 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentityStory: Taming Your Identity-Preserving Generator for Human-Centric Story Generation
Dec 29, 2025Recent visual generative models enable story generation with consistent characters from text, but human-centric story generation faces additional challenges, such as maintaining detailed and diverse human face consistency and coordinating multiple characters across different images. This paper presents IdentityStory, a framework for human-centric story generation that ensures consistent character identity across multiple sequential images. By taming identity-preserving generators, the framework features two key components: Iterative Identity Discovery, which extracts cohesive character identities, and Re-denoising Identity Injection, which re-denoises images to inject identities while preserving desired context. Experiments on the ConsiStory-Human benchmark demonstrate that IdentityStory outperforms existing methods, particularly in face consistency, and supports multi-character combinations. The framework also shows strong potential for applications such as infinite-length story generation and dynamic character composition.
Visual-Aware CoT: Achieving High-Fidelity Visual Consistency in Unified Models
Dec 22, 2025Recently, the introduction of Chain-of-Thought (CoT) has largely improved the generation ability of unified models. However, it is observed that the current thinking process during generation mainly focuses on the text consistency with the text prompt, ignoring the \textbf{visual context consistency} with the visual reference images during the multi-modal generation, e.g., multi-reference generation. The lack of such consistency results in the failure in maintaining key visual features (like human ID, object attribute, style). To this end, we integrate the visual context consistency into the reasoning of unified models, explicitly motivating the model to sustain such consistency by 1) Adaptive Visual Planning: generating structured visual check list to figure out the visual element of needed consistency keeping, and 2) Iterative Visual Correction: performing self-reflection with the guidance of check lists and refining the generated result in an iterative manner. To achieve this, we use supervised finetuning to teach the model how to plan the visual checking, conduct self-reflection and self-refinement, and use flow-GRPO to further enhance the visual consistency through a customized visual checking reward. The experiments show that our method outperforms both zero-shot unified models and those with text CoTs in multi-modal generation, demonstrating higher visual context consistency.
In-Context Audio Control of Video Diffusion Transformers
Dec 21, 2025Recent advancements in video generation have seen a shift towards unified, transformer-based foundation models that can handle multiple conditional inputs in-context. However, these models have primarily focused on modalities like text, images, and depth maps, while strictly time-synchronous signals like audio have been underexplored. This paper introduces In-Context Audio Control of video diffusion transformers (ICAC), a framework that investigates the integration of audio signals for speech-driven video generation within a unified full-attention architecture, akin to FullDiT. We systematically explore three distinct mechanisms for injecting audio conditions: standard cross-attention, 2D self-attention, and unified 3D self-attention. Our findings reveal that while 3D attention offers the highest potential for capturing spatio-temporal audio-visual correlations, it presents significant training challenges. To overcome this, we propose a Masked 3D Attention mechanism that constrains the attention pattern to enforce temporal alignment, enabling stable training and superior performance. Our experiments demonstrate that this approach achieves strong lip synchronization and video quality, conditioned on an audio stream and reference images.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
FullDiT2: Efficient In-Context Conditioning for Video Diffusion Transformers
Jun 05, 2025


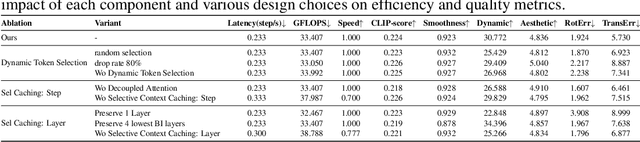
Fine-grained and efficient controllability on video diffusion transformers has raised increasing desires for the applicability. Recently, In-context Conditioning emerged as a powerful paradigm for unified conditional video generation, which enables diverse controls by concatenating varying context conditioning signals with noisy video latents into a long unified token sequence and jointly processing them via full-attention, e.g., FullDiT. Despite their effectiveness, these methods face quadratic computation overhead as task complexity increases, hindering practical deployment. In this paper, we study the efficiency bottleneck neglected in original in-context conditioning video generation framework. We begin with systematic analysis to identify two key sources of the computation inefficiencies: the inherent redundancy within context condition tokens and the computational redundancy in context-latent interactions throughout the diffusion process. Based on these insights, we propose FullDiT2, an efficient in-context conditioning framework for general controllability in both video generation and editing tasks, which innovates from two key perspectives. Firstly, to address the token redundancy, FullDiT2 leverages a dynamic token selection mechanism to adaptively identify important context tokens, reducing the sequence length for unified full-attention. Additionally, a selective context caching mechanism is devised to minimize redundant interactions between condition tokens and video latents. Extensive experiments on six diverse conditional video editing and generation tasks demonstrate that FullDiT2 achieves significant computation reduction and 2-3 times speedup in averaged time cost per diffusion step, with minimal degradation or even higher performance in video generation quality. The project page is at \href{https://fulldit2.github.io/}{https://fulldit2.github.io/}.
UNIC: Unified In-Context Video Editing
Jun 04, 2025

