 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeULF-Loc: Unbiased Landmark Feature for Robust Visual Localization with 3D Gaussian Splatting
May 06, 2026Visual localization is a core technology for augmented reality and autonomous navigation. Recent methods combine the efficient rendering of 3D Gaussian Splatting (3DGS) with feature-based localization. These methods rely on direct matching between 2D query features and the 3D Gaussian feature field, but this often results in mismatches due to an inherent bias in the learned Gaussian feature. We theoretically analyze the feature learning process in 3DGS, revealing that the widely adopted $α$-blending optimization inherently introduces bias into 3D point features. This bias stems from the entanglement between individual Gaussians and their neighboring Gaussians, making the learned features unsuitable for precise matching tasks. Motivated by these findings, we propose ULF-Loc, an unbiased landmark feature framework that replaces biased feature optimization with geometry-weighted feature fusion. We further introduce keypoint-consensus landmark sampling to select reliable Gaussians and local geometric consistency verification to reject mismatches caused by rendering artifacts. On the Cambridge Landmarks dataset, ULF-Loc reduces the mean median translation error by 17\% compared to the state-of-the-art, while achieving superior efficiency with only 1/10 the training time and 1/6 the GPU memory of STDLoc.
VitaTouch: Property-Aware Vision-Tactile-Language Model for Robotic Quality Inspection in Manufacturing
Apr 02, 2026Quality inspection in smart manufacturing requires identifying intrinsic material and surface properties beyond visible geometry, yet vision-only methods remain vulnerable to occlusion and reflection. We propose VitaTouch, a property-aware vision-tactile-language model for material-property inference and natural-language attribute description. VitaTouch uses modality-specific encoders and a dual Q-Former to extract language-relevant visual and tactile features, which are compressed into prefix tokens for a large language model. We align each modality with text and explicitly couple vision and touch through contrastive learning. We also construct VitaSet, a multimodal dataset with 186 objects, 52k images, and 5.1k human-verified instruction-answer pairs. VitaTouch achieves the best performance on HCT and the overall TVL benchmark, while remaining competitive on SSVTP. On VitaSet, it reaches 88.89% hardness accuracy, 75.13% roughness accuracy, and 54.81% descriptor recall; the material-description task further achieves a peak semantic similarity of 0.9009. With LoRA-based fine-tuning, VitaTouch attains 100.0%, 96.0%, and 92.0% accuracy for 2-, 3-, and 5-category defect recognition, respectively, and delivers 94.0% closed-loop recognition accuracy and 94.0% end-to-end sorting success in 100 laboratory robotic trials. More details are available at the project page: https://vitatouch.github.io/
Memory-Guided View Refinement for Dynamic Human-in-the-loop EQA
Mar 10, 2026Embodied Question Answering (EQA) has traditionally been evaluated in temporally stable environments where visual evidence can be accumulated reliably. However, in dynamic, human-populated scenes, human activities and occlusions introduce significant perceptual non-stationarity: task-relevant cues are transient and view-dependent, while a store-then-retrieve strategy over-accumulates redundant evidence and increases inference cost. This setting exposes two practical challenges for EQA agents: resolving ambiguity caused by viewpoint-dependent occlusions, and maintaining compact yet up-to-date evidence for efficient inference. To enable systematic study of this setting, we introduce DynHiL-EQA, a human-in-the-loop EQA dataset with two subsets: a Dynamic subset featuring human activities and temporal changes, and a Static subset with temporally stable observations. To address the above challenges, we present DIVRR (Dynamic-Informed View Refinement and Relevance-guided Adaptive Memory Selection), a training-free framework that couples relevance-guided view refinement with selective memory admission. By verifying ambiguous observations before committing them and retaining only informative evidence, DIVRR improves robustness under occlusions while preserving fast inference with compact memory. Extensive experiments on DynHiL-EQA and the established HM-EQA dataset demonstrate that DIVRR consistently improves over existing baselines in both dynamic and static settings while maintaining high inference efficiency.
