 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePest-Thinker: Learning to Think and Reason like Entomologists via Reinforcement Learning
May 07, 2026Pest-induced crop losses pose a major threat to global food security and sustainable agricultural development. While recent advances in Multimodal Large Language Models (MLLMs) have shown strong potential for visual understanding and smart agriculture, their direct application to pest recognition remains limited due to the domain's unique challenges such as high inter-species complexity, intra-species variability, and the scarcity of expert-annotated data. In this work, we introduce Pest-Thinker, a knowledge-driven reinforcement learning (RL) framework that enables MLLMs to reason over fine-grained pest morphology. We first construct two high-definition pest benchmarks, QFSD and AgriInsect, comprising diverse species and expert-annotated morphological traits. Leveraging these datasets, we synthesize Chain-of-Thought (CoT) reasoning trajectories to facilitate structured learning of pest-specific visual cues through Supervised Fine-Tuning (SFT). Subsequently, we employ Group Relative Policy Optimization (GRPO) with a novel feature reward that guides the model to focus on observable morphological evidence, assessed by an LLM-as-a-Judge strategy. Extensive experiments demonstrate that Pest-Thinker substantially improves both in-domain and out-of-domain morphological understanding, marking a step toward expert-level visual reasoning for intelligent agricultural pest analysis. The datasets and source code are available upon acceptance.
Cross-Scale Pansharpening via ScaleFormer and the PanScale Benchmark
Feb 28, 2026Pansharpening aims to generate high-resolution multi-spectral images by fusing the spatial detail of panchromatic images with the spectral richness of low-resolution MS data. However, most existing methods are evaluated under limited, low-resolution settings, limiting their generalization to real-world, high-resolution scenarios. To bridge this gap, we systematically investigate the data, algorithmic, and computational challenges of cross-scale pansharpening. We first introduce PanScale, the first large-scale, cross-scale pansharpening dataset, accompanied by PanScale-Bench, a comprehensive benchmark for evaluating generalization across varying resolutions and scales. To realize scale generalization, we propose ScaleFormer, a novel architecture designed for multi-scale pansharpening. ScaleFormer reframes generalization across image resolutions as generalization across sequence lengths: it tokenizes images into patch sequences of the same resolution but variable length proportional to image scale. A Scale-Aware Patchify module enables training for such variations from fixed-size crops. ScaleFormer then decouples intra-patch spatial feature learning from inter-patch sequential dependency modeling, incorporating Rotary Positional Encoding to enhance extrapolation to unseen scales. Extensive experiments show that our approach outperforms SOTA methods in fusion quality and cross-scale generalization. The datasets and source code are available upon acceptance.
When Classes Evolve: A Benchmark and Framework for Stage-Aware Class-Incremental Learning
Jan 31, 2026Class-Incremental Learning (CIL) aims to sequentially learn new classes while mitigating catastrophic forgetting of previously learned knowledge. Conventional CIL approaches implicitly assume that classes are morphologically static, focusing primarily on preserving previously learned representations as new classes are introduced. However, this assumption neglects intra-class evolution: a phenomenon wherein instances of the same semantic class undergo significant morphological transformations, such as a larva turning into a butterfly. Consequently, a model must both discriminate between classes and adapt to evolving appearances within a single class. To systematically address this challenge, we formalize Stage-Aware CIL (Stage-CIL), a paradigm in which each class is learned progressively through distinct morphological stages. To facilitate rigorous evaluation within this paradigm, we introduce the Stage-Bench, a 10-domain, 2-stages dataset and protocol that jointly measure inter- and intra-class forgetting. We further propose STAGE, a novel method that explicitly learns abstract and transferable evolution patterns within a fixed-size memory pool. By decoupling semantic identity from transformation dynamics, STAGE enables accurate prediction of future morphologies based on earlier representations. Extensive empirical evaluation demonstrates that STAGE consistently and substantially outperforms existing state-of-the-art approaches, highlighting its effectiveness in simultaneously addressing inter-class discrimination and intra-class morphological adaptation.
SenseNova-MARS: Empowering Multimodal Agentic Reasoning and Search via Reinforcement Learning
Dec 30, 2025While Vision-Language Models (VLMs) can solve complex tasks through agentic reasoning, their capabilities remain largely constrained to text-oriented chain-of-thought or isolated tool invocation. They fail to exhibit the human-like proficiency required to seamlessly interleave dynamic tool manipulation with continuous reasoning, particularly in knowledge-intensive and visually complex scenarios that demand coordinated external tools such as search and image cropping. In this work, we introduce SenseNova-MARS, a novel Multimodal Agentic Reasoning and Search framework that empowers VLMs with interleaved visual reasoning and tool-use capabilities via reinforcement learning (RL). Specifically, SenseNova-MARS dynamically integrates the image search, text search, and image crop tools to tackle fine-grained and knowledge-intensive visual understanding challenges. In the RL stage, we propose the Batch-Normalized Group Sequence Policy Optimization (BN-GSPO) algorithm to improve the training stability and advance the model's ability to invoke tools and reason effectively. To comprehensively evaluate the agentic VLMs on complex visual tasks, we introduce the HR-MMSearch benchmark, the first search-oriented benchmark composed of high-resolution images with knowledge-intensive and search-driven questions. Experiments demonstrate that SenseNova-MARS achieves state-of-the-art performance on open-source search and fine-grained image understanding benchmarks. Specifically, on search-oriented benchmarks, SenseNova-MARS-8B scores 67.84 on MMSearch and 41.64 on HR-MMSearch, surpassing proprietary models such as Gemini-3-Flash and GPT-5. SenseNova-MARS represents a promising step toward agentic VLMs by providing effective and robust tool-use capabilities. To facilitate further research in this field, we will release all code, models, and datasets.
