 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIRAL: A Closed-Loop Framework for Self-Improving Action World Models via Reflective Planning Agents
Mar 11, 2026We introduce SPIRAL, a self-improving planning and iterative reflective action world modeling closed-loop framework that enables controllable long-horizon video generation conditioned on high-level semantic actions. Existing one-shot video generation models operate in open-loop, often resulting in incomplete action execution, weak semantic grounding, and temporal drift. SPIRAL formulates ActWM as a closed-loop think-act-reflect process, where generation proceeds step by step under explicit planning and feedback. A PlanAgent decomposes abstract actions into object-centric sub-actions, while a CriticAgent evaluates intermediate results and guides iterative refinement with long-horizon memory. This closed-loop design naturally supports RL evolving optimization, improving semantic alignment and temporal consistency over extended horizons. We further introduce the ActWM-Dataset and ActWM-Bench for training and evaluation. Experiments across multiple TI2V backbones demonstrate consistent gains on ActWM-Bench and mainstream video generation benchmarks, validating SPIRAL's effectiveness.
The Agent's First Day: Benchmarking Learning, Exploration, and Scheduling in the Workplace Scenarios
Jan 13, 2026The rapid evolution of Multi-modal Large Language Models (MLLMs) has advanced workflow automation; however, existing research mainly targets performance upper bounds in static environments, overlooking robustness for stochastic real-world deployment. We identify three key challenges: dynamic task scheduling, active exploration under uncertainty, and continuous learning from experience. To bridge this gap, we introduce \method{}, a dynamic evaluation environment that simulates a "trainee" agent continuously exploring a novel setting. Unlike traditional benchmarks, \method{} evaluates agents along three dimensions: (1) context-aware scheduling for streaming tasks with varying priorities; (2) prudent information acquisition to reduce hallucination via active exploration; and (3) continuous evolution by distilling generalized strategies from rule-based, dynamically generated tasks. Experiments show that cutting-edge agents have significant deficiencies in dynamic environments, especially in active exploration and continual learning. Our work establishes a framework for assessing agent reliability, shifting evaluation from static tests to realistic, production-oriented scenarios. Our codes are available at https://github.com/KnowledgeXLab/EvoEnv
Learning on the Job: An Experience-Driven Self-Evolving Agent for Long-Horizon Tasks
Oct 09, 2025Large Language Models have demonstrated remarkable capabilities across diverse domains, yet significant challenges persist when deploying them as AI agents for real-world long-horizon tasks. Existing LLM agents suffer from a critical limitation: they are test-time static and cannot learn from experience, lacking the ability to accumulate knowledge and continuously improve on the job. To address this challenge, we propose MUSE, a novel agent framework that introduces an experience-driven, self-evolving system centered around a hierarchical Memory Module. MUSE organizes diverse levels of experience and leverages them to plan and execute long-horizon tasks across multiple applications. After each sub-task execution, the agent autonomously reflects on its trajectory, converting the raw trajectory into structured experience and integrating it back into the Memory Module. This mechanism enables the agent to evolve beyond its static pretrained parameters, fostering continuous learning and self-evolution. We evaluate MUSE on the long-horizon productivity benchmark TAC. It achieves new SOTA performance by a significant margin using only a lightweight Gemini-2.5 Flash model. Sufficient Experiments demonstrate that as the agent autonomously accumulates experience, it exhibits increasingly superior task completion capabilities, as well as robust continuous learning and self-evolution capabilities. Moreover, the accumulated experience from MUSE exhibits strong generalization properties, enabling zero-shot improvement on new tasks. MUSE establishes a new paradigm for AI agents capable of real-world productivity task automation.
