 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$τ_0$-WM: A Unified Video-Action World Model for Robotic Manipulation
May 31, 2026Robotic manipulation requires models that generate executable actions while anticipating and evaluating their future consequences before physical execution. We present $τ_0$-World Model ($τ_0$-WM), a unified video-action world model that integrates policy learning, video prediction, and action evaluation within a single future-predictive framework. Built on a shared video diffusion backbone, $τ_0$-WM provides two complementary interfaces. First, a video action model jointly predicts future visual latents and continuous action chunks from multi-view observations, language instructions, and robot state. Second, an action-conditioned video simulator rolls out candidate action chunks into multi-view futures and predicts dense task-progress scores. The model is trained on approximately $27{,}300$ hours of real-robot teleoperation, UMI-style interaction, egocentric human videos, and rollout or failure trajectories using modality-specific supervision masks. At inference time, $τ_0$-WM uses test-time computation to sample action candidates, rank them with re-denoising consistency, and invoke simulator-based rectification for low-quality candidates. On challenging long-horizon and fine-grained robotic manipulation tasks, $τ_0$-WM shows superior performance over other relevant baselines.
ZipMoE: Efficient On-Device MoE Serving via Lossless Compression and Cache-Affinity Scheduling
Jan 29, 2026While Mixture-of-Experts (MoE) architectures substantially bolster the expressive power of large-language models, their prohibitive memory footprint severely impedes the practical deployment on resource-constrained edge devices, especially when model behavior must be preserved without relying on lossy quantization. In this paper, we present ZipMoE, an efficient and semantically lossless on-device MoE serving system. ZipMoE exploits the synergy between the hardware properties of edge devices and the statistical redundancy inherent to MoE parameters via a caching-scheduling co-design with provable performance guarantee. Fundamentally, our design shifts the paradigm of on-device MoE inference from an I/O-bound bottleneck to a compute-centric workflow that enables efficient parallelization. We implement a prototype of ZipMoE and conduct extensive experiments on representative edge computing platforms using popular open-source MoE models and real-world workloads. Our evaluation reveals that ZipMoE achieves up to $72.77\%$ inference latency reduction and up to $6.76\times$ higher throughput than the state-of-the-art systems.
REAL-Prover: Retrieval Augmented Lean Prover for Mathematical Reasoning
May 27, 2025Nowadays, formal theorem provers have made monumental progress on high-school and competition-level mathematics, but few of them generalize to more advanced mathematics. In this paper, we present REAL-Prover, a new open-source stepwise theorem prover for Lean 4 to push this boundary. This prover, based on our fine-tuned large language model (REAL-Prover-v1) and integrated with a retrieval system (Leansearch-PS), notably boosts performance on solving college-level mathematics problems. To train REAL-Prover-v1, we developed HERALD-AF, a data extraction pipeline that converts natural language math problems into formal statements, and a new open-source Lean 4 interactive environment (Jixia-interactive) to facilitate synthesis data collection. In our experiments, our prover using only supervised fine-tune achieves competitive results with a 23.7% success rate (Pass@64) on the ProofNet dataset-comparable to state-of-the-art (SOTA) models. To further evaluate our approach, we introduce FATE-M, a new benchmark focused on algebraic problems, where our prover achieves a SOTA success rate of 56.7% (Pass@64).
Wavelet Probabilistic Recurrent Convolutional Network for Multivariate Time Series Classification
May 22, 2025



This paper presents a Wavelet Probabilistic Recurrent Convolutional Network (WPRCN) for Multivariate Time Series Classification (MTSC), especially effective in handling non-stationary environments, data scarcity and noise perturbations. We introduce a versatile wavelet probabilistic module designed to extract and analyse the probabilistic features, which can seamlessly integrate with a variety of neural network architectures. This probabilistic module comprises an Adaptive Wavelet Probabilistic Feature Generator (AWPG) and a Channel Attention-based Probabilistic Temporal Convolutional Network (APTCN). Such formulation extends the application of wavelet probabilistic neural networks to deep neural networks for MTSC. The AWPG constructs an ensemble probabilistic model addressing different data scarcities and non-stationarity; it adaptively selects the optimal ones and generates probabilistic features for APTCN. The APTCN analyses the correlations of the features and forms a comprehensive feature space with existing MTSC models for classification. Here, we instantiate the proposed module to work in parallel with a Long Short-Term Memory (LSTM) network and a Causal Fully Convolutional Network (C-FCN), demonstrating its broad applicability in time series analysis. The WPRCN is evaluated on 30 diverse MTS datasets and outperforms all the benchmark algorithms on average accuracy and rank, exhibiting pronounced strength in handling scarce data and physiological data subject to perturbations and non-stationarities.
Anomaly Detection for Non-stationary Time Series using Recurrent Wavelet Probabilistic Neural Network
May 16, 2025

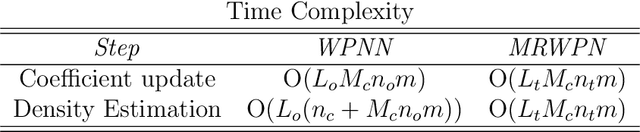

In this paper, an unsupervised Recurrent Wavelet Probabilistic Neural Network (RWPNN) is proposed, which aims at detecting anomalies in non-stationary environments by modelling the temporal features using a nonparametric density estimation network. The novel framework consists of two components, a Stacked Recurrent Encoder-Decoder (SREnc-Dec) module that captures temporal features in a latent space, and a Multi-Receptive-field Wavelet Probabilistic Network (MRWPN) that creates an ensemble probabilistic model to characterise the latent space. This formulation extends the standard wavelet probabilistic networks to wavelet deep probabilistic networks, which can handle higher data dimensionality. The MRWPN module can adapt to different rates of data variation in different datasets without imposing strong distribution assumptions, resulting in a more robust and accurate detection for Time Series Anomaly Detection (TSAD) tasks in the non-stationary environment. We carry out the assessment on 45 real-world time series datasets from various domains, verify the performance of RWPNN in TSAD tasks with several constraints, and show its ability to provide early warnings for anomalous events.
Spend Wisely: Maximizing Post-Training Gains in Iterative Synthetic Data Boostrapping
Jan 31, 2025



