 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQuest-Coder-V1 Technical Report
Mar 17, 2026In this report, we introduce the IQuest-Coder-V1 series-(7B/14B/40B/40B-Loop), a new family of code large language models (LLMs). Moving beyond static code representations, we propose the code-flow multi-stage training paradigm, which captures the dynamic evolution of software logic through different phases of the pipeline. Our models are developed through the evolutionary pipeline, starting with the initial pre-training consisting of code facts, repository, and completion data. Following that, we implement a specialized mid-training stage that integrates reasoning and agentic trajectories in 32k-context and repository-scale in 128k-context to forge deep logical foundations. The models are then finalized with post-training of specialized coding capabilities, which is bifurcated into two specialized paths: the thinking path (utilizing reasoning-driven RL) and the instruct path (optimized for general assistance). IQuest-Coder-V1 achieves state-of-the-art performance among competitive models across critical dimensions of code intelligence: agentic software engineering, competitive programming, and complex tool use. To address deployment constraints, the IQuest-Coder-V1-Loop variant introduces a recurrent mechanism designed to optimize the trade-off between model capacity and deployment footprint, offering an architecturally enhanced path for efficacy-efficiency trade-off. We believe the release of the IQuest-Coder-V1 series, including the complete white-box chain of checkpoints from pre-training bases to the final thinking and instruction models, will advance research in autonomous code intelligence and real-world agentic systems.
SOMA-1M: A Large-Scale SAR-Optical Multi-resolution Alignment Dataset for Multi-Task Remote Sensing
Feb 05, 2026Synthetic Aperture Radar (SAR) and optical imagery provide complementary strengths that constitute the critical foundation for transcending single-modality constraints and facilitating cross-modal collaborative processing and intelligent interpretation. However, existing benchmark datasets often suffer from limitations such as single spatial resolution, insufficient data scale, and low alignment accuracy, making them inadequate for supporting the training and generalization of multi-scale foundation models. To address these challenges, we introduce SOMA-1M (SAR-Optical Multi-resolution Alignment), a pixel-level precisely aligned dataset containing over 1.3 million pairs of georeferenced images with a specification of 512 x 512 pixels. This dataset integrates imagery from Sentinel-1, PIESAT-1, Capella Space, and Google Earth, achieving global multi-scale coverage from 0.5 m to 10 m. It encompasses 12 typical land cover categories, effectively ensuring scene diversity and complexity. To address multimodal projection deformation and massive data registration, we designed a rigorous coarse-to-fine image matching framework ensuring pixel-level alignment. Based on this dataset, we established comprehensive evaluation benchmarks for four hierarchical vision tasks, including image matching, image fusion, SAR-assisted cloud removal, and cross-modal translation, involving over 30 mainstream algorithms. Experimental results demonstrate that supervised training on SOMA-1M significantly enhances performance across all tasks. Notably, multimodal remote sensing image (MRSI) matching performance achieves current state-of-the-art (SOTA) levels. SOMA-1M serves as a foundational resource for robust multimodal algorithms and remote sensing foundation models. The dataset will be released publicly at: https://github.com/PeihaoWu/SOMA-1M.
REAL-Prover: Retrieval Augmented Lean Prover for Mathematical Reasoning
May 27, 2025Nowadays, formal theorem provers have made monumental progress on high-school and competition-level mathematics, but few of them generalize to more advanced mathematics. In this paper, we present REAL-Prover, a new open-source stepwise theorem prover for Lean 4 to push this boundary. This prover, based on our fine-tuned large language model (REAL-Prover-v1) and integrated with a retrieval system (Leansearch-PS), notably boosts performance on solving college-level mathematics problems. To train REAL-Prover-v1, we developed HERALD-AF, a data extraction pipeline that converts natural language math problems into formal statements, and a new open-source Lean 4 interactive environment (Jixia-interactive) to facilitate synthesis data collection. In our experiments, our prover using only supervised fine-tune achieves competitive results with a 23.7% success rate (Pass@64) on the ProofNet dataset-comparable to state-of-the-art (SOTA) models. To further evaluate our approach, we introduce FATE-M, a new benchmark focused on algebraic problems, where our prover achieves a SOTA success rate of 56.7% (Pass@64).
