 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExponential Moving Average Model in Parallel Speech Recognition Training
Paper and Code
Mar 03, 2017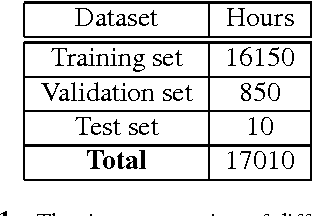
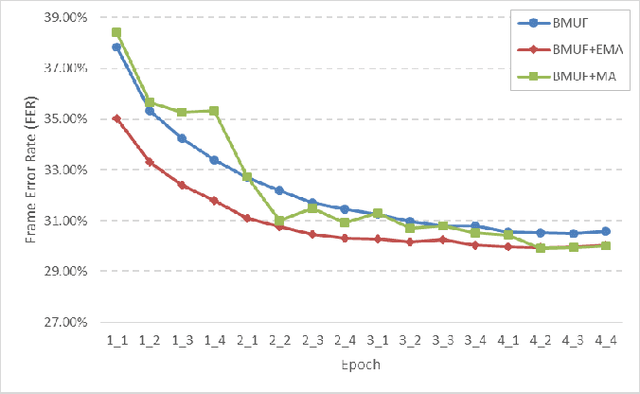
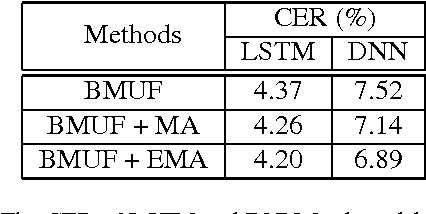
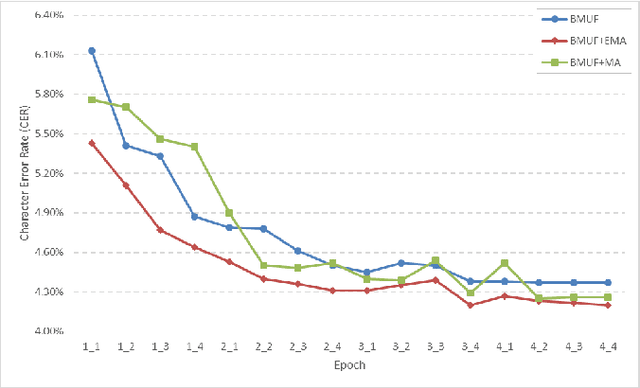
As training data rapid growth, large-scale parallel training with multi-GPUs cluster is widely applied in the neural network model learning currently.We present a new approach that applies exponential moving average method in large-scale parallel training of neural network model. It is a non-interference strategy that the exponential moving average model is not broadcasted to distributed workers to update their local models after model synchronization in the training process, and it is implemented as the final model of the training system. Fully-connected feed-forward neural networks (DNNs) and deep unidirectional Long short-term memory (LSTM) recurrent neural networks (RNNs) are successfully trained with proposed method for large vocabulary continuous speech recognition on Shenma voice search data in Mandarin. The character error rate (CER) of Mandarin speech recognition further degrades than state-of-the-art approaches of parallel training.