 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Cross-Modal Geo-Localization: A Million-Scale Dataset and a Physical Consistency Learning Framework
Mar 09, 2026Cross-modal Geo-localization (CMGL) matches ground-level text descriptions with geo-tagged aerial imagery, which is crucial for pedestrian navigation and emergency response. However, existing researches are constrained by narrow geographic coverage and simplistic scene diversity, failing to reflect the immense spatial heterogeneity of global architectural styles and topographic features. To bridge this gap and facilitate universal positioning, we introduce CORE, the first million-scale dataset dedicated to global CMGL. CORE comprises 1,034,786 cross-view images sampled from 225 distinct geographic regions across all continents, offering an unprecedented variety of perspectives in varying environmental conditions and urban layouts. We leverage the zero-shot reasoning of Large Vision-Language Models (LVLMs) to synthesize high-quality scene descriptions rich in discriminative cues. Furthermore, we propose a physical-law-aware network (PLANET) for cross-modal geo-localization. PLANET introduces a novel contrastive learning paradigm to guide textual representations in capturing the intrinsic physical signatures of satellite imagery. Extensive experiments across varied geographic regions demonstrate that PLANet significantly outperforms state-of-the-art methods, establishing a new benchmark for robust, global-scale geo-localization. The dataset and source code will be released at https://github.com/YtH0823/CORE.
RIFT2: Speeding-up RIFT with A New Rotation-Invariance Technique
Mar 01, 2023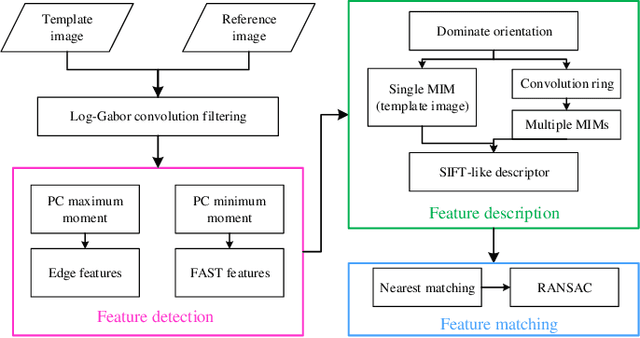



Multimodal image matching is an important prerequisite for multisource image information fusion. Compared with the traditional matching problem, multimodal feature matching is more challenging due to the severe nonlinear radiation distortion (NRD). Radiation-variation insensitive feature transform (RIFT)~\cite{li2019rift} has shown very good robustness to NRD and become a baseline method in multimodal feature matching. However, the high computational cost for rotation invariance largely limits its usage in practice. In this paper, we propose an improved RIFT method, called RIFT2. We develop a new rotation invariance technique based on dominant index value, which avoids the construction process of convolution sequence ring. Hence, it can speed up the running time and reduce the memory consumption of the original RIFT by almost 3 times in theory. Extensive experiments show that RIFT2 achieves similar matching performance to RIFT while being much faster and having less memory consumption. The source code will be made publicly available in \url{https://github.com/LJY-RS/RIFT2-multimodal-matching-rotation}
RIFT: Multi-modal Image Matching Based on Radiation-invariant Feature Transform
Apr 25, 2018



Traditional feature matching methods such as scale-invariant feature transform (SIFT) usually use image intensity or gradient information to detect and describe feature points; however, both intensity and gradient are sensitive to nonlinear radiation distortions (NRD). To solve the problem, this paper proposes a novel feature matching algorithm that is robust to large NRD. The proposed method is called radiation-invariant feature transform (RIFT). There are three main contributions in RIFT: first, RIFT uses phase congruency (PC) instead of image intensity for feature point detection. RIFT considers both the number and repeatability of feature points, and detects both corner points and edge points on the PC map. Second, RIFT originally proposes a maximum index map (MIM) for feature description. MIM is constructed from the log-Gabor convolution sequence and is much more robust to NRD than traditional gradient map. Thus, RIFT not only largely improves the stability of feature detection, but also overcomes the limitation of gradient information for feature description. Third, RIFT analyzes the inherent influence of rotations on the values of MIM, and realizes rotation invariance. We use six different types of multi-model image datasets to evaluate RIFT, including optical-optical, infrared-optical, synthetic aperture radar (SAR)-optical, depth-optical, map-optical, and day-night datasets. Experimental results show that RIFT is much more superior to SIFT and SAR-SIFT. To the best of our knowledge, RIFT is the first feature matching algorithm that can achieve good performance on all the above-mentioned types of multi-model images. The source code of RIFT and multi-modal remote sensing image datasets are made public .