 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention2Probability: Attention-Driven Terminology Probability Estimation for Robust Speech-to-Text System
Aug 26, 2025Recent advances in speech large language models (SLMs) have improved speech recognition and translation in general domains, but accurately generating domain-specific terms or neologisms remains challenging. To address this, we propose Attention2Probability: attention-driven terminology probability estimation for robust speech-to-text system, which is lightweight, flexible, and accurate. Attention2Probability converts cross-attention weights between speech and terminology into presence probabilities, and it further employs curriculum learning to enhance retrieval accuracy. Furthermore, to tackle the lack of data for speech-to-text tasks with terminology intervention, we create and release a new speech dataset with terminology to support future research in this area. Experimental results show that Attention2Probability significantly outperforms the VectorDB method on our test set. Specifically, its maximum recall rates reach 92.57% for Chinese and 86.83% for English. This high recall is achieved with a latency of only 8.71ms per query. Intervening in SLMs' recognition and translation tasks using Attention2Probability-retrieved terms improves terminology accuracy by 6-17%, while revealing that the current utilization of terminology by SLMs has limitations.
Unbiased Scene Graph Generation by Type-Aware Message Passing on Heterogeneous and Dual Graphs
Nov 20, 2024Although great progress has been made in the research of unbiased scene graph generation, issues still hinder improving the predictive performance of both head and tail classes. An unbiased scene graph generation (TA-HDG) is proposed to address these issues. For modeling interactive and non-interactive relations, the Interactive Graph Construction is proposed to model the dependence of relations on objects by combining heterogeneous and dual graph, when modeling relations between multiple objects. It also implements a subject-object pair selection strategy to reduce meaningless edges. Moreover, the Type-Aware Message Passing enhances the understanding of complex interactions by capturing intra- and inter-type context in the Intra-Type and Inter-Type stages. The Intra-Type stage captures the semantic context of inter-relaitons and inter-objects. On this basis, the Inter-Type stage captures the context between objects and relations for interactive and non-interactive relations, respectively. Experiments on two datasets show that TA-HDG achieves improvements in the metrics of R@K and mR@K, which proves that TA-HDG can accurately predict the tail class while maintaining the competitive performance of the head class.
Neural-Symbolic VideoQA: Learning Compositional Spatio-Temporal Reasoning for Real-world Video Question Answering
Apr 05, 2024Compositional spatio-temporal reasoning poses a significant challenge in the field of video question answering (VideoQA). Existing approaches struggle to establish effective symbolic reasoning structures, which are crucial for answering compositional spatio-temporal questions. To address this challenge, we propose a neural-symbolic framework called Neural-Symbolic VideoQA (NS-VideoQA), specifically designed for real-world VideoQA tasks. The uniqueness and superiority of NS-VideoQA are two-fold: 1) It proposes a Scene Parser Network (SPN) to transform static-dynamic video scenes into Symbolic Representation (SR), structuralizing persons, objects, relations, and action chronologies. 2) A Symbolic Reasoning Machine (SRM) is designed for top-down question decompositions and bottom-up compositional reasonings. Specifically, a polymorphic program executor is constructed for internally consistent reasoning from SR to the final answer. As a result, Our NS-VideoQA not only improves the compositional spatio-temporal reasoning in real-world VideoQA task, but also enables step-by-step error analysis by tracing the intermediate results. Experimental evaluations on the AGQA Decomp benchmark demonstrate the effectiveness of the proposed NS-VideoQA framework. Empirical studies further confirm that NS-VideoQA exhibits internal consistency in answering compositional questions and significantly improves the capability of spatio-temporal and logical inference for VideoQA tasks.
Improving Large-scale Deep Biasing with Phoneme Features and Text-only Data in Streaming Transducer
Nov 15, 2023



Deep biasing for the Transducer can improve the recognition performance of rare words or contextual entities, which is essential in practical applications, especially for streaming Automatic Speech Recognition (ASR). However, deep biasing with large-scale rare words remains challenging, as the performance drops significantly when more distractors exist and there are words with similar grapheme sequences in the bias list. In this paper, we combine the phoneme and textual information of rare words in Transducers to distinguish words with similar pronunciation or spelling. Moreover, the introduction of training with text-only data containing more rare words benefits large-scale deep biasing. The experiments on the LibriSpeech corpus demonstrate that the proposed method achieves state-of-the-art performance on rare word error rate for different scales and levels of bias lists.