X-Scene: Large-Scale Driving Scene Generation with High Fidelity and Flexible Controllability
Jun 16, 2025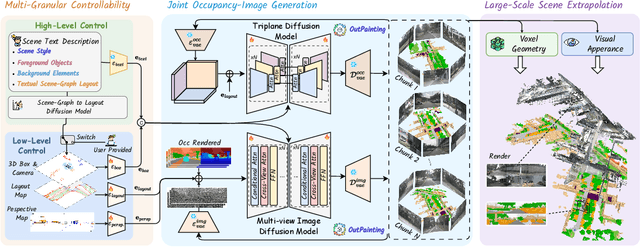

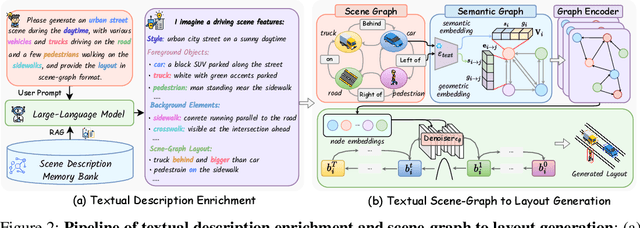
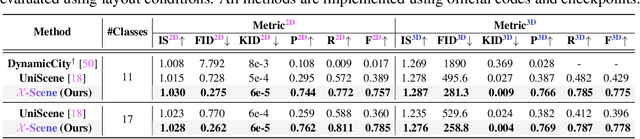
Diffusion models are advancing autonomous driving by enabling realistic data synthesis, predictive end-to-end planning, and closed-loop simulation, with a primary focus on temporally consistent generation. However, the generation of large-scale 3D scenes that require spatial coherence remains underexplored. In this paper, we propose X-Scene, a novel framework for large-scale driving scene generation that achieves both geometric intricacy and appearance fidelity, while offering flexible controllability. Specifically, X-Scene supports multi-granular control, including low-level conditions such as user-provided or text-driven layout for detailed scene composition and high-level semantic guidance such as user-intent and LLM-enriched text prompts for efficient customization. To enhance geometrical and visual fidelity, we introduce a unified pipeline that sequentially generates 3D semantic occupancy and the corresponding multiview images, while ensuring alignment between modalities. Additionally, we extend the generated local region into a large-scale scene through consistency-aware scene outpainting, which extrapolates new occupancy and images conditioned on the previously generated area, enhancing spatial continuity and preserving visual coherence. The resulting scenes are lifted into high-quality 3DGS representations, supporting diverse applications such as scene exploration. Comprehensive experiments demonstrate that X-Scene significantly advances controllability and fidelity for large-scale driving scene generation, empowering data generation and simulation for autonomous driving.
O$^2$-Searcher: A Searching-based Agent Model for Open-Domain Open-Ended Question Answering
May 22, 2025

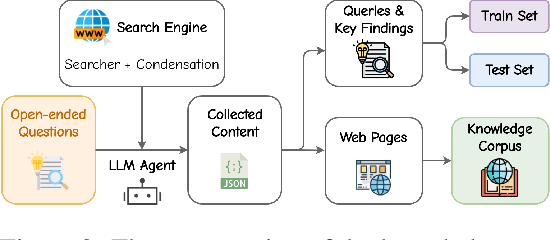

Large Language Models (LLMs), despite their advancements, are fundamentally limited by their static parametric knowledge, hindering performance on tasks requiring open-domain up-to-date information. While enabling LLMs to interact with external knowledge environments is a promising solution, current efforts primarily address closed-end problems. Open-ended questions, which characterized by lacking a standard answer or providing non-unique and diverse answers, remain underexplored. To bridge this gap, we present O$^2$-Searcher, a novel search agent leveraging reinforcement learning to effectively tackle both open-ended and closed-ended questions in the open domain. O$^2$-Searcher leverages an efficient, locally simulated search environment for dynamic knowledge acquisition, effectively decoupling the external world knowledge from model's sophisticated reasoning processes. It employs a unified training mechanism with meticulously designed reward functions, enabling the agent to identify problem types and adapt different answer generation strategies. Furthermore, to evaluate performance on complex open-ended tasks, we construct O$^2$-QA, a high-quality benchmark featuring 300 manually curated, multi-domain open-ended questions with associated web page caches. Extensive experiments show that O$^2$-Searcher, using only a 3B model, significantly surpasses leading LLM agents on O$^2$-QA. It also achieves SOTA results on various closed-ended QA benchmarks against similarly-sized models, while performing on par with much larger ones.