MapGlue: Multimodal Remote Sensing Image Matching
Mar 20, 2025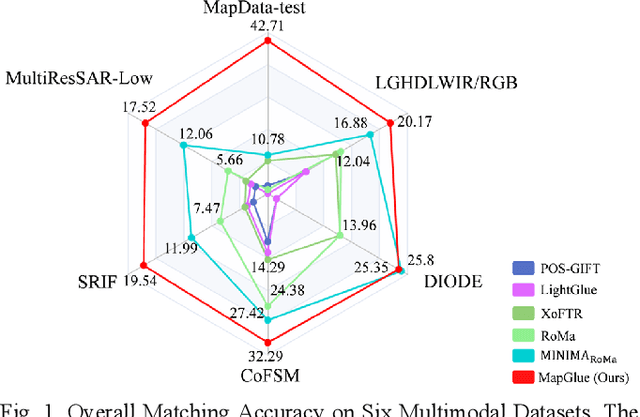
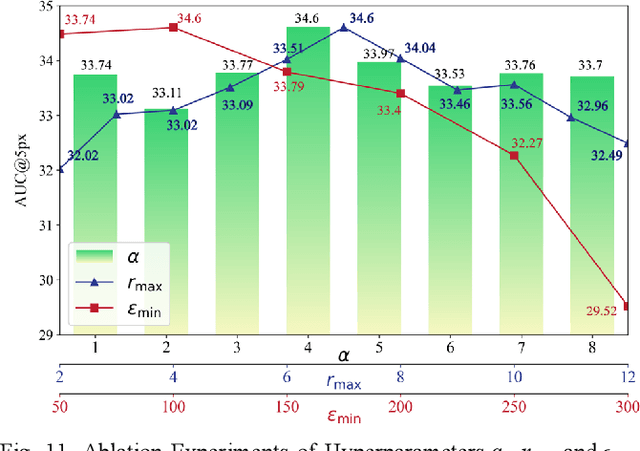
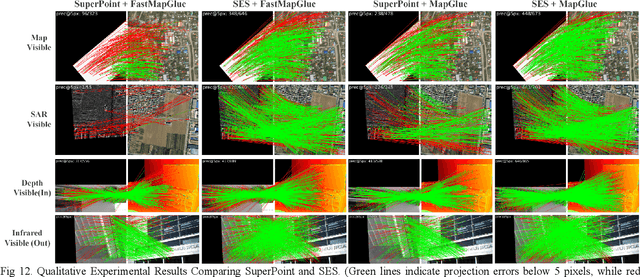

Multimodal remote sensing image (MRSI) matching is pivotal for cross-modal fusion, localization, and object detection, but it faces severe challenges due to geometric, radiometric, and viewpoint discrepancies across imaging modalities. Existing unimodal datasets lack scale and diversity, limiting deep learning solutions. This paper proposes MapGlue, a universal MRSI matching framework, and MapData, a large-scale multimodal dataset addressing these gaps. Our contributions are twofold. MapData, a globally diverse dataset spanning 233 sampling points, offers original images (7,000x5,000 to 20,000x15,000 pixels). After rigorous cleaning, it provides 121,781 aligned electronic map-visible image pairs (512x512 pixels) with hybrid manual-automated ground truth, addressing the scarcity of scalable multimodal benchmarks. MapGlue integrates semantic context with a dual graph-guided mechanism to extract cross-modal invariant features. This structure enables global-to-local interaction, enhancing descriptor robustness against modality-specific distortions. Extensive evaluations on MapData and five public datasets demonstrate MapGlue's superiority in matching accuracy under complex conditions, outperforming state-of-the-art methods. Notably, MapGlue generalizes effectively to unseen modalities without retraining, highlighting its adaptability. This work addresses longstanding challenges in MRSI matching by combining scalable dataset construction with a robust, semantics-driven framework. Furthermore, MapGlue shows strong generalization capabilities on other modality matching tasks for which it was not specifically trained. The dataset and code are available at https://github.com/PeihaoWu/MapGlue.