Global Cross-Modal Geo-Localization: A Million-Scale Dataset and a Physical Consistency Learning Framework
Mar 09, 2026Cross-modal Geo-localization (CMGL) matches ground-level text descriptions with geo-tagged aerial imagery, which is crucial for pedestrian navigation and emergency response. However, existing researches are constrained by narrow geographic coverage and simplistic scene diversity, failing to reflect the immense spatial heterogeneity of global architectural styles and topographic features. To bridge this gap and facilitate universal positioning, we introduce CORE, the first million-scale dataset dedicated to global CMGL. CORE comprises 1,034,786 cross-view images sampled from 225 distinct geographic regions across all continents, offering an unprecedented variety of perspectives in varying environmental conditions and urban layouts. We leverage the zero-shot reasoning of Large Vision-Language Models (LVLMs) to synthesize high-quality scene descriptions rich in discriminative cues. Furthermore, we propose a physical-law-aware network (PLANET) for cross-modal geo-localization. PLANET introduces a novel contrastive learning paradigm to guide textual representations in capturing the intrinsic physical signatures of satellite imagery. Extensive experiments across varied geographic regions demonstrate that PLANet significantly outperforms state-of-the-art methods, establishing a new benchmark for robust, global-scale geo-localization. The dataset and source code will be released at https://github.com/YtH0823/CORE.
Any2Any: Unified Arbitrary Modality Translation for Remote Sensing
Mar 04, 2026Multi-modal remote sensing imagery provides complementary observations of the same geographic scene, yet such observations are frequently incomplete in practice. Existing cross-modal translation methods treat each modality pair as an independent task, resulting in quadratic complexity and limited generalization to unseen modality combinations. We formulate Any-to-Any translation as inference over a shared latent representation of the scene, where different modalities correspond to partial observations of the same underlying semantics. Based on this formulation, we propose Any2Any, a unified latent diffusion framework that projects heterogeneous inputs into a geometrically aligned latent space. Such structure performs anchored latent regression with a shared backbone, decoupling modality-specific representation learning from semantic mapping. Moreover, lightweight target-specific residual adapters are used to correct systematic latent mismatches without increasing inference complexity. To support learning under sparse but connected supervision, we introduce RST-1M, the first million-scale remote sensing dataset with paired observations across five sensing modalities, providing supervision anchors for any-to-any translation. Experiments across 14 translation tasks show that Any2Any consistently outperforms pairwise translation methods and exhibits strong zero-shot generalization to unseen modality pairs. Code and models will be available at https://github.com/MiliLab/Any2Any.
SOMA-1M: A Large-Scale SAR-Optical Multi-resolution Alignment Dataset for Multi-Task Remote Sensing
Feb 05, 2026Synthetic Aperture Radar (SAR) and optical imagery provide complementary strengths that constitute the critical foundation for transcending single-modality constraints and facilitating cross-modal collaborative processing and intelligent interpretation. However, existing benchmark datasets often suffer from limitations such as single spatial resolution, insufficient data scale, and low alignment accuracy, making them inadequate for supporting the training and generalization of multi-scale foundation models. To address these challenges, we introduce SOMA-1M (SAR-Optical Multi-resolution Alignment), a pixel-level precisely aligned dataset containing over 1.3 million pairs of georeferenced images with a specification of 512 x 512 pixels. This dataset integrates imagery from Sentinel-1, PIESAT-1, Capella Space, and Google Earth, achieving global multi-scale coverage from 0.5 m to 10 m. It encompasses 12 typical land cover categories, effectively ensuring scene diversity and complexity. To address multimodal projection deformation and massive data registration, we designed a rigorous coarse-to-fine image matching framework ensuring pixel-level alignment. Based on this dataset, we established comprehensive evaluation benchmarks for four hierarchical vision tasks, including image matching, image fusion, SAR-assisted cloud removal, and cross-modal translation, involving over 30 mainstream algorithms. Experimental results demonstrate that supervised training on SOMA-1M significantly enhances performance across all tasks. Notably, multimodal remote sensing image (MRSI) matching performance achieves current state-of-the-art (SOTA) levels. SOMA-1M serves as a foundational resource for robust multimodal algorithms and remote sensing foundation models. The dataset will be released publicly at: https://github.com/PeihaoWu/SOMA-1M.
