 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRI-based Multi-task Decoupling Learning for Alzheimer's Disease Detection and MMSE Score Prediction: A Multi-site Validation
Apr 06, 2022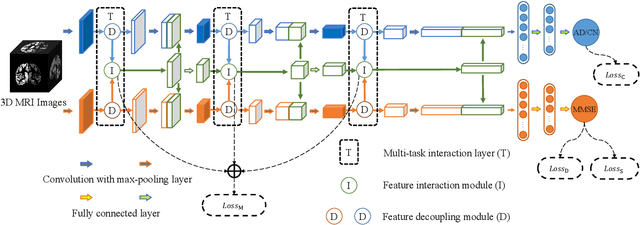

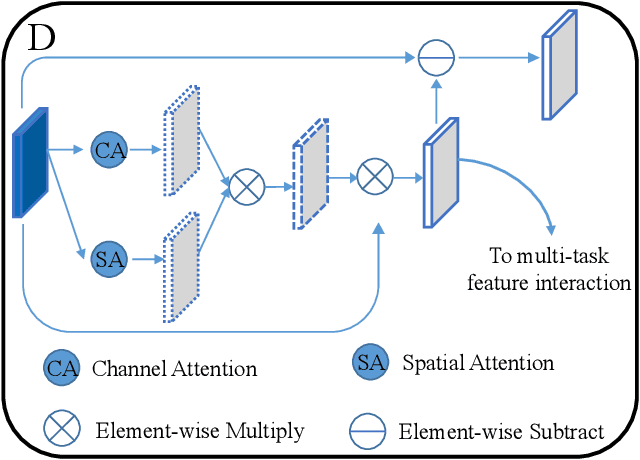

Accurately detecting Alzheimer's disease (AD) and predicting mini-mental state examination (MMSE) score are important tasks in elderly health by magnetic resonance imaging (MRI). Most of the previous methods on these two tasks are based on single-task learning and rarely consider the correlation between them. Since the MMSE score, which is an important basis for AD diagnosis, can also reflect the progress of cognitive impairment, some studies have begun to apply multi-task learning methods to these two tasks. However, how to exploit feature correlation remains a challenging problem for these methods. To comprehensively address this challenge, we propose a MRI-based multi-task decoupled learning method for AD detection and MMSE score prediction. First, a multi-task learning network is proposed to implement AD detection and MMSE score prediction, which exploits feature correlation by adding three multi-task interaction layers between the backbones of the two tasks. Each multi-task interaction layer contains two feature decoupling modules and one feature interaction module. Furthermore, to enhance the generalization between tasks of the features selected by the feature decoupling module, we propose the feature consistency loss constrained feature decoupling module. Finally, in order to exploit the specific distribution information of MMSE score in different groups, a distribution loss is proposed to further enhance the model performance. We evaluate our proposed method on multi-site datasets. Experimental results show that our proposed multi-task decoupled representation learning method achieves good performance, outperforming single-task learning and other existing state-of-the-art methods.
