of our proposed method, yielding excellent fusion quality over state-of-the-art alternatives. Code will be available upon acceptance.
Training-Free Large Model Priors for Multiple-in-One Image Restoration
Jul 18, 2024Image restoration aims to reconstruct the latent clear images from their degraded versions. Despite the notable achievement, existing methods predominantly focus on handling specific degradation types and thus require specialized models, impeding real-world applications in dynamic degradation scenarios. To address this issue, we propose Large Model Driven Image Restoration framework (LMDIR), a novel multiple-in-one image restoration paradigm that leverages the generic priors from large multi-modal language models (MMLMs) and the pretrained diffusion models. In detail, LMDIR integrates three key prior knowledges: 1) global degradation knowledge from MMLMs, 2) scene-aware contextual descriptions generated by MMLMs, and 3) fine-grained high-quality reference images synthesized by diffusion models guided by MMLM descriptions. Standing on above priors, our architecture comprises a query-based prompt encoder, degradation-aware transformer block injecting global degradation knowledge, content-aware transformer block incorporating scene description, and reference-based transformer block incorporating fine-grained image priors. This design facilitates single-stage training paradigm to address various degradations while supporting both automatic and user-guided restoration. Extensive experiments demonstrate that our designed method outperforms state-of-the-art competitors on multiple evaluation benchmarks.
ID-Animator: Zero-Shot Identity-Preserving Human Video Generation
Apr 23, 2024



Generating high fidelity human video with specified identities has attracted significant attention in the content generation community. However, existing techniques struggle to strike a balance between training efficiency and identity preservation, either requiring tedious case-by-case finetuning or usually missing the identity details in video generation process. In this study, we present ID-Animator, a zero-shot human-video generation approach that can perform personalized video generation given single reference facial image without further training. ID-Animator inherits existing diffusion-based video generation backbones with a face adapter to encode the ID-relevant embeddings from learnable facial latent queries. To facilitate the extraction of identity information in video generation, we introduce an ID-oriented dataset construction pipeline, which incorporates decoupled human attribute and action captioning technique from a constructed facial image pool. Based on this pipeline, a random face reference training method is further devised to precisely capture the ID-relevant embeddings from reference images, thus improving the fidelity and generalization capacity of our model for ID-specific video generation. Extensive experiments demonstrate the superiority of ID-Animator to generate personalized human videos over previous models. Moreover, our method is highly compatible with popular pre-trained T2V models like animatediff and various community backbone models, showing high extendability in real-world applications for video generation where identity preservation is highly desired. Our codes and checkpoints will be released at https://github.com/ID-Animator/ID-Animator.
Linearly-evolved Transformer for Pan-sharpening
Apr 19, 2024



Vision transformer family has dominated the satellite pan-sharpening field driven by the global-wise spatial information modeling mechanism from the core self-attention ingredient. The standard modeling rules within these promising pan-sharpening methods are to roughly stack the transformer variants in a cascaded manner. Despite the remarkable advancement, their success may be at the huge cost of model parameters and FLOPs, thus preventing its application over low-resource satellites.To address this challenge between favorable performance and expensive computation, we tailor an efficient linearly-evolved transformer variant and employ it to construct a lightweight pan-sharpening framework. In detail, we deepen into the popular cascaded transformer modeling with cutting-edge methods and develop the alternative 1-order linearly-evolved transformer variant with the 1-dimensional linear convolution chain to achieve the same function. In this way, our proposed method is capable of benefiting the cascaded modeling rule while achieving favorable performance in the efficient manner. Extensive experiments over multiple satellite datasets suggest that our proposed method achieves competitive performance against other state-of-the-art with fewer computational resources. Further, the consistently favorable performance has been verified over the hyper-spectral image fusion task. Our main focus is to provide an alternative global modeling framework with an efficient structure. The code will be publicly available.
Pan-Mamba: Effective pan-sharpening with State Space Model
Feb 19, 2024