O$^2$-Searcher: A Searching-based Agent Model for Open-Domain Open-Ended Question Answering
May 22, 2025


Large Language Models (LLMs), despite their advancements, are fundamentally limited by their static parametric knowledge, hindering performance on tasks requiring open-domain up-to-date information. While enabling LLMs to interact with external knowledge environments is a promising solution, current efforts primarily address closed-end problems. Open-ended questions, which characterized by lacking a standard answer or providing non-unique and diverse answers, remain underexplored. To bridge this gap, we present O$^2$-Searcher, a novel search agent leveraging reinforcement learning to effectively tackle both open-ended and closed-ended questions in the open domain. O$^2$-Searcher leverages an efficient, locally simulated search environment for dynamic knowledge acquisition, effectively decoupling the external world knowledge from model's sophisticated reasoning processes. It employs a unified training mechanism with meticulously designed reward functions, enabling the agent to identify problem types and adapt different answer generation strategies. Furthermore, to evaluate performance on complex open-ended tasks, we construct O$^2$-QA, a high-quality benchmark featuring 300 manually curated, multi-domain open-ended questions with associated web page caches. Extensive experiments show that O$^2$-Searcher, using only a 3B model, significantly surpasses leading LLM agents on O$^2$-QA. It also achieves SOTA results on various closed-ended QA benchmarks against similarly-sized models, while performing on par with much larger ones.
Shuffle Mamba: State Space Models with Random Shuffle for Multi-Modal Image Fusion
Sep 03, 2024



Multi-modal image fusion integrates complementary information from different modalities to produce enhanced and informative images. Although State-Space Models, such as Mamba, are proficient in long-range modeling with linear complexity, most Mamba-based approaches use fixed scanning strategies, which can introduce biased prior information. To mitigate this issue, we propose a novel Bayesian-inspired scanning strategy called Random Shuffle, supplemented by an theoretically-feasible inverse shuffle to maintain information coordination invariance, aiming to eliminate biases associated with fixed sequence scanning. Based on this transformation pair, we customized the Shuffle Mamba Framework, penetrating modality-aware information representation and cross-modality information interaction across spatial and channel axes to ensure robust interaction and an unbiased global receptive field for multi-modal image fusion. Furthermore, we develop a testing methodology based on Monte-Carlo averaging to ensure the model's output aligns more closely with expected results. Extensive experiments across multiple multi-modal image fusion tasks demonstrate the effectiveness of our proposed method, yielding excellent fusion quality over state-of-the-art alternatives. Code will be available upon acceptance.
Training-Free Large Model Priors for Multiple-in-One Image Restoration
Jul 18, 2024Image restoration aims to reconstruct the latent clear images from their degraded versions. Despite the notable achievement, existing methods predominantly focus on handling specific degradation types and thus require specialized models, impeding real-world applications in dynamic degradation scenarios. To address this issue, we propose Large Model Driven Image Restoration framework (LMDIR), a novel multiple-in-one image restoration paradigm that leverages the generic priors from large multi-modal language models (MMLMs) and the pretrained diffusion models. In detail, LMDIR integrates three key prior knowledges: 1) global degradation knowledge from MMLMs, 2) scene-aware contextual descriptions generated by MMLMs, and 3) fine-grained high-quality reference images synthesized by diffusion models guided by MMLM descriptions. Standing on above priors, our architecture comprises a query-based prompt encoder, degradation-aware transformer block injecting global degradation knowledge, content-aware transformer block incorporating scene description, and reference-based transformer block incorporating fine-grained image priors. This design facilitates single-stage training paradigm to address various degradations while supporting both automatic and user-guided restoration. Extensive experiments demonstrate that our designed method outperforms state-of-the-art competitors on multiple evaluation benchmarks.
