 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen in Doubt: Improving Classification Performance with Alternating Normalization
Sep 28, 2021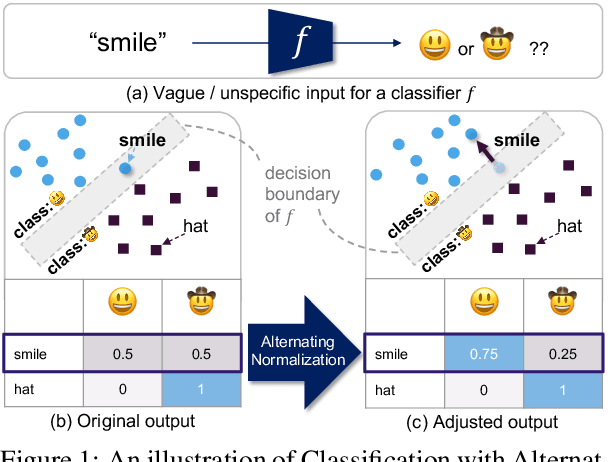
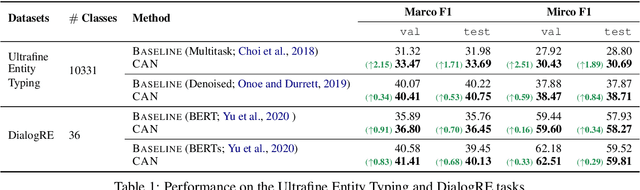
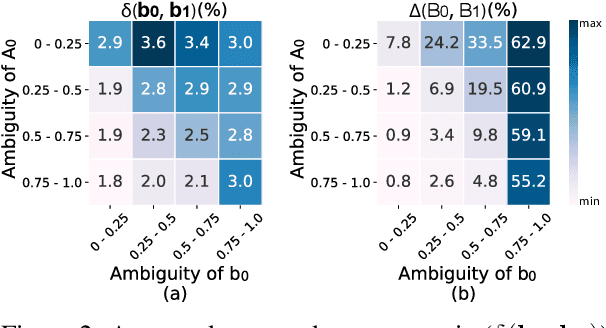

We introduce Classification with Alternating Normalization (CAN), a non-parametric post-processing step for classification. CAN improves classification accuracy for challenging examples by re-adjusting their predicted class probability distribution using the predicted class distributions of high-confidence validation examples. CAN is easily applicable to any probabilistic classifier, with minimal computation overhead. We analyze the properties of CAN using simulated experiments, and empirically demonstrate its effectiveness across a diverse set of classification tasks.
Cross-Modal Retrieval Augmentation for Multi-Modal Classification
Apr 16, 2021
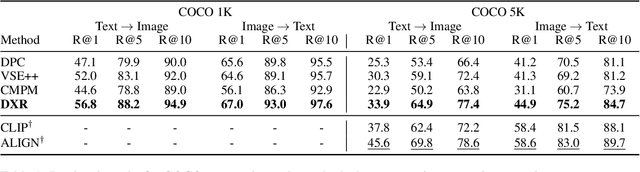

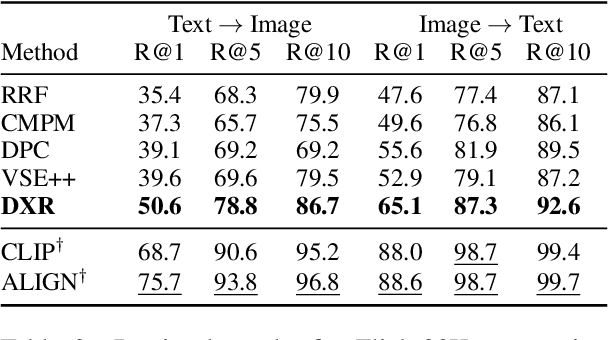
Recent advances in using retrieval components over external knowledge sources have shown impressive results for a variety of downstream tasks in natural language processing. Here, we explore the use of unstructured external knowledge sources of images and their corresponding captions for improving visual question answering (VQA). First, we train a novel alignment model for embedding images and captions in the same space, which achieves substantial improvement in performance on image-caption retrieval w.r.t. similar methods. Second, we show that retrieval-augmented multi-modal transformers using the trained alignment model improve results on VQA over strong baselines. We further conduct extensive experiments to establish the promise of this approach, and examine novel applications for inference time such as hot-swapping indices.
Exploring Visual Engagement Signals for Representation Learning
Apr 15, 2021
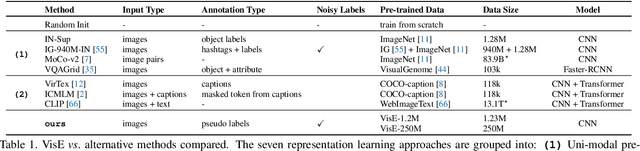


