 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Agent Memory: Taxonomy, Techniques, and Applications
Feb 05, 2026Memory emerges as the core module in the Large Language Model (LLM)-based agents for long-horizon complex tasks (e.g., multi-turn dialogue, game playing, scientific discovery), where memory can enable knowledge accumulation, iterative reasoning and self-evolution. Among diverse paradigms, graph stands out as a powerful structure for agent memory due to the intrinsic capabilities to model relational dependencies, organize hierarchical information, and support efficient retrieval. This survey presents a comprehensive review of agent memory from the graph-based perspective. First, we introduce a taxonomy of agent memory, including short-term vs. long-term memory, knowledge vs. experience memory, non-structural vs. structural memory, with an implementation view of graph-based memory. Second, according to the life cycle of agent memory, we systematically analyze the key techniques in graph-based agent memory, covering memory extraction for transforming the data into the contents, storage for organizing the data efficiently, retrieval for retrieving the relevant contents from memory to support reasoning, and evolution for updating the contents in the memory. Third, we summarize the open-sourced libraries and benchmarks that support the development and evaluation of self-evolving agent memory. We also explore diverse application scenarios. Finally, we identify critical challenges and future research directions. This survey aims to offer actionable insights to advance the development of more efficient and reliable graph-based agent memory systems. All the related resources, including research papers, open-source data, and projects, are collected for the community in https://github.com/DEEP-PolyU/Awesome-GraphMemory.
Use Graph When It Needs: Efficiently and Adaptively Integrating Retrieval-Augmented Generation with Graphs
Feb 03, 2026Large language models (LLMs) often struggle with knowledge-intensive tasks due to hallucinations and outdated parametric knowledge. While Retrieval-Augmented Generation (RAG) addresses this by integrating external corpora, its effectiveness is limited by fragmented information in unstructured domain documents. Graph-augmented RAG (GraphRAG) emerged to enhance contextual reasoning through structured knowledge graphs, yet paradoxically underperforms vanilla RAG in real-world scenarios, exhibiting significant accuracy drops and prohibitive latency despite gains on complex queries. We identify the rigid application of GraphRAG to all queries, regardless of complexity, as the root cause. To resolve this, we propose an efficient and adaptive GraphRAG framework called EA-GraphRAG that dynamically integrates RAG and GraphRAG paradigms through syntax-aware complexity analysis. Our approach introduces: (i) a syntactic feature constructor that parses each query and extracts a set of structural features; (ii) a lightweight complexity scorer that maps these features to a continuous complexity score; and (iii) a score-driven routing policy that selects dense RAG for low-score queries, invokes graph-based retrieval for high-score queries, and applies complexity-aware reciprocal rank fusion to handle borderline cases. Extensive experiments on a comprehensive benchmark, consisting of two single-hop and two multi-hop QA benchmarks, demonstrate that our EA-GraphRAG significantly improves accuracy, reduces latency, and achieves state-of-the-art performance in handling mixed scenarios involving both simple and complex queries.
You Don't Need Pre-built Graphs for RAG: Retrieval Augmented Generation with Adaptive Reasoning Structures
Aug 08, 2025Large language models (LLMs) often suffer from hallucination, generating factually incorrect statements when handling questions beyond their knowledge and perception. Retrieval-augmented generation (RAG) addresses this by retrieving query-relevant contexts from knowledge bases to support LLM reasoning. Recent advances leverage pre-constructed graphs to capture the relational connections among distributed documents, showing remarkable performance in complex tasks. However, existing Graph-based RAG (GraphRAG) methods rely on a costly process to transform the corpus into a graph, introducing overwhelming token cost and update latency. Moreover, real-world queries vary in type and complexity, requiring different logic structures for accurate reasoning. The pre-built graph may not align with these required structures, resulting in ineffective knowledge retrieval. To this end, we propose a \textbf{\underline{Logic}}-aware \textbf{\underline{R}}etrieval-\textbf{\underline{A}}ugmented \textbf{\underline{G}}eneration framework (\textbf{LogicRAG}) that dynamically extracts reasoning structures at inference time to guide adaptive retrieval without any pre-built graph. LogicRAG begins by decomposing the input query into a set of subproblems and constructing a directed acyclic graph (DAG) to model the logical dependencies among them. To support coherent multi-step reasoning, LogicRAG then linearizes the graph using topological sort, so that subproblems can be addressed in a logically consistent order. Besides, LogicRAG applies graph pruning to reduce redundant retrieval and uses context pruning to filter irrelevant context, significantly reducing the overall token cost. Extensive experiments demonstrate that LogicRAG achieves both superior performance and efficiency compared to state-of-the-art baselines.