Accurate Network Traffic Matrix Prediction via LEAD: an LLM-Enhanced Adapter-Based Conditional Diffusion Model
Jan 29, 2026Driven by the evolution toward 6G and AI-native edge intelligence, network operations increasingly require predictive and risk-aware adaptation under stringent computation and latency constraints. Network Traffic Matrix (TM), which characterizes flow volumes between nodes, is a fundamental signal for proactive traffic engineering. However, accurate TM forecasting remains challenging due to the stochastic, non-linear, and bursty nature of network dynamics. Existing discriminative models often suffer from over-smoothing and provide limited uncertainty awareness, leading to poor fidelity under extreme bursts. To address these limitations, we propose LEAD, a Large Language Model (LLM)-Enhanced Adapter-based conditional Diffusion model. First, LEAD adopts a "Traffic-to-Image" paradigm to transform traffic matrices into RGB images, enabling global dependency modeling via vision backbones. Then, we design a "Frozen LLM with Trainable Adapter" model, which efficiently captures temporal semantics with limited computational cost. Moreover, we propose a Dual-Conditioning Strategy to precisely guide a diffusion model to generate complex, dynamic network traffic matrices. Experiments on the Abilene and GEANT datasets demonstrate that LEAD outperforms all baselines. On the Abilene dataset, LEAD attains a remarkable 45.2% reduction in RMSE against the best baseline, with the error margin rising only marginally from 0.1098 at one-step to 0.1134 at 20-step predictions. Meanwhile, on the GEANT dataset, LEAD achieves a 0.0258 RMSE at 20-step prediction horizon which is 27.3% lower than the best baseline.
TurboReg: TurboClique for Robust and Efficient Point Cloud Registration
Jul 02, 2025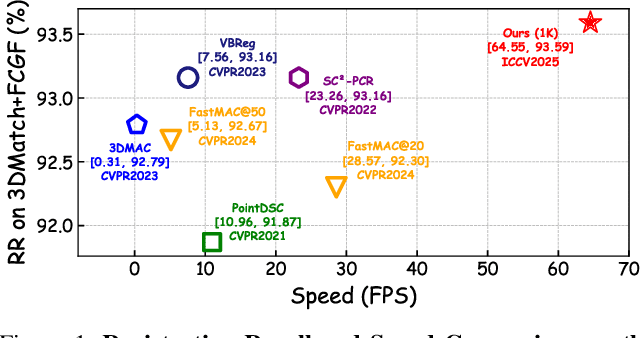
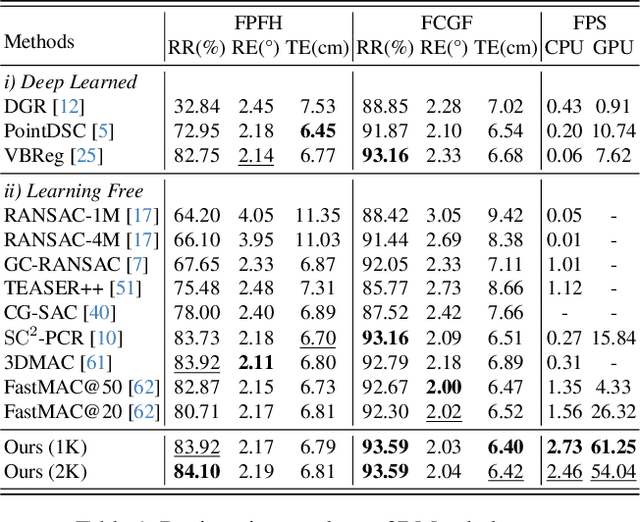


Robust estimation is essential in correspondence-based Point Cloud Registration (PCR). Existing methods using maximal clique search in compatibility graphs achieve high recall but suffer from exponential time complexity, limiting their use in time-sensitive applications. To address this challenge, we propose a fast and robust estimator, TurboReg, built upon a novel lightweight clique, TurboClique, and a highly parallelizable Pivot-Guided Search (PGS) algorithm. First, we define the TurboClique as a 3-clique within a highly-constrained compatibility graph. The lightweight nature of the 3-clique allows for efficient parallel searching, and the highly-constrained compatibility graph ensures robust spatial consistency for stable transformation estimation. Next, PGS selects matching pairs with high SC$^2$ scores as pivots, effectively guiding the search toward TurboCliques with higher inlier ratios. Moreover, the PGS algorithm has linear time complexity and is significantly more efficient than the maximal clique search with exponential time complexity. Extensive experiments show that TurboReg achieves state-of-the-art performance across multiple real-world datasets, with substantial speed improvements. For example, on the 3DMatch+FCGF dataset, TurboReg (1K) operates $208.22\times$ faster than 3DMAC while also achieving higher recall. Our code is accessible at \href{https://github.com/Laka-3DV/TurboReg}{\texttt{TurboReg}}.