Incentive Compatible Pareto Alignment for Multi-Source Large Graphs
Dec 06, 2021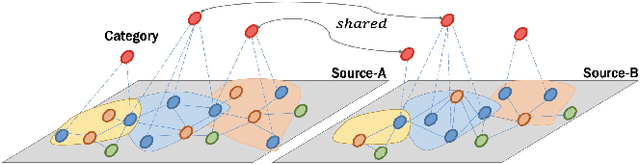
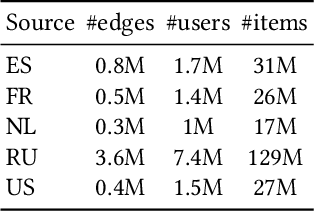
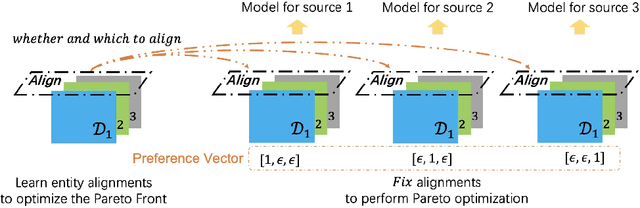
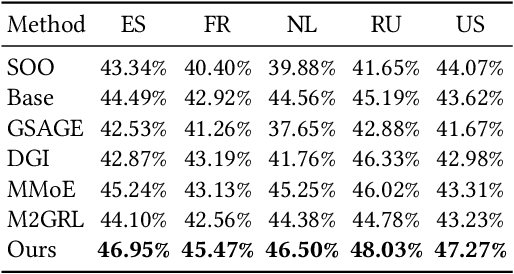
In this paper, we focus on learning effective entity matching models over multi-source large-scale data. For real applications, we relax typical assumptions that data distributions/spaces, or entity identities are shared between sources, and propose a Relaxed Multi-source Large-scale Entity-matching (RMLE) problem. Challenges of the problem include 1) how to align large-scale entities between sources to share information and 2) how to mitigate negative transfer from joint learning multi-source data. What's worse, one practical issue is the entanglement between both challenges. Specifically, incorrect alignments may increase negative transfer; while mitigating negative transfer for one source may result in poorly learned representations for other sources and then decrease alignment accuracy. To handle the entangled challenges, we point out that the key is to optimize information sharing first based on Pareto front optimization, by showing that information sharing significantly influences the Pareto front which depicts lower bounds of negative transfer. Consequently, we proposed an Incentive Compatible Pareto Alignment (ICPA) method to first optimize cross-source alignments based on Pareto front optimization, then mitigate negative transfer constrained on the optimized alignments. This mechanism renders each source can learn based on its true preference without worrying about deteriorating representations of other sources. Specifically, the Pareto front optimization encourages minimizing lower bounds of negative transfer, which optimizes whether and which to align. Comprehensive empirical evaluation results on four large-scale datasets are provided to demonstrate the effectiveness and superiority of ICPA. Online A/B test results at a search advertising platform also demonstrate the effectiveness of ICPA in production environments.
Speculate-Correct Error Bounds for k-Nearest Neighbor Classifiers
Sep 15, 2017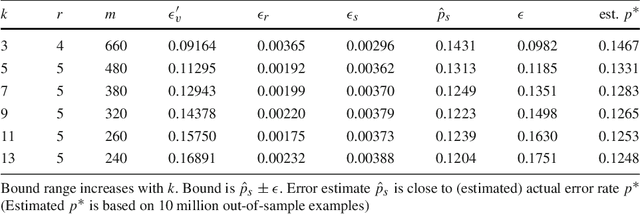
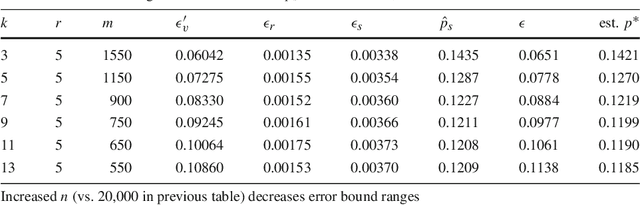
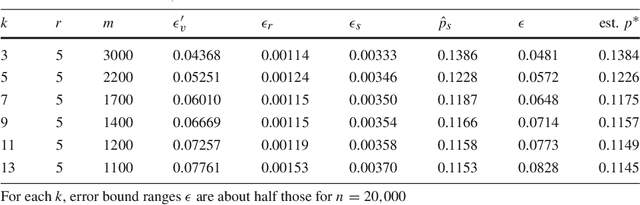
We introduce the speculate-correct method to derive error bounds for local classifiers. Using it, we show that k nearest neighbor classifiers, in spite of their famously fractured decision boundaries, have exponential error bounds with O(sqrt((k + ln n) / n)) error bound range for n in-sample examples.