LAG: Logic-Augmented Generation from a Cartesian Perspective
Aug 07, 2025Large language models (LLMs) have demonstrated remarkable capabilities across a wide range of tasks, yet exhibit critical limitations in knowledge-intensive tasks, often generating hallucinations when faced with questions requiring specialized expertise. While retrieval-augmented generation (RAG) mitigates this by integrating external knowledge, it struggles with complex reasoning scenarios due to its reliance on direct semantic retrieval and lack of structured logical organization. Inspired by Cartesian principles from \textit{Discours de la m\'ethode}, this paper introduces Logic-Augmented Generation (LAG), a novel paradigm that reframes knowledge augmentation through systematic question decomposition and dependency-aware reasoning. Specifically, LAG first decomposes complex questions into atomic sub-questions ordered by logical dependencies. It then resolves these sequentially, using prior answers to guide context retrieval for subsequent sub-questions, ensuring stepwise grounding in logical chain. To prevent error propagation, LAG incorporates a logical termination mechanism that halts inference upon encountering unanswerable sub-questions and reduces wasted computation on excessive reasoning. Finally, it synthesizes all sub-resolutions to generate verified responses. Experiments on four benchmark datasets demonstrate that LAG significantly enhances reasoning robustness, reduces hallucination, and aligns LLM problem-solving with human cognition, offering a principled alternative to existing RAG systems.
Reliable Reasoning Path: Distilling Effective Guidance for LLM Reasoning with Knowledge Graphs
Jun 12, 2025Large language models (LLMs) often struggle with knowledge-intensive tasks due to a lack of background knowledge and a tendency to hallucinate. To address these limitations, integrating knowledge graphs (KGs) with LLMs has been intensively studied. Existing KG-enhanced LLMs focus on supplementary factual knowledge, but still struggle with solving complex questions. We argue that refining the relationships among facts and organizing them into a logically consistent reasoning path is equally important as factual knowledge itself. Despite their potential, extracting reliable reasoning paths from KGs poses the following challenges: the complexity of graph structures and the existence of multiple generated paths, making it difficult to distinguish between useful and redundant ones. To tackle these challenges, we propose the RRP framework to mine the knowledge graph, which combines the semantic strengths of LLMs with structural information obtained through relation embedding and bidirectional distribution learning. Additionally, we introduce a rethinking module that evaluates and refines reasoning paths according to their significance. Experimental results on two public datasets show that RRP achieves state-of-the-art performance compared to existing baseline methods. Moreover, RRP can be easily integrated into various LLMs to enhance their reasoning abilities in a plug-and-play manner. By generating high-quality reasoning paths tailored to specific questions, RRP distills effective guidance for LLM reasoning.
FaithfulRAG: Fact-Level Conflict Modeling for Context-Faithful Retrieval-Augmented Generation
Jun 10, 2025



Large language models (LLMs) augmented with retrieval systems have demonstrated significant potential in handling knowledge-intensive tasks. However, these models often struggle with unfaithfulness issues, generating outputs that either ignore the retrieved context or inconsistently blend it with the LLM`s parametric knowledge. This issue is particularly severe in cases of knowledge conflict, where the retrieved context conflicts with the model`s parametric knowledge. While existing faithful RAG approaches enforce strict context adherence through well-designed prompts or modified decoding strategies, our analysis reveals a critical limitation: they achieve faithfulness by forcibly suppressing the model`s parametric knowledge, which undermines the model`s internal knowledge structure and increases the risk of misinterpreting the context. To this end, this paper proposes FaithfulRAG, a novel framework that resolves knowledge conflicts by explicitly modeling discrepancies between the model`s parametric knowledge and retrieved context. Specifically, FaithfulRAG identifies conflicting knowledge at the fact level and designs a self-thinking process, allowing LLMs to reason about and integrate conflicting facts before generating responses. Extensive experiments demonstrate that our method outperforms state-of-the-art methods. The code is available at https:// github.com/DeepLearnXMU/Faithful-RAG
Graph-defined Language Learning with LLMs
Jan 20, 2025



Recent efforts leverage Large Language Models (LLMs) for modeling text-attributed graph structures in node classification tasks. These approaches describe graph structures for LLMs to understand or aggregate LLM-generated textual attribute embeddings through graph structure. However, these approaches face two main limitations in modeling graph structures with LLMs. (i) Graph descriptions become verbose in describing high-order graph structure. (ii) Textual attributes alone do not contain adequate graph structure information. It is challenging to model graph structure concisely and adequately with LLMs. LLMs lack built-in mechanisms to model graph structures directly. They also struggle with complex long-range dependencies between high-order nodes and target nodes. Inspired by the observation that LLMs pre-trained on one language can achieve exceptional performance on another with minimal additional training, we propose \textbf{G}raph-\textbf{D}efined \textbf{L}anguage for \textbf{L}arge \textbf{L}anguage \textbf{M}odel (GDL4LLM). This novel framework enables LLMs to transfer their powerful language understanding capabilities to graph-structured data. GDL4LLM translates graphs into a graph language corpus instead of graph descriptions and pre-trains LLMs on this corpus to adequately understand graph structures. During fine-tuning, this corpus describes the structural information of target nodes concisely with only a few tokens. By treating graphs as a new language, GDL4LLM enables LLMs to model graph structures adequately and concisely for node classification tasks. Extensive experiments on three real-world datasets demonstrate that GDL4LLM outperforms description-based and textual attribute embeddings-based baselines by efficiently modeling different orders of graph structure with LLMs.