Recent advances in text-to-video generation have sparked interest in generative video editing tasks. Previous methods often rely on task-specific architectures (e.g., additional adapter modules) or dedicated customizations (e.g., DDIM inversion), which limit the integration of versatile editing conditions and the unification of various editing tasks. In this paper, we introduce UNified In-Context Video Editing (UNIC), a simple yet effective framework that unifies diverse video editing tasks within a single model in an in-context manner. To achieve this unification, we represent the inputs of various video editing tasks as three types of tokens: the source video tokens, the noisy video latent, and the multi-modal conditioning tokens that vary according to the specific editing task. Based on this formulation, our key insight is to integrate these three types into a single consecutive token sequence and jointly model them using the native attention operations of DiT, thereby eliminating the need for task-specific adapter designs. Nevertheless, direct task unification under this framework is challenging, leading to severe token collisions and task confusion due to the varying video lengths and diverse condition modalities across tasks. To address these, we introduce task-aware RoPE to facilitate consistent temporal positional encoding, and condition bias that enables the model to clearly differentiate different editing tasks. This allows our approach to adaptively perform different video editing tasks by referring the source video and varying condition tokens "in context", and support flexible task composition. To validate our method, we construct a unified video editing benchmark containing six representative video editing tasks. Results demonstrate that our unified approach achieves superior performance on each task and exhibits emergent task composition abilities.
A Survey of Interactive Generative Video
Apr 30, 2025
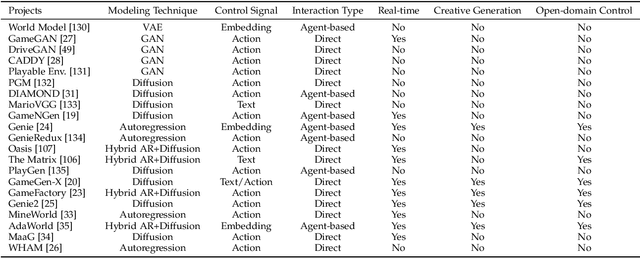


Interactive Generative Video (IGV) has emerged as a crucial technology in response to the growing demand for high-quality, interactive video content across various domains. In this paper, we define IGV as a technology that combines generative capabilities to produce diverse high-quality video content with interactive features that enable user engagement through control signals and responsive feedback. We survey the current landscape of IGV applications, focusing on three major domains: 1) gaming, where IGV enables infinite exploration in virtual worlds; 2) embodied AI, where IGV serves as a physics-aware environment synthesizer for training agents in multimodal interaction with dynamically evolving scenes; and 3) autonomous driving, where IGV provides closed-loop simulation capabilities for safety-critical testing and validation. To guide future development, we propose a comprehensive framework that decomposes an ideal IGV system into five essential modules: Generation, Control, Memory, Dynamics, and Intelligence. Furthermore, we systematically analyze the technical challenges and future directions in realizing each component for an ideal IGV system, such as achieving real-time generation, enabling open-domain control, maintaining long-term coherence, simulating accurate physics, and integrating causal reasoning. We believe that this systematic analysis will facilitate future research and development in the field of IGV, ultimately advancing the technology toward more sophisticated and practical applications.
Any2Caption:Interpreting Any Condition to Caption for Controllable Video Generation
Mar 31, 2025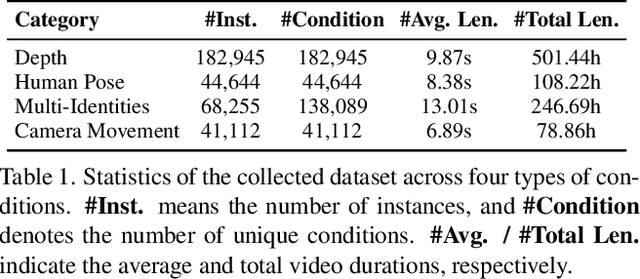



To address the bottleneck of accurate user intent interpretation within the current video generation community, we present Any2Caption, a novel framework for controllable video generation under any condition. The key idea is to decouple various condition interpretation steps from the video synthesis step. By leveraging modern multimodal large language models (MLLMs), Any2Caption interprets diverse inputs--text, images, videos, and specialized cues such as region, motion, and camera poses--into dense, structured captions that offer backbone video generators with better guidance. We also introduce Any2CapIns, a large-scale dataset with 337K instances and 407K conditions for any-condition-to-caption instruction tuning. Comprehensive evaluations demonstrate significant improvements of our system in controllability and video quality across various aspects of existing video generation models. Project Page: https://sqwu.top/Any2Cap/
FullDiT: Multi-Task Video Generative Foundation Model with Full Attention
Mar 25, 2025Current video generative foundation models primarily focus on text-to-video tasks, providing limited control for fine-grained video content creation. Although adapter-based approaches (e.g., ControlNet) enable additional controls with minimal fine-tuning, they encounter challenges when integrating multiple conditions, including: branch conflicts between independently trained adapters, parameter redundancy leading to increased computational cost, and suboptimal performance compared to full fine-tuning. To address these challenges, we introduce FullDiT, a unified foundation model for video generation that seamlessly integrates multiple conditions via unified full-attention mechanisms. By fusing multi-task conditions into a unified sequence representation and leveraging the long-context learning ability of full self-attention to capture condition dynamics, FullDiT reduces parameter overhead, avoids conditions conflict, and shows scalability and emergent ability. We further introduce FullBench for multi-task video generation evaluation. Experiments demonstrate that FullDiT achieves state-of-the-art results, highlighting the efficacy of full-attention in complex multi-task video generation.
Position: Interactive Generative Video as Next-Generation Game Engine
Mar 21, 2025Modern game development faces significant challenges in creativity and cost due to predetermined content in traditional game engines. Recent breakthroughs in video generation models, capable of synthesizing realistic and interactive virtual environments, present an opportunity to revolutionize game creation. In this position paper, we propose Interactive Generative Video (IGV) as the foundation for Generative Game Engines (GGE), enabling unlimited novel content generation in next-generation gaming. GGE leverages IGV's unique strengths in unlimited high-quality content synthesis, physics-aware world modeling, user-controlled interactivity, long-term memory capabilities, and causal reasoning. We present a comprehensive framework detailing GGE's core modules and a hierarchical maturity roadmap (L0-L4) to guide its evolution. Our work charts a new course for game development in the AI era, envisioning a future where AI-powered generative systems fundamentally reshape how games are created and experienced.