 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrame Stacking and Retaining for Recurrent Neural Network Acoustic Model
May 17, 2017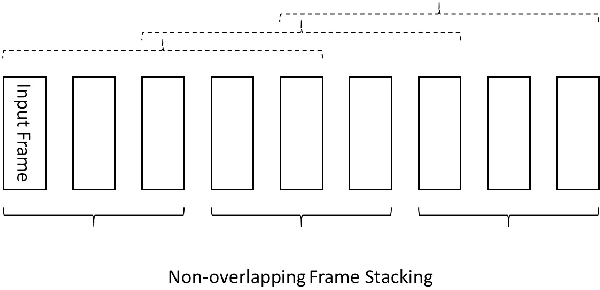
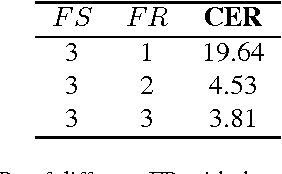
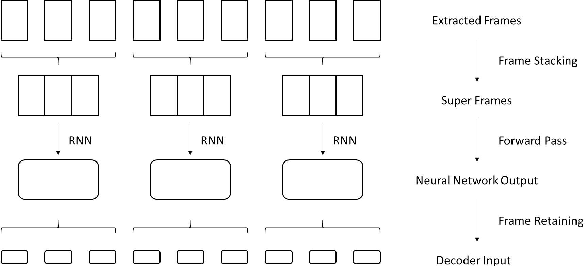
Frame stacking is broadly applied in end-to-end neural network training like connectionist temporal classification (CTC), and it leads to more accurate models and faster decoding. However, it is not well-suited to conventional neural network based on context-dependent state acoustic model, if the decoder is unchanged. In this paper, we propose a novel frame retaining method which is applied in decoding. The system which combined frame retaining with frame stacking could reduces the time consumption of both training and decoding. Long short-term memory (LSTM) recurrent neural networks (RNNs) using it achieve almost linear training speedup and reduces relative 41\% real time factor (RTF). At the same time, recognition performance is no degradation or improves sightly on Shenma voice search dataset in Mandarin.
Deep LSTM for Large Vocabulary Continuous Speech Recognition
Mar 21, 2017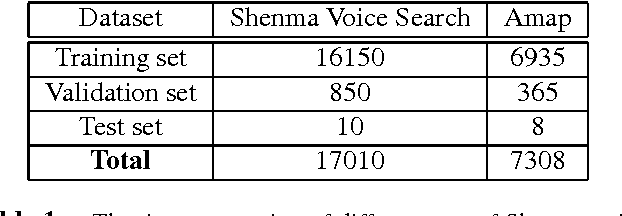
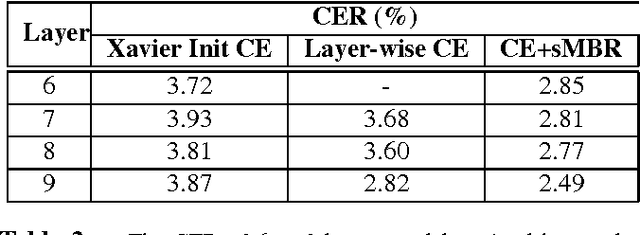
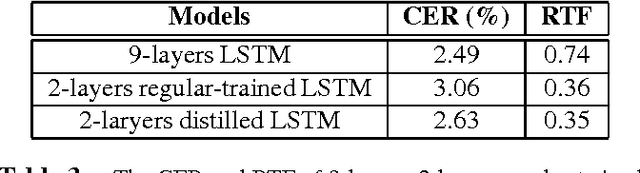
Recurrent neural networks (RNNs), especially long short-term memory (LSTM) RNNs, are effective network for sequential task like speech recognition. Deeper LSTM models perform well on large vocabulary continuous speech recognition, because of their impressive learning ability. However, it is more difficult to train a deeper network. We introduce a training framework with layer-wise training and exponential moving average methods for deeper LSTM models. It is a competitive framework that LSTM models of more than 7 layers are successfully trained on Shenma voice search data in Mandarin and they outperform the deep LSTM models trained by conventional approach. Moreover, in order for online streaming speech recognition applications, the shallow model with low real time factor is distilled from the very deep model. The recognition accuracy have little loss in the distillation process. Therefore, the model trained with the proposed training framework reduces relative 14\% character error rate, compared to original model which has the similar real-time capability. Furthermore, the novel transfer learning strategy with segmental Minimum Bayes-Risk is also introduced in the framework. The strategy makes it possible that training with only a small part of dataset could outperform full dataset training from the beginning.
Exponential Moving Average Model in Parallel Speech Recognition Training
Mar 03, 2017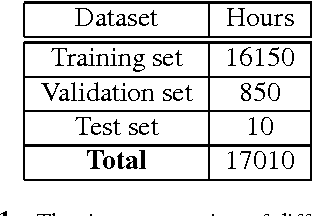
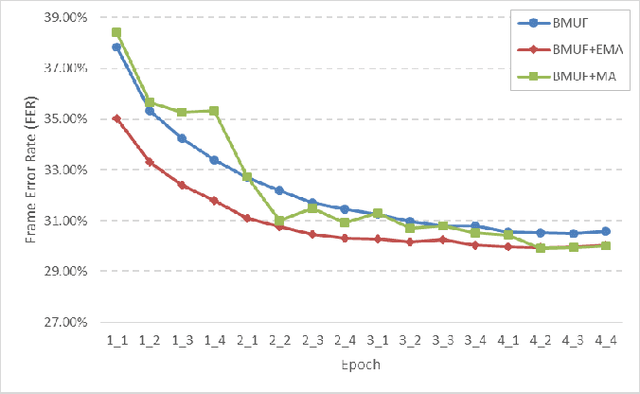
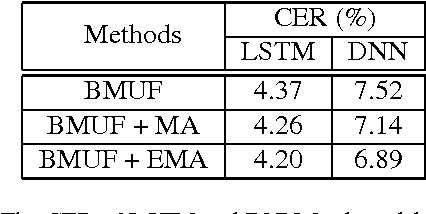
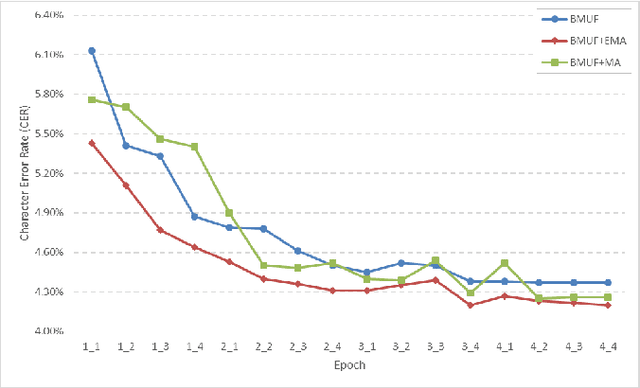
As training data rapid growth, large-scale parallel training with multi-GPUs cluster is widely applied in the neural network model learning currently.We present a new approach that applies exponential moving average method in large-scale parallel training of neural network model. It is a non-interference strategy that the exponential moving average model is not broadcasted to distributed workers to update their local models after model synchronization in the training process, and it is implemented as the final model of the training system. Fully-connected feed-forward neural networks (DNNs) and deep unidirectional Long short-term memory (LSTM) recurrent neural networks (RNNs) are successfully trained with proposed method for large vocabulary continuous speech recognition on Shenma voice search data in Mandarin. The character error rate (CER) of Mandarin speech recognition further degrades than state-of-the-art approaches of parallel training.