 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrame Stacking and Retaining for Recurrent Neural Network Acoustic Model
Paper and Code
May 17, 2017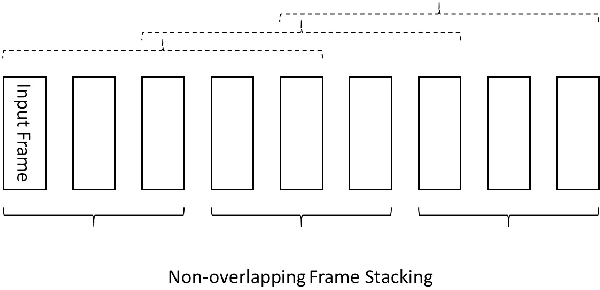
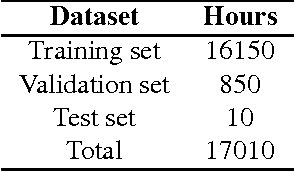
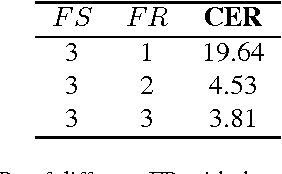
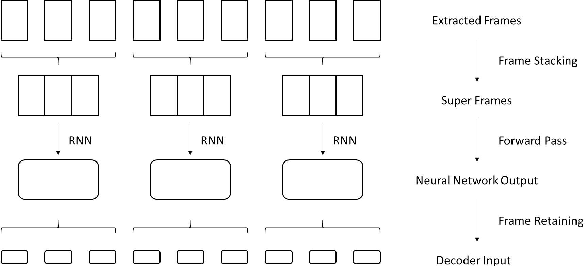
Frame stacking is broadly applied in end-to-end neural network training like connectionist temporal classification (CTC), and it leads to more accurate models and faster decoding. However, it is not well-suited to conventional neural network based on context-dependent state acoustic model, if the decoder is unchanged. In this paper, we propose a novel frame retaining method which is applied in decoding. The system which combined frame retaining with frame stacking could reduces the time consumption of both training and decoding. Long short-term memory (LSTM) recurrent neural networks (RNNs) using it achieve almost linear training speedup and reduces relative 41\% real time factor (RTF). At the same time, recognition performance is no degradation or improves sightly on Shenma voice search dataset in Mandarin.