LeapVAD: A Leap in Autonomous Driving via Cognitive Perception and Dual-Process Thinking
Jan 14, 2025



While autonomous driving technology has made remarkable strides, data-driven approaches still struggle with complex scenarios due to their limited reasoning capabilities. Meanwhile, knowledge-driven autonomous driving systems have evolved considerably with the popularization of visual language models. In this paper, we propose LeapVAD, a novel method based on cognitive perception and dual-process thinking. Our approach implements a human-attentional mechanism to identify and focus on critical traffic elements that influence driving decisions. By characterizing these objects through comprehensive attributes - including appearance, motion patterns, and associated risks - LeapVAD achieves more effective environmental representation and streamlines the decision-making process. Furthermore, LeapVAD incorporates an innovative dual-process decision-making module miming the human-driving learning process. The system consists of an Analytic Process (System-II) that accumulates driving experience through logical reasoning and a Heuristic Process (System-I) that refines this knowledge via fine-tuning and few-shot learning. LeapVAD also includes reflective mechanisms and a growing memory bank, enabling it to learn from past mistakes and continuously improve its performance in a closed-loop environment. To enhance efficiency, we develop a scene encoder network that generates compact scene representations for rapid retrieval of relevant driving experiences. Extensive evaluations conducted on two leading autonomous driving simulators, CARLA and DriveArena, demonstrate that LeapVAD achieves superior performance compared to camera-only approaches despite limited training data. Comprehensive ablation studies further emphasize its effectiveness in continuous learning and domain adaptation. Project page: https://pjlab-adg.github.io/LeapVAD/.
DreamForge: Motion-Aware Autoregressive Video Generation for Multi-View Driving Scenes
Sep 06, 2024



Recent advances in diffusion models have significantly enhanced the cotrollable generation of streetscapes for and facilitated downstream perception and planning tasks. However, challenges such as maintaining temporal coherence, generating long videos, and accurately modeling driving scenes persist. Accordingly, we propose DreamForge, an advanced diffusion-based autoregressive video generation model designed for the long-term generation of 3D-controllable and extensible video. In terms of controllability, our DreamForge supports flexible conditions such as text descriptions, camera poses, 3D bounding boxes, and road layouts, while also providing perspective guidance to produce driving scenes that are both geometrically and contextually accurate. For consistency, we ensure inter-view consistency through cross-view attention and temporal coherence via an autoregressive architecture enhanced with motion cues. Codes will be available at https://github.com/PJLab-ADG/DriveArena.