Pan-sharpening involves integrating information from lowresolution multi-spectral and high-resolution panchromatic images to generate high-resolution multi-spectral counterparts. While recent advancements in the state space model, particularly the efficient long-range dependency modeling achieved by Mamba, have revolutionized computer vision community, its untapped potential in pan-sharpening motivates our exploration. Our contribution, Pan-Mamba, represents a novel pansharpening network that leverages the efficiency of the Mamba model in global information modeling. In Pan-Mamba, we customize two core components: channel swapping Mamba and cross-modal Mamba, strategically designed for efficient cross-modal information exchange and fusion. The former initiates a lightweight cross-modal interaction through the exchange of partial panchromatic and multispectral channels, while the latter facilities the information representation capability by exploiting inherent cross-modal relationships. Through extensive experiments across diverse datasets, our proposed approach surpasses state-of-theart methods, showcasing superior fusion results in pan-sharpening. To the best of our knowledge, this work is the first attempt in exploring the potential of the Mamba model and establishes a new frontier in the pan-sharpening techniques. The source code is available at https://github.com/alexhe101/Pan-Mamba .
Frequency-Adaptive Pan-Sharpening with Mixture of Experts
Jan 04, 2024Pan-sharpening involves reconstructing missing high-frequency information in multi-spectral images with low spatial resolution, using a higher-resolution panchromatic image as guidance. Although the inborn connection with frequency domain, existing pan-sharpening research has not almost investigated the potential solution upon frequency domain. To this end, we propose a novel Frequency Adaptive Mixture of Experts (FAME) learning framework for pan-sharpening, which consists of three key components: the Adaptive Frequency Separation Prediction Module, the Sub-Frequency Learning Expert Module, and the Expert Mixture Module. In detail, the first leverages the discrete cosine transform to perform frequency separation by predicting the frequency mask. On the basis of generated mask, the second with low-frequency MOE and high-frequency MOE takes account for enabling the effective low-frequency and high-frequency information reconstruction. Followed by, the final fusion module dynamically weights high-frequency and low-frequency MOE knowledge to adapt to remote sensing images with significant content variations. Quantitative and qualitative experiments over multiple datasets demonstrate that our method performs the best against other state-of-the-art ones and comprises a strong generalization ability for real-world scenes. Code will be made publicly at \url{https://github.com/alexhe101/FAME-Net}.
Enhancing RAW-to-sRGB with Decoupled Style Structure in Fourier Domain
Jan 04, 2024


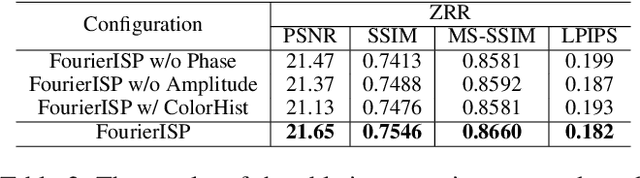
RAW to sRGB mapping, which aims to convert RAW images from smartphones into RGB form equivalent to that of Digital Single-Lens Reflex (DSLR) cameras, has become an important area of research. However, current methods often ignore the difference between cell phone RAW images and DSLR camera RGB images, a difference that goes beyond the color matrix and extends to spatial structure due to resolution variations. Recent methods directly rebuild color mapping and spatial structure via shared deep representation, limiting optimal performance. Inspired by Image Signal Processing (ISP) pipeline, which distinguishes image restoration and enhancement, we present a novel Neural ISP framework, named FourierISP. This approach breaks the image down into style and structure within the frequency domain, allowing for independent optimization. FourierISP is comprised of three subnetworks: Phase Enhance Subnet for structural refinement, Amplitude Refine Subnet for color learning, and Color Adaptation Subnet for blending them in a smooth manner. This approach sharpens both color and structure, and extensive evaluations across varied datasets confirm that our approach realizes state-of-the-art results. Code will be available at ~\url{https://github.com/alexhe101/FourierISP}.