Benchmarking Large Language Models via Random Variables
Jan 20, 2025With the continuous advancement of large language models (LLMs) in mathematical reasoning, evaluating their performance in this domain has become a prominent research focus. Recent studies have raised concerns about the reliability of current mathematical benchmarks, highlighting issues such as simplistic design and potential data leakage. Therefore, creating a reliable benchmark that effectively evaluates the genuine capabilities of LLMs in mathematical reasoning remains a significant challenge. To address this, we propose RV-Bench, a framework for Benchmarking LLMs via Random Variables in mathematical reasoning. Specifically, the background content of a random variable question (RV question) mirrors the original problem in existing standard benchmarks, but the variable combinations are randomized into different values. LLMs must fully understand the problem-solving process for the original problem to correctly answer RV questions with various combinations of variable values. As a result, the LLM's genuine capability in mathematical reasoning is reflected by its accuracy on RV-Bench. Extensive experiments are conducted with 29 representative LLMs across 900+ RV questions. A leaderboard for RV-Bench ranks the genuine capability of these LLMs. Further analysis of accuracy dropping indicates that current LLMs still struggle with complex mathematical reasoning problems.
RANSAC Back to SOTA: A Two-stage Consensus Filtering for Real-time 3D Registration
Oct 21, 2024



Correspondence-based point cloud registration (PCR) plays a key role in robotics and computer vision. However, challenges like sensor noises, object occlusions, and descriptor limitations inevitably result in numerous outliers. RANSAC family is the most popular outlier removal solution. However, the requisite iterations escalate exponentially with the outlier ratio, rendering it far inferior to existing methods (SC2PCR [1], MAC [2], etc.) in terms of accuracy or speed. Thus, we propose a two-stage consensus filtering (TCF) that elevates RANSAC to state-of-the-art (SOTA) speed and accuracy. Firstly, one-point RANSAC obtains a consensus set based on length consistency. Subsequently, two-point RANSAC refines the set via angle consistency. Then, three-point RANSAC computes a coarse pose and removes outliers based on transformed correspondence's distances. Drawing on optimizations from one-point and two-point RANSAC, three-point RANSAC requires only a few iterations. Eventually, an iterative reweighted least squares (IRLS) is applied to yield the optimal pose. Experiments on the large-scale KITTI and ETH datasets demonstrate our method achieves up to three-orders-of-magnitude speedup compared to MAC while maintaining registration accuracy and recall. Our code is available at https://github.com/ShiPC-AI/TCF.