DQFormer: Towards Unified LiDAR Panoptic Segmentation with Decoupled Queries
Aug 28, 2024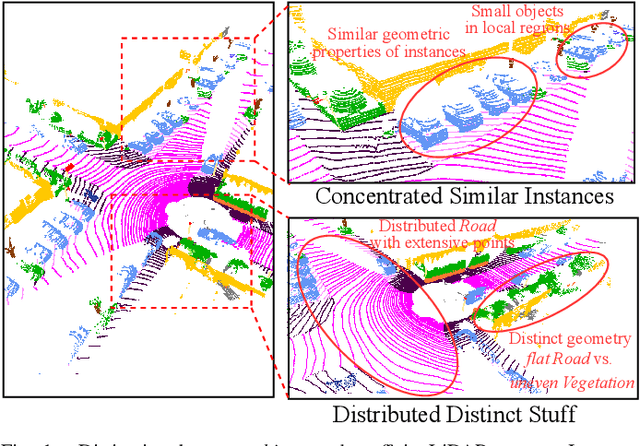
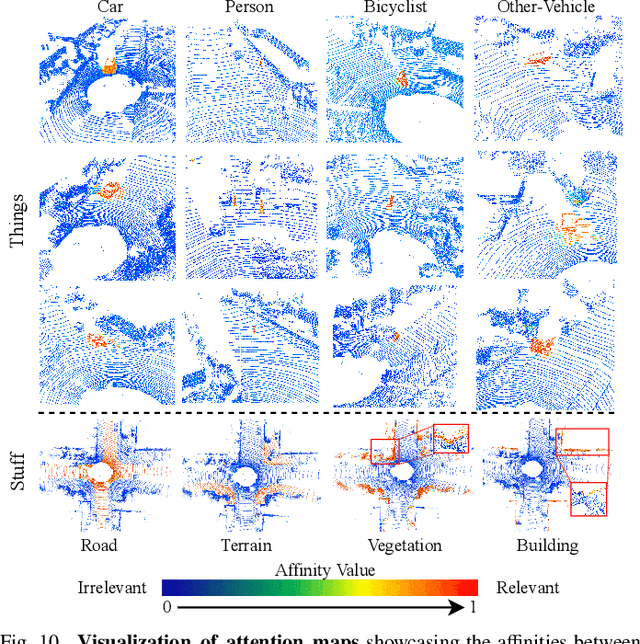
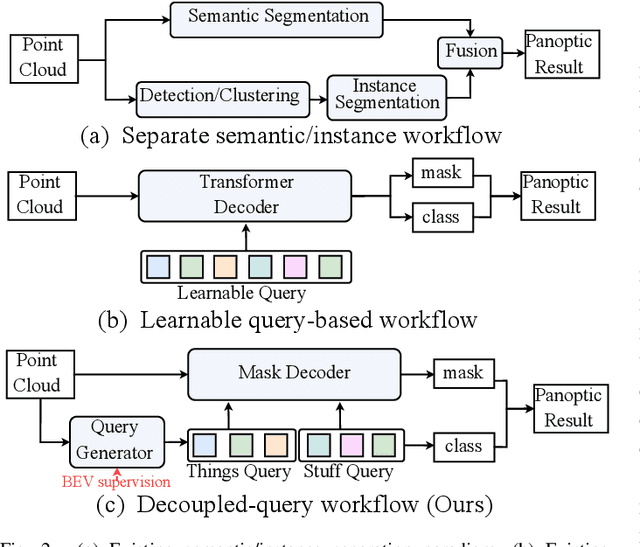
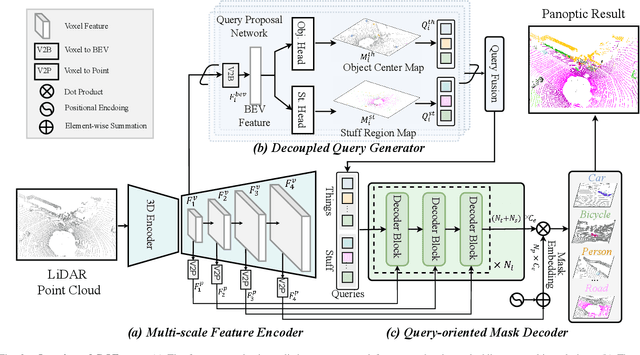
LiDAR panoptic segmentation, which jointly performs instance and semantic segmentation for things and stuff classes, plays a fundamental role in LiDAR perception tasks. While most existing methods explicitly separate these two segmentation tasks and utilize different branches (i.e., semantic and instance branches), some recent methods have embraced the query-based paradigm to unify LiDAR panoptic segmentation. However, the distinct spatial distribution and inherent characteristics of objects(things) and their surroundings(stuff) in 3D scenes lead to challenges, including the mutual competition of things/stuff and the ambiguity of classification/segmentation. In this paper, we propose decoupling things/stuff queries according to their intrinsic properties for individual decoding and disentangling classification/segmentation to mitigate ambiguity. To this end, we propose a novel framework dubbed DQFormer to implement semantic and instance segmentation in a unified workflow. Specifically, we design a decoupled query generator to propose informative queries with semantics by localizing things/stuff positions and fusing multi-level BEV embeddings. Moreover, a query-oriented mask decoder is introduced to decode corresponding segmentation masks by performing masked cross-attention between queries and mask embeddings. Finally, the decoded masks are combined with the semantics of the queries to produce panoptic results. Extensive experiments on nuScenes and SemanticKITTI datasets demonstrate the superiority of our DQFormer framework.