Multi-Resolution SAR and Optical Remote Sensing Image Registration Methods: A Review, Datasets, and Future Perspectives
Feb 03, 2025



Synthetic Aperture Radar (SAR) and optical image registration is essential for remote sensing data fusion, with applications in military reconnaissance, environmental monitoring, and disaster management. However, challenges arise from differences in imaging mechanisms, geometric distortions, and radiometric properties between SAR and optical images. As image resolution increases, fine SAR textures become more significant, leading to alignment issues and 3D spatial discrepancies. Two major gaps exist: the lack of a publicly available multi-resolution, multi-scene registration dataset and the absence of systematic analysis of current methods. To address this, the MultiResSAR dataset was created, containing over 10k pairs of multi-source, multi-resolution, and multi-scene SAR and optical images. Sixteen state-of-the-art algorithms were tested. Results show no algorithm achieves 100% success, and performance decreases as resolution increases, with most failing on sub-meter data. XoFTR performs best among deep learning methods (40.58%), while RIFT performs best among traditional methods (66.51%). Future research should focus on noise suppression, 3D geometric fusion, cross-view transformation modeling, and deep learning optimization for robust registration of high-resolution SAR and optical images. The dataset is available at https://github.com/betterlll/Multi-Resolution-SAR-dataset-.
CIF-PT: Bridging Speech and Text Representations for Spoken Language Understanding via Continuous Integrate-and-Fire Pre-Training
May 27, 2023



Speech or text representation generated by pre-trained models contains modal-specific information that could be combined for benefiting spoken language understanding (SLU) tasks. In this work, we propose a novel pre-training paradigm termed Continuous Integrate-and-Fire Pre-Training (CIF-PT). It relies on a simple but effective frame-to-token alignment: continuous integrate-and-fire (CIF) to bridge the representations between speech and text. It jointly performs speech-to-text training and language model distillation through CIF as the pre-training (PT). Evaluated on SLU benchmark SLURP dataset, CIF-PT outperforms the state-of-the-art model by 1.94% of accuracy and 2.71% of SLU-F1 on the tasks of intent classification and slot filling, respectively. We also observe the cross-modal representation extracted by CIF-PT obtains better performance than other neural interfaces for the tasks of SLU, including the dominant speech representation learned from self-supervised pre-training.
Unleashing Infinite-Length Input Capacity for Large-scale Language Models with Self-Controlled Memory System
Apr 26, 2023
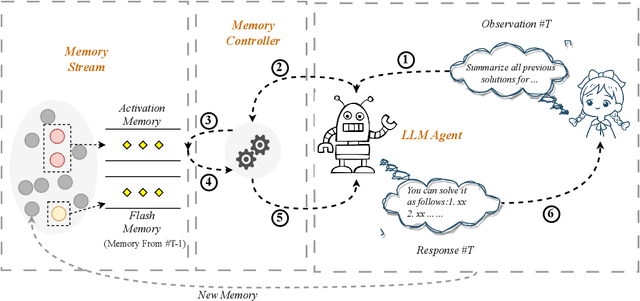