DQFormer: Towards Unified LiDAR Panoptic Segmentation with Decoupled Queries
Aug 28, 2024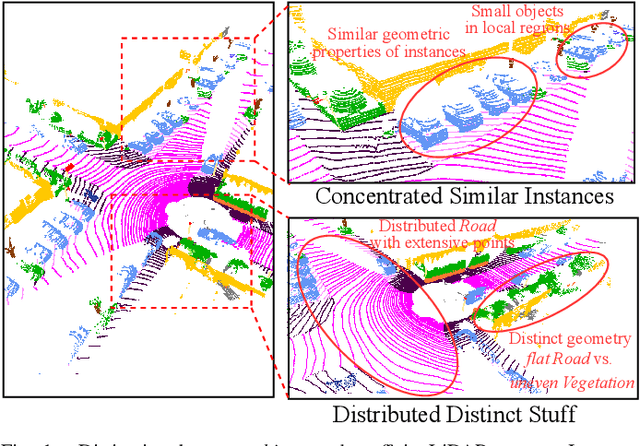
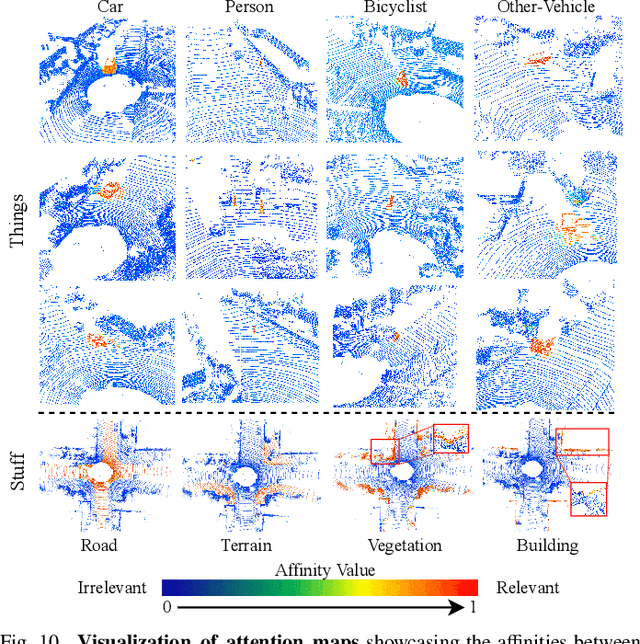
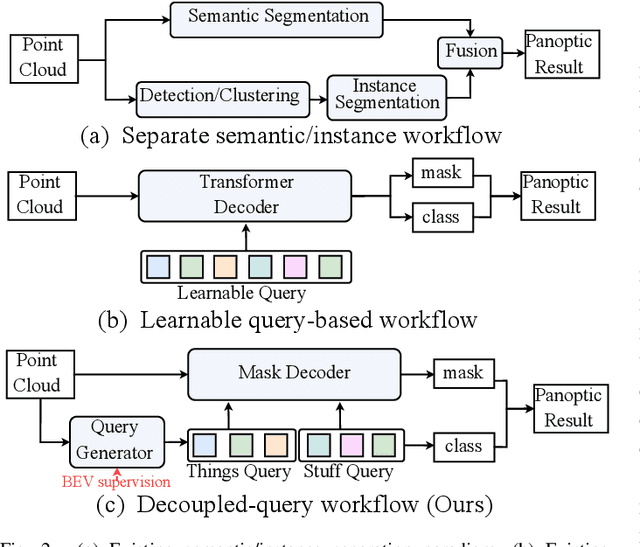
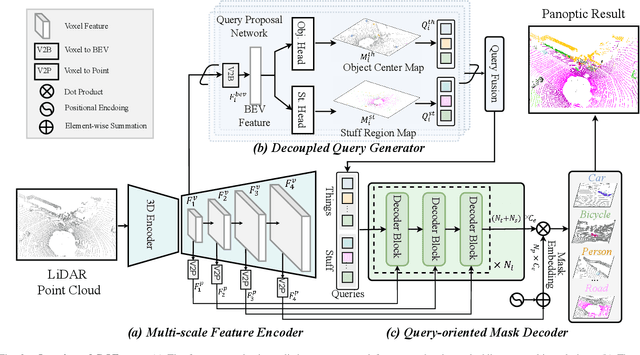
LiDAR panoptic segmentation, which jointly performs instance and semantic segmentation for things and stuff classes, plays a fundamental role in LiDAR perception tasks. While most existing methods explicitly separate these two segmentation tasks and utilize different branches (i.e., semantic and instance branches), some recent methods have embraced the query-based paradigm to unify LiDAR panoptic segmentation. However, the distinct spatial distribution and inherent characteristics of objects(things) and their surroundings(stuff) in 3D scenes lead to challenges, including the mutual competition of things/stuff and the ambiguity of classification/segmentation. In this paper, we propose decoupling things/stuff queries according to their intrinsic properties for individual decoding and disentangling classification/segmentation to mitigate ambiguity. To this end, we propose a novel framework dubbed DQFormer to implement semantic and instance segmentation in a unified workflow. Specifically, we design a decoupled query generator to propose informative queries with semantics by localizing things/stuff positions and fusing multi-level BEV embeddings. Moreover, a query-oriented mask decoder is introduced to decode corresponding segmentation masks by performing masked cross-attention between queries and mask embeddings. Finally, the decoded masks are combined with the semantics of the queries to produce panoptic results. Extensive experiments on nuScenes and SemanticKITTI datasets demonstrate the superiority of our DQFormer framework.