Frame Stacking and Retaining for Recurrent Neural Network Acoustic Model
May 17, 2017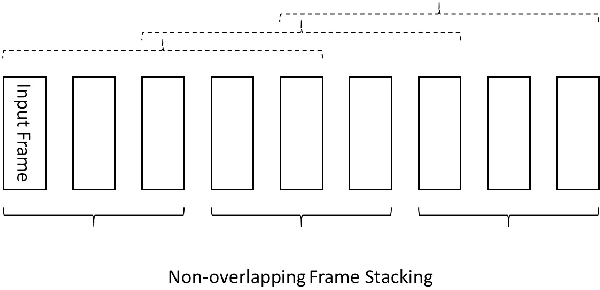
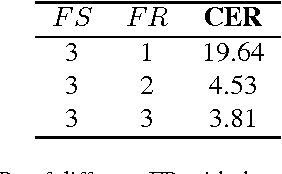
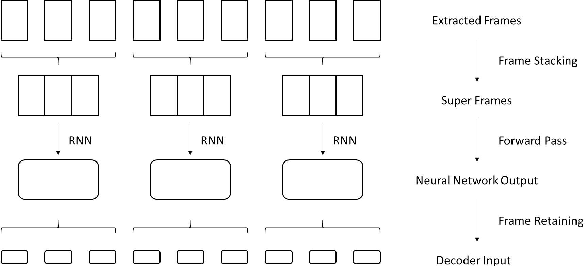
Frame stacking is broadly applied in end-to-end neural network training like connectionist temporal classification (CTC), and it leads to more accurate models and faster decoding. However, it is not well-suited to conventional neural network based on context-dependent state acoustic model, if the decoder is unchanged. In this paper, we propose a novel frame retaining method which is applied in decoding. The system which combined frame retaining with frame stacking could reduces the time consumption of both training and decoding. Long short-term memory (LSTM) recurrent neural networks (RNNs) using it achieve almost linear training speedup and reduces relative 41\% real time factor (RTF). At the same time, recognition performance is no degradation or improves sightly on Shenma voice search dataset in Mandarin.
Deep LSTM for Large Vocabulary Continuous Speech Recognition
Mar 21, 2017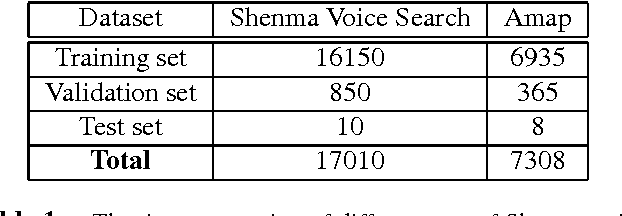
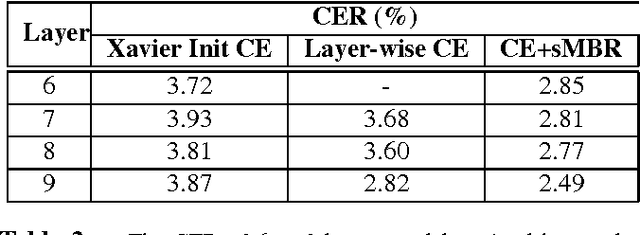
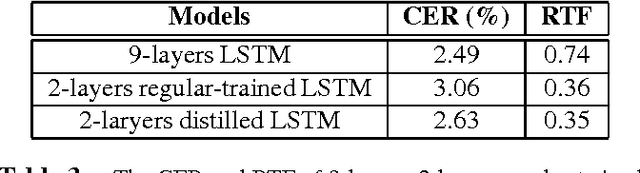
Recurrent neural networks (RNNs), especially long short-term memory (LSTM) RNNs, are effective network for sequential task like speech recognition. Deeper LSTM models perform well on large vocabulary continuous speech recognition, because of their impressive learning ability. However, it is more difficult to train a deeper network. We introduce a training framework with layer-wise training and exponential moving average methods for deeper LSTM models. It is a competitive framework that LSTM models of more than 7 layers are successfully trained on Shenma voice search data in Mandarin and they outperform the deep LSTM models trained by conventional approach. Moreover, in order for online streaming speech recognition applications, the shallow model with low real time factor is distilled from the very deep model. The recognition accuracy have little loss in the distillation process. Therefore, the model trained with the proposed training framework reduces relative 14\% character error rate, compared to original model which has the similar real-time capability. Furthermore, the novel transfer learning strategy with segmental Minimum Bayes-Risk is also introduced in the framework. The strategy makes it possible that training with only a small part of dataset could outperform full dataset training from the beginning.