Large-scale Language Models (LLMs) are constrained by their inability to process lengthy inputs. To address this limitation, we propose the Self-Controlled Memory (SCM) system to unleash infinite-length input capacity for large-scale language models. Our SCM system is composed of three key modules: the language model agent, the memory stream, and the memory controller. The language model agent iteratively processes ultra-long inputs and stores all historical information in the memory stream. The memory controller provides the agent with both long-term memory (archived memory) and short-term memory (flash memory) to generate precise and coherent responses. The controller determines which memories from archived memory should be activated and how to incorporate them into the model input. Our SCM system can be integrated with any LLMs to enable them to process ultra-long texts without any modification or fine-tuning. Experimental results show that our SCM system enables LLMs, which are not optimized for multi-turn dialogue, to achieve multi-turn dialogue capabilities that are comparable to ChatGPT, and to outperform ChatGPT in scenarios involving ultra-long document summarization or long-term conversations. Additionally, we will supply a test set, which covers common long-text input scenarios, for evaluating the abilities of LLMs in processing long documents.~\footnote{Working in progress.}\footnote{\url{https://github.com/wbbeyourself/SCM4LLMs}}
Internal Language Model Estimation based Adaptive Language Model Fusion for Domain Adaptation
Nov 02, 2022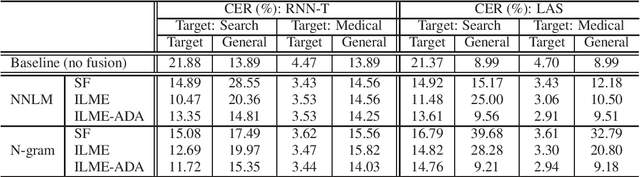
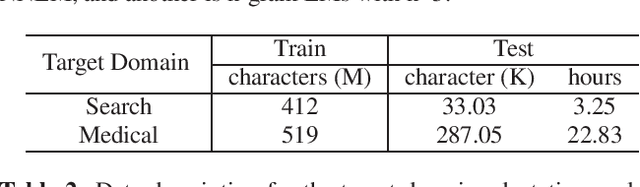
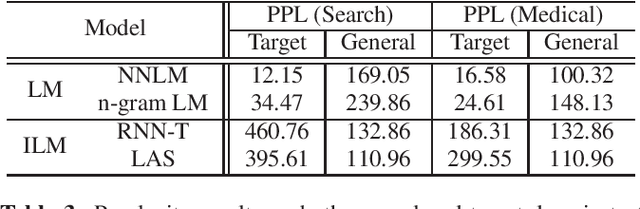
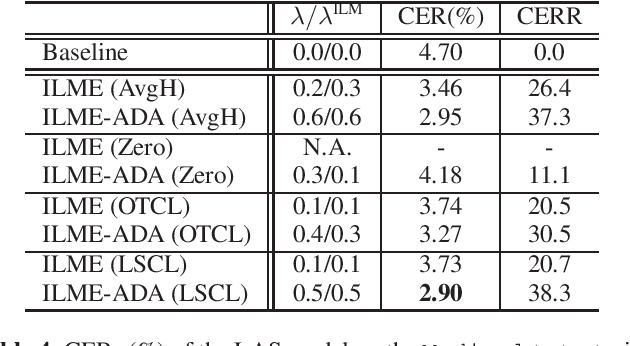
ASR model deployment environment is ever-changing, and the incoming speech can be switched across different domains during a session. This brings a challenge for effective domain adaptation when only target domain text data is available, and our objective is to obtain obviously improved performance on the target domain while the performance on the general domain is less undermined. In this paper, we propose an adaptive LM fusion approach called internal language model estimation based adaptive domain adaptation (ILME-ADA). To realize such an ILME-ADA, an interpolated log-likelihood score is calculated based on the maximum of the scores from the internal LM and the external LM (ELM) respectively. We demonstrate the efficacy of the proposed ILME-ADA method with both RNN-T and LAS modeling frameworks employing neural network and n-gram LMs as ELMs respectively on two domain specific (target) test sets. The proposed method can achieve significantly better performance on the target test sets while it gets minimal performance degradation on the general test set, compared with both shallow and ILME-based LM fusion methods.