Driving in the Occupancy World: Vision-Centric 4D Occupancy Forecasting and Planning via World Models for Autonomous Driving
Aug 26, 2024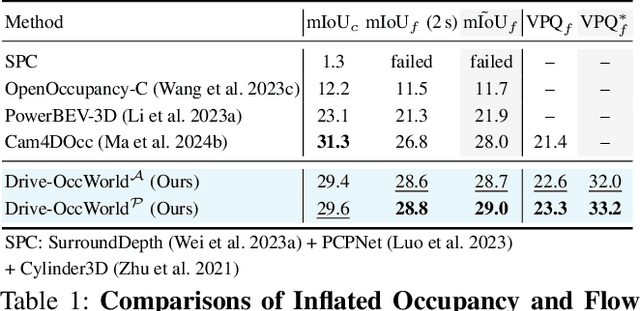
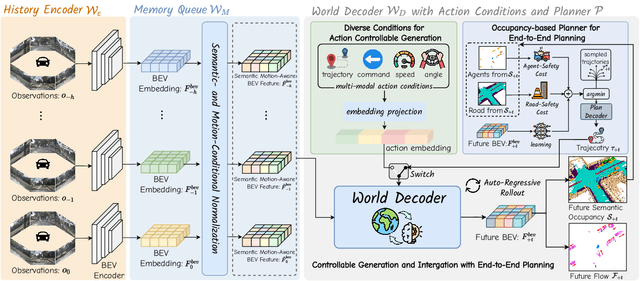
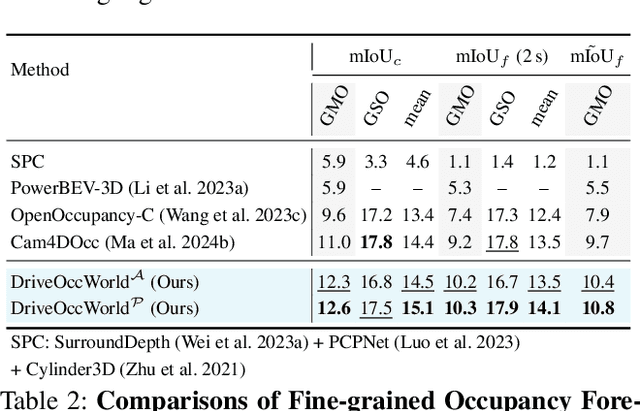
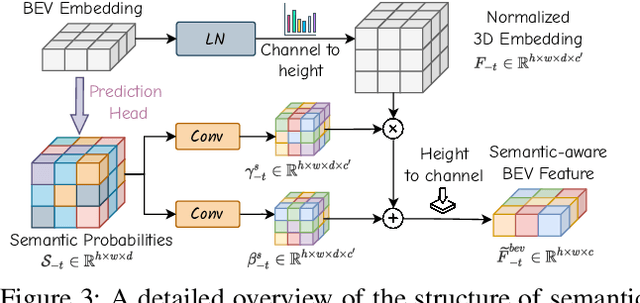
World models envision potential future states based on various ego actions. They embed extensive knowledge about the driving environment, facilitating safe and scalable autonomous driving. Most existing methods primarily focus on either data generation or the pretraining paradigms of world models. Unlike the aforementioned prior works, we propose Drive-OccWorld, which adapts a vision-centric 4D forecasting world model to end-to-end planning for autonomous driving. Specifically, we first introduce a semantic and motion-conditional normalization in the memory module, which accumulates semantic and dynamic information from historical BEV embeddings. These BEV features are then conveyed to the world decoder for future occupancy and flow forecasting, considering both geometry and spatiotemporal modeling. Additionally, we propose injecting flexible action conditions, such as velocity, steering angle, trajectory, and commands, into the world model to enable controllable generation and facilitate a broader range of downstream applications. Furthermore, we explore integrating the generative capabilities of the 4D world model with end-to-end planning, enabling continuous forecasting of future states and the selection of optimal trajectories using an occupancy-based cost function. Extensive experiments on the nuScenes dataset demonstrate that our method can generate plausible and controllable 4D occupancy, opening new avenues for driving world generation and end-to-end planning.