Internal Language Model Estimation based Adaptive Language Model Fusion for Domain Adaptation
Nov 02, 2022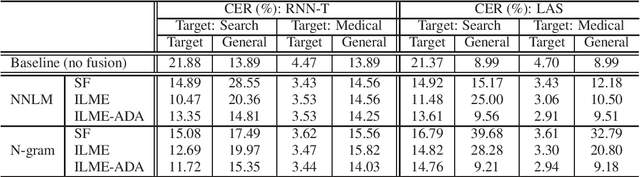
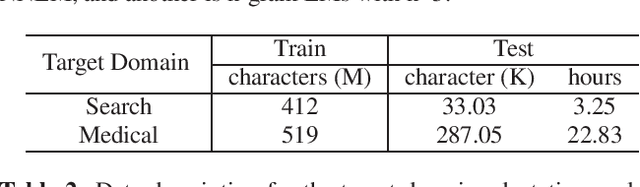
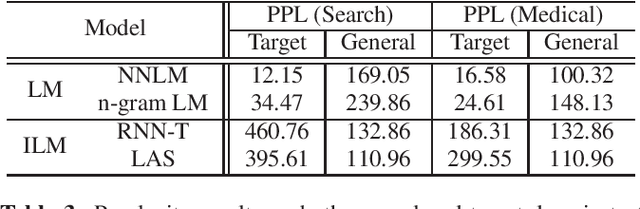
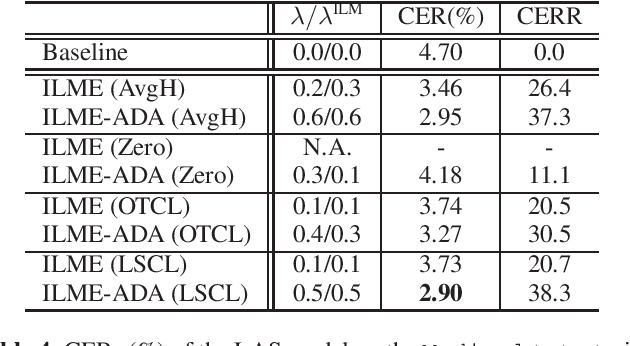
ASR model deployment environment is ever-changing, and the incoming speech can be switched across different domains during a session. This brings a challenge for effective domain adaptation when only target domain text data is available, and our objective is to obtain obviously improved performance on the target domain while the performance on the general domain is less undermined. In this paper, we propose an adaptive LM fusion approach called internal language model estimation based adaptive domain adaptation (ILME-ADA). To realize such an ILME-ADA, an interpolated log-likelihood score is calculated based on the maximum of the scores from the internal LM and the external LM (ELM) respectively. We demonstrate the efficacy of the proposed ILME-ADA method with both RNN-T and LAS modeling frameworks employing neural network and n-gram LMs as ELMs respectively on two domain specific (target) test sets. The proposed method can achieve significantly better performance on the target test sets while it gets minimal performance degradation on the general test set, compared with both shallow and ILME-based LM fusion methods.
Placement Optimization of Aerial Base Stations with Deep Reinforcement Learning
Nov 19, 2019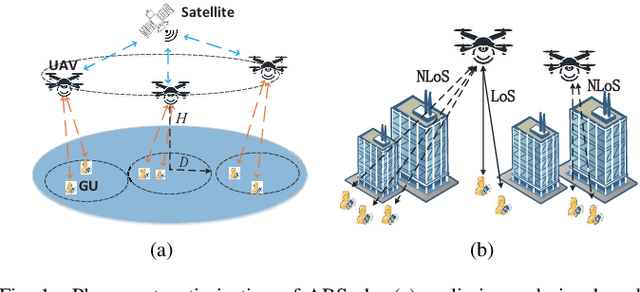
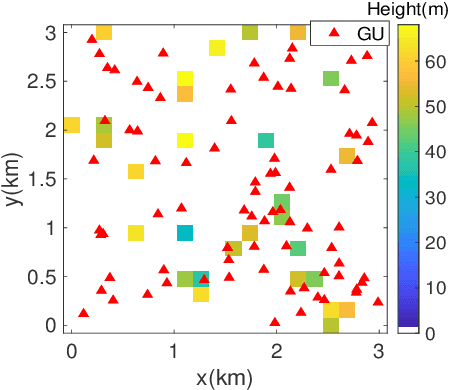
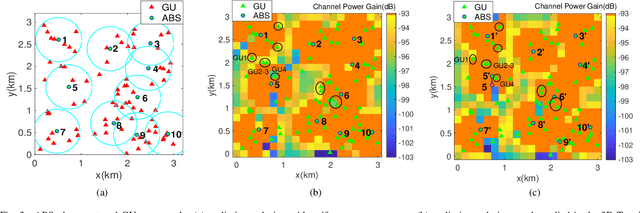
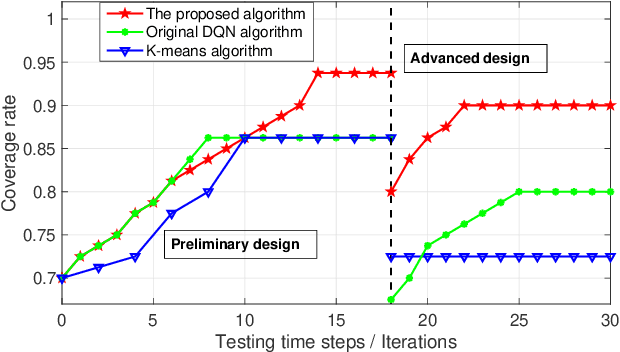
Unmanned aerial vehicles (UAVs) can be utilized as aerial base stations (ABSs) to assist terrestrial infrastructure for keeping wireless connectivity in various emergency scenarios. To maximize the coverage rate of N ground users (GUs) by jointly placing multiple ABSs with limited coverage range is known to be a NP-hard problem with exponential complexity in N. The problem is further complicated when the coverage range becomes irregular due to site-specific blockage (e.g., buildings) on the air-ground channel in the 3-dimensional (3D) space. To tackle this challenging problem, this paper applies the Deep Reinforcement Learning (DRL) method by 1) representing the state by a coverage bitmap to capture the spatial correlation of GUs/ABSs, whose dimension and associated neural network complexity is invariant with arbitrarily large N; and 2) designing the action and reward for the DRL agent to effectively learn from the dynamic interactions with the complicated propagation environment represented by a 3D Terrain Map. Specifically, a novel two-level design approach is proposed, consisting of a preliminary design based on the dominant line-of-sight (LoS) channel model, and an advanced design to further refine the ABS positions based on site-specific LoS/non-LoS channel states. The double deep Q-network (DQN) with Prioritized Experience Replay (Prioritized Replay DDQN) algorithm is applied to train the policy of multi-ABS placement decision. Numerical results show that the proposed approach significantly improves the coverage rate in complex environment, compared to the benchmark DQN and K-means algorithms.