Improving Contextual Representation with Gloss Regularized Pre-training
May 13, 2022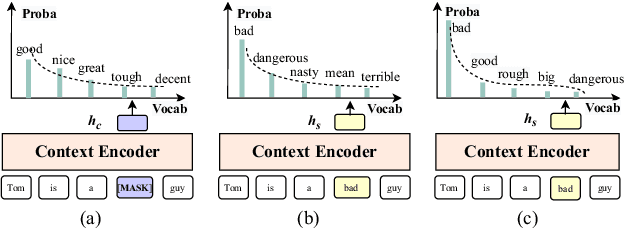
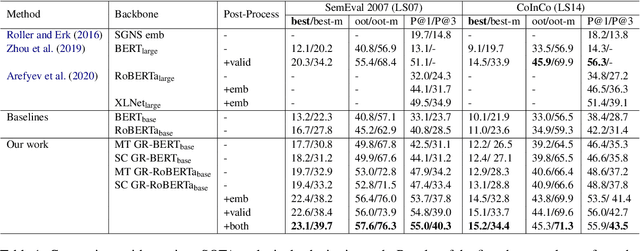
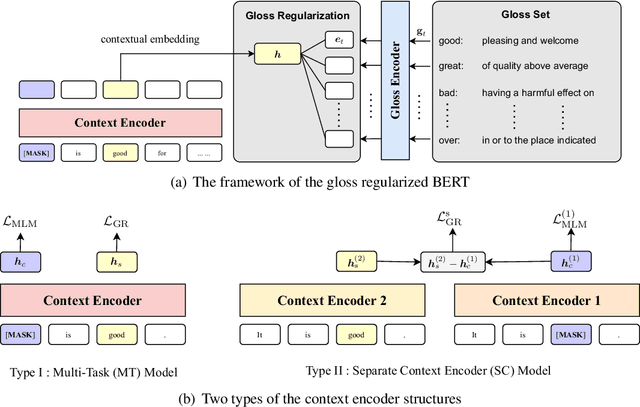
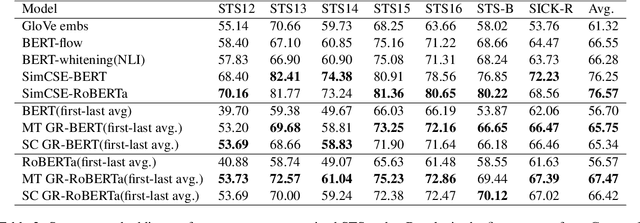
Though achieving impressive results on many NLP tasks, the BERT-like masked language models (MLM) encounter the discrepancy between pre-training and inference. In light of this gap, we investigate the contextual representation of pre-training and inference from the perspective of word probability distribution. We discover that BERT risks neglecting the contextual word similarity in pre-training. To tackle this issue, we propose an auxiliary gloss regularizer module to BERT pre-training (GR-BERT), to enhance word semantic similarity. By predicting masked words and aligning contextual embeddings to corresponding glosses simultaneously, the word similarity can be explicitly modeled. We design two architectures for GR-BERT and evaluate our model in downstream tasks. Experimental results show that the gloss regularizer benefits BERT in word-level and sentence-level semantic representation. The GR-BERT achieves new state-of-the-art in lexical substitution task and greatly promotes BERT sentence representation in both unsupervised and supervised STS tasks.
Deep LSTM for Large Vocabulary Continuous Speech Recognition
Mar 21, 2017
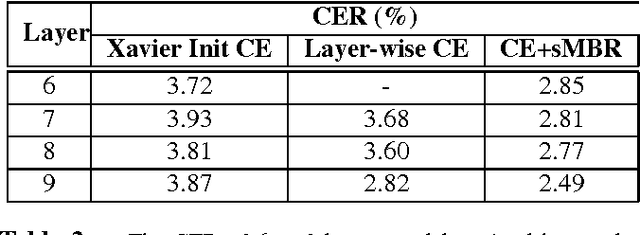
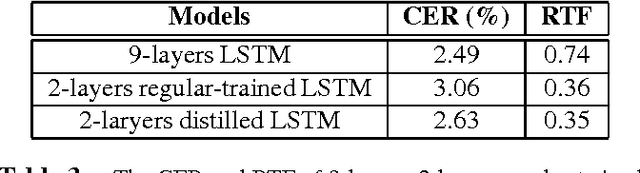
Recurrent neural networks (RNNs), especially long short-term memory (LSTM) RNNs, are effective network for sequential task like speech recognition. Deeper LSTM models perform well on large vocabulary continuous speech recognition, because of their impressive learning ability. However, it is more difficult to train a deeper network. We introduce a training framework with layer-wise training and exponential moving average methods for deeper LSTM models. It is a competitive framework that LSTM models of more than 7 layers are successfully trained on Shenma voice search data in Mandarin and they outperform the deep LSTM models trained by conventional approach. Moreover, in order for online streaming speech recognition applications, the shallow model with low real time factor is distilled from the very deep model. The recognition accuracy have little loss in the distillation process. Therefore, the model trained with the proposed training framework reduces relative 14\% character error rate, compared to original model which has the similar real-time capability. Furthermore, the novel transfer learning strategy with segmental Minimum Bayes-Risk is also introduced in the framework. The strategy makes it possible that training with only a small part of dataset could outperform full dataset training from the beginning.