DriveArena: A Closed-loop Generative Simulation Platform for Autonomous Driving
Aug 01, 2024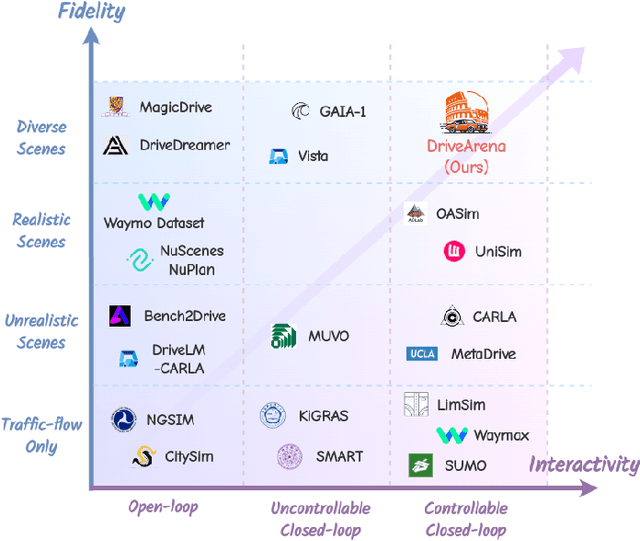

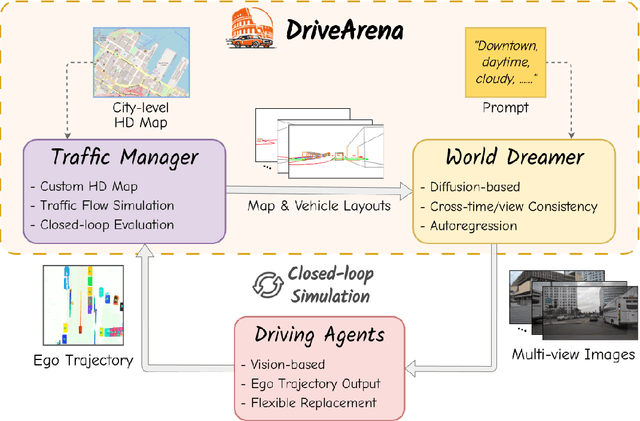

This paper presented DriveArena, the first high-fidelity closed-loop simulation system designed for driving agents navigating in real scenarios. DriveArena features a flexible, modular architecture, allowing for the seamless interchange of its core components: Traffic Manager, a traffic simulator capable of generating realistic traffic flow on any worldwide street map, and World Dreamer, a high-fidelity conditional generative model with infinite autoregression. This powerful synergy empowers any driving agent capable of processing real-world images to navigate in DriveArena's simulated environment. The agent perceives its surroundings through images generated by World Dreamer and output trajectories. These trajectories are fed into Traffic Manager, achieving realistic interactions with other vehicles and producing a new scene layout. Finally, the latest scene layout is relayed back into World Dreamer, perpetuating the simulation cycle. This iterative process fosters closed-loop exploration within a highly realistic environment, providing a valuable platform for developing and evaluating driving agents across diverse and challenging scenarios. DriveArena signifies a substantial leap forward in leveraging generative image data for the driving simulation platform, opening insights for closed-loop autonomous driving. Code will be available soon on GitHub: https://github.com/PJLab-ADG/DriveArena