Exponential Moving Average Model in Parallel Speech Recognition Training
Mar 03, 2017
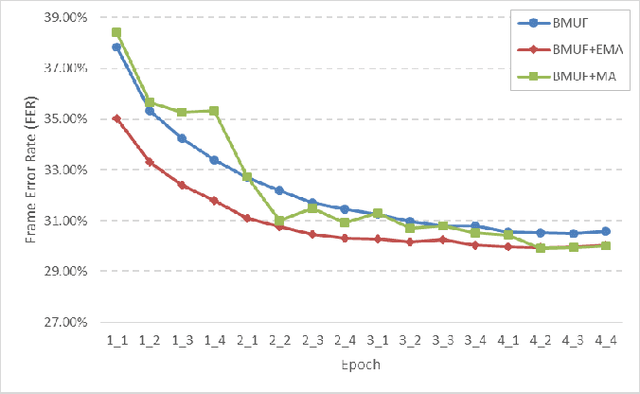
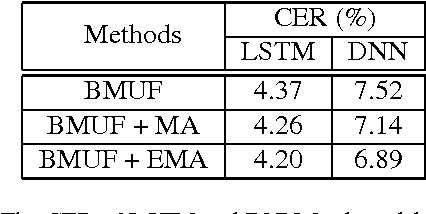
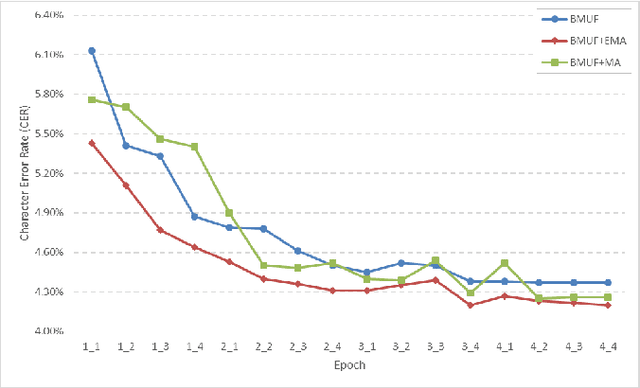
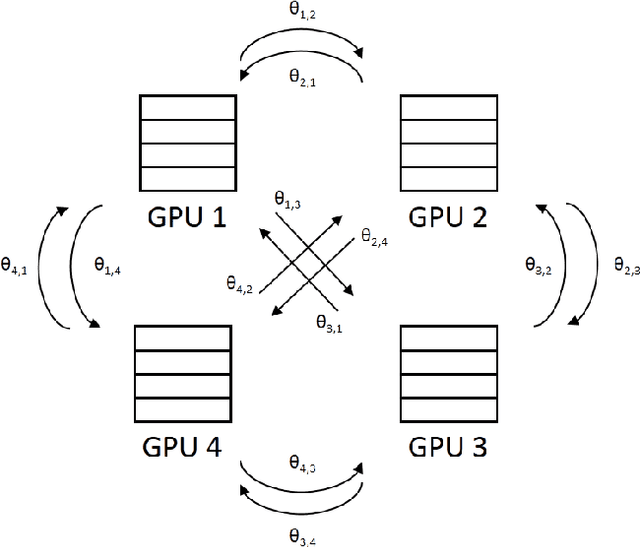
As training data rapid growth, large-scale parallel training with multi-GPUs cluster is widely applied in the neural network model learning currently.We present a new approach that applies exponential moving average method in large-scale parallel training of neural network model. It is a non-interference strategy that the exponential moving average model is not broadcasted to distributed workers to update their local models after model synchronization in the training process, and it is implemented as the final model of the training system. Fully-connected feed-forward neural networks (DNNs) and deep unidirectional Long short-term memory (LSTM) recurrent neural networks (RNNs) are successfully trained with proposed method for large vocabulary continuous speech recognition on Shenma voice search data in Mandarin. The character error rate (CER) of Mandarin speech recognition further degrades than state-of-the-art approaches of parallel training.