Pan-Mamba: Effective pan-sharpening with State Space Model
Feb 19, 2024



Pan-sharpening involves integrating information from lowresolution multi-spectral and high-resolution panchromatic images to generate high-resolution multi-spectral counterparts. While recent advancements in the state space model, particularly the efficient long-range dependency modeling achieved by Mamba, have revolutionized computer vision community, its untapped potential in pan-sharpening motivates our exploration. Our contribution, Pan-Mamba, represents a novel pansharpening network that leverages the efficiency of the Mamba model in global information modeling. In Pan-Mamba, we customize two core components: channel swapping Mamba and cross-modal Mamba, strategically designed for efficient cross-modal information exchange and fusion. The former initiates a lightweight cross-modal interaction through the exchange of partial panchromatic and multispectral channels, while the latter facilities the information representation capability by exploiting inherent cross-modal relationships. Through extensive experiments across diverse datasets, our proposed approach surpasses state-of-theart methods, showcasing superior fusion results in pan-sharpening. To the best of our knowledge, this work is the first attempt in exploring the potential of the Mamba model and establishes a new frontier in the pan-sharpening techniques. The source code is available at https://github.com/alexhe101/Pan-Mamba .
Frequency-Adaptive Pan-Sharpening with Mixture of Experts
Jan 04, 2024Pan-sharpening involves reconstructing missing high-frequency information in multi-spectral images with low spatial resolution, using a higher-resolution panchromatic image as guidance. Although the inborn connection with frequency domain, existing pan-sharpening research has not almost investigated the potential solution upon frequency domain. To this end, we propose a novel Frequency Adaptive Mixture of Experts (FAME) learning framework for pan-sharpening, which consists of three key components: the Adaptive Frequency Separation Prediction Module, the Sub-Frequency Learning Expert Module, and the Expert Mixture Module. In detail, the first leverages the discrete cosine transform to perform frequency separation by predicting the frequency mask. On the basis of generated mask, the second with low-frequency MOE and high-frequency MOE takes account for enabling the effective low-frequency and high-frequency information reconstruction. Followed by, the final fusion module dynamically weights high-frequency and low-frequency MOE knowledge to adapt to remote sensing images with significant content variations. Quantitative and qualitative experiments over multiple datasets demonstrate that our method performs the best against other state-of-the-art ones and comprises a strong generalization ability for real-world scenes. Code will be made publicly at \url{https://github.com/alexhe101/FAME-Net}.
Panchromatic and Multispectral Image Fusion via Alternating Reverse Filtering Network
Oct 15, 2022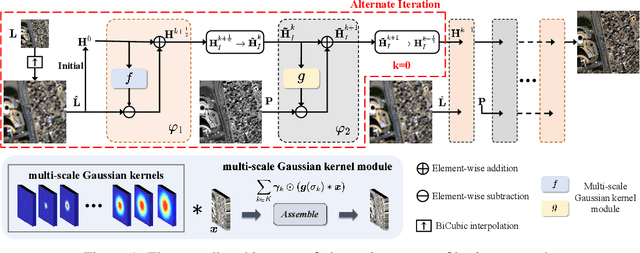
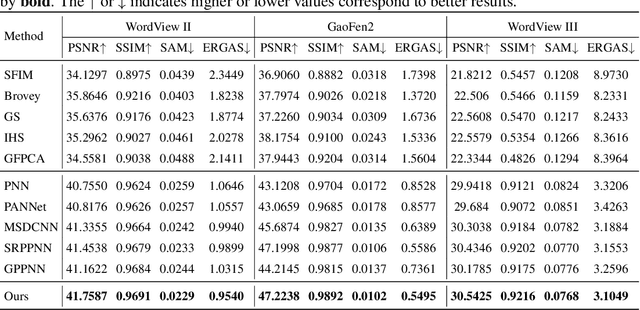
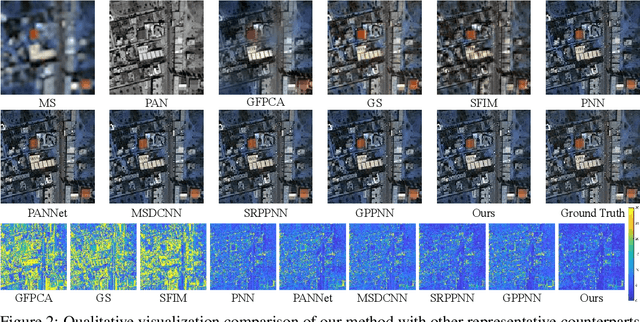

Panchromatic (PAN) and multi-spectral (MS) image fusion, named Pan-sharpening, refers to super-resolve the low-resolution (LR) multi-spectral (MS) images in the spatial domain to generate the expected high-resolution (HR) MS images, conditioning on the corresponding high-resolution PAN images. In this paper, we present a simple yet effective \textit{alternating reverse filtering network} for pan-sharpening. Inspired by the classical reverse filtering that reverses images to the status before filtering, we formulate pan-sharpening as an alternately iterative reverse filtering process, which fuses LR MS and HR MS in an interpretable manner. Different from existing model-driven methods that require well-designed priors and degradation assumptions, the reverse filtering process avoids the dependency on pre-defined exact priors. To guarantee the stability and convergence of the iterative process via contraction mapping on a metric space, we develop the learnable multi-scale Gaussian kernel module, instead of using specific filters. We demonstrate the theoretical feasibility of such formulations. Extensive experiments on diverse scenes to thoroughly verify the performance of our method, significantly outperforming the state of the arts.