Modern foundation models often undergo iterative ``bootstrapping'' in their post-training phase: a model generates synthetic data, an external verifier filters out low-quality samples, and the high-quality subset is used for further fine-tuning. Over multiple iterations, the model's performance improves--raising a crucial question: how should the total budget on generation and training be allocated across iterations to maximize final performance? In this work, we develop a theoretical framework to analyze budget allocation strategies. Specifically, we show that constant policies fail to converge with high probability, while increasing policies--particularly exponential growth policies--exhibit significant theoretical advantages. Experiments on image denoising with diffusion probabilistic models and math reasoning with large language models show that both exponential and polynomial growth policies consistently outperform constant policies, with exponential policies often providing more stable performance.
MoColl: Agent-Based Specific and General Model Collaboration for Image Captioning
Jan 03, 2025



Image captioning is a critical task at the intersection of computer vision and natural language processing, with wide-ranging applications across various domains. For complex tasks such as diagnostic report generation, deep learning models require not only domain-specific image-caption datasets but also the incorporation of relevant general knowledge to provide contextual accuracy. Existing approaches exhibit inherent limitations: specialized models excel in capturing domain-specific details but lack generalization, while vision-language models (VLMs) built on large language models (LLMs) leverage general knowledge but struggle with domain-specific adaptation. To address these limitations, this paper proposes a novel agent-enhanced model collaboration framework, which we called \textbf{MoColl}, designed to effectively integrate domain-specific and general knowledge. Specifically, our approach is to decompose complex image captioning tasks into a series of interconnected question-answer subtasks. A trainable visual question answering (VQA) model is employed as a specialized tool to focus on domain-specific visual analysis, answering task-specific questions based on image content. Concurrently, an LLM-based agent with general knowledge formulates these questions and synthesizes the resulting question-answer pairs into coherent captions. Beyond its role in leveraging the VQA model, the agent further guides its training to enhance its domain-specific capabilities. Experimental results on radiology report generation validate the effectiveness of the proposed framework, demonstrating significant improvements in the quality of generated reports.
Beyond Model Collapse: Scaling Up with Synthesized Data Requires Reinforcement
Jun 11, 2024



Synthesized data from generative models is increasingly considered as an alternative to human-annotated data for fine-tuning Large Language Models. This raises concerns about model collapse: a drop in performance of models fine-tuned on generated data. Considering that it is easier for both humans and machines to tell between good and bad examples than to generate high-quality samples, we investigate the use of feedback on synthesized data to prevent model collapse. We derive theoretical conditions under which a Gaussian mixture classification model can achieve asymptotically optimal performance when trained on feedback-augmented synthesized data, and provide supporting simulations for finite regimes. We illustrate our theoretical predictions on two practical problems: computing matrix eigenvalues with transformers and news summarization with large language models, which both undergo model collapse when trained on model-generated data. We show that training from feedback-augmented synthesized data, either by pruning incorrect predictions or by selecting the best of several guesses, can prevent model collapse, validating popular approaches like RLHF.
A Tale of Tails: Model Collapse as a Change of Scaling Laws
Feb 10, 2024



As AI model size grows, neural scaling laws have become a crucial tool to predict the improvements of large models when increasing capacity and the size of original (human or natural) training data. Yet, the widespread use of popular models means that the ecosystem of online data and text will co-evolve to progressively contain increased amounts of synthesized data. In this paper we ask: How will the scaling laws change in the inevitable regime where synthetic data makes its way into the training corpus? Will future models, still improve, or be doomed to degenerate up to total (model) collapse? We develop a theoretical framework of model collapse through the lens of scaling laws. We discover a wide range of decay phenomena, analyzing loss of scaling, shifted scaling with number of generations, the ''un-learning" of skills, and grokking when mixing human and synthesized data. Our theory is validated by large-scale experiments with a transformer on an arithmetic task and text generation using the large language model Llama2.
A Joint Design for Full-duplex OFDM AF Relay System with Precoded Short Guard Interval
Jul 07, 2023



In-band full-duplex relay (FDR) has attracted much attention as an effective solution to improve the coverage and spectral efficiency in wireless communication networks. The basic problem for FDR transmission is how to eliminate the inherent self-interference and re-use the residual self-interference (RSI) at the relay to improve the end-to-end performance. Considering the RSI at the FDR, the overall equivalent channel can be modeled as an infinite impulse response (IIR) channel. For this IIR channel, a joint design for precoding, power gain control and equalization of cooperative OFDM relay systems is presented. Compared with the traditional OFDM systems, the length of the guard interval for the proposed design can be distinctly reduced, thereby improving the spectral efficiency. By analyzing the noise sources, this paper evaluates the signal to noise ratio (SNR) of the proposed scheme and presents a power gain control algorithm at the FDR. Compared with the existing schemes, the proposed scheme shows a superior bit error rate (BER) performance.