Multi-Resolution SAR and Optical Remote Sensing Image Registration Methods: A Review, Datasets, and Future Perspectives
Feb 03, 2025



Synthetic Aperture Radar (SAR) and optical image registration is essential for remote sensing data fusion, with applications in military reconnaissance, environmental monitoring, and disaster management. However, challenges arise from differences in imaging mechanisms, geometric distortions, and radiometric properties between SAR and optical images. As image resolution increases, fine SAR textures become more significant, leading to alignment issues and 3D spatial discrepancies. Two major gaps exist: the lack of a publicly available multi-resolution, multi-scene registration dataset and the absence of systematic analysis of current methods. To address this, the MultiResSAR dataset was created, containing over 10k pairs of multi-source, multi-resolution, and multi-scene SAR and optical images. Sixteen state-of-the-art algorithms were tested. Results show no algorithm achieves 100% success, and performance decreases as resolution increases, with most failing on sub-meter data. XoFTR performs best among deep learning methods (40.58%), while RIFT performs best among traditional methods (66.51%). Future research should focus on noise suppression, 3D geometric fusion, cross-view transformation modeling, and deep learning optimization for robust registration of high-resolution SAR and optical images. The dataset is available at https://github.com/betterlll/Multi-Resolution-SAR-dataset-.
RANSAC Back to SOTA: A Two-stage Consensus Filtering for Real-time 3D Registration
Oct 21, 2024



Correspondence-based point cloud registration (PCR) plays a key role in robotics and computer vision. However, challenges like sensor noises, object occlusions, and descriptor limitations inevitably result in numerous outliers. RANSAC family is the most popular outlier removal solution. However, the requisite iterations escalate exponentially with the outlier ratio, rendering it far inferior to existing methods (SC2PCR [1], MAC [2], etc.) in terms of accuracy or speed. Thus, we propose a two-stage consensus filtering (TCF) that elevates RANSAC to state-of-the-art (SOTA) speed and accuracy. Firstly, one-point RANSAC obtains a consensus set based on length consistency. Subsequently, two-point RANSAC refines the set via angle consistency. Then, three-point RANSAC computes a coarse pose and removes outliers based on transformed correspondence's distances. Drawing on optimizations from one-point and two-point RANSAC, three-point RANSAC requires only a few iterations. Eventually, an iterative reweighted least squares (IRLS) is applied to yield the optimal pose. Experiments on the large-scale KITTI and ETH datasets demonstrate our method achieves up to three-orders-of-magnitude speedup compared to MAC while maintaining registration accuracy and recall. Our code is available at https://github.com/ShiPC-AI/TCF.