Visual engagement in social media platforms comprises interactions with photo posts including comments, shares, and likes. In this paper, we leverage such visual engagement clues as supervisory signals for representation learning. However, learning from engagement signals is non-trivial as it is not clear how to bridge the gap between low-level visual information and high-level social interactions. We present VisE, a weakly supervised learning approach, which maps social images to pseudo labels derived by clustered engagement signals. We then study how models trained in this way benefit subjective downstream computer vision tasks such as emotion recognition or political bias detection. Through extensive studies, we empirically demonstrate the effectiveness of VisE across a diverse set of classification tasks beyond the scope of conventional recognition.
Intentonomy: a Dataset and Study towards Human Intent Understanding
Nov 11, 2020


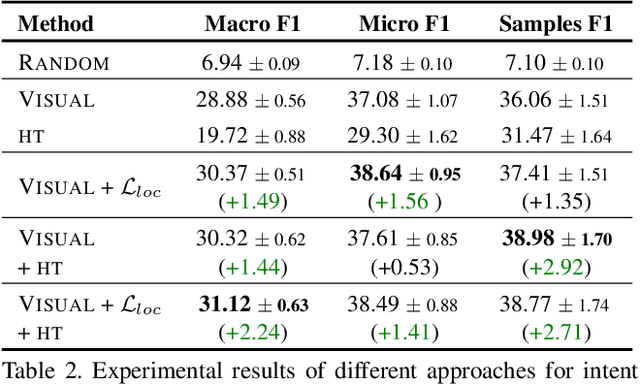
An image is worth a thousand words, conveying information that goes beyond the mere visual content therein. In this paper, we study the intent behind social media images with an aim to analyze how visual information can facilitate recognition of human intent. Towards this goal, we introduce an intent dataset, Intentonomy, comprising 14K images covering a wide range of everyday scenes. These images are manually annotated with 28 intent categories derived from a social psychology taxonomy. We then systematically study whether, and to what extent, commonly used visual information, i.e., object and context, contribute to human motive understanding. Based on our findings, we conduct further study to quantify the effect of attending to object and context classes as well as textual information in the form of hashtags when training an intent classifier. Our results quantitatively and qualitatively shed light on how visual and textual information can produce observable effects when predicting intent.
Deep Multi-Modal Sets
Mar 03, 2020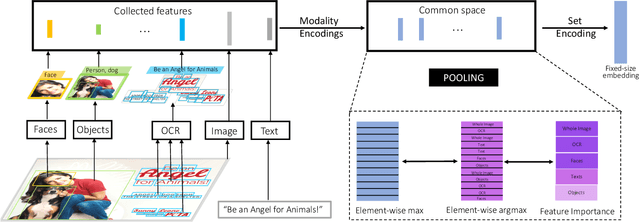

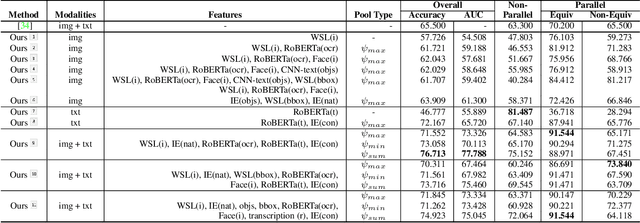

Many vision-related tasks benefit from reasoning over multiple modalities to leverage complementary views of data in an attempt to learn robust embedding spaces. Most deep learning-based methods rely on a late fusion technique whereby multiple feature types are encoded and concatenated and then a multi layer perceptron (MLP) combines the fused embedding to make predictions. This has several limitations, such as an unnatural enforcement that all features be present at all times as well as constraining only a constant number of occurrences of a feature modality at any given time. Furthermore, as more modalities are added, the concatenated embedding grows. To mitigate this, we propose Deep Multi-Modal Sets: a technique that represents a collection of features as an unordered set rather than one long ever-growing fixed-size vector. The set is constructed so that we have invariance both to permutations of the feature modalities as well as to the cardinality of the set. We will also show that with particular choices in our model architecture, we can yield interpretable feature performance such that during inference time we can observe which modalities are most contributing to the prediction.With this in mind, we demonstrate a scalable, multi-modal framework that reasons over different modalities to learn various types of tasks. We demonstrate new state-of-the-art performance on two multi-modal datasets (Ads-Parallelity [34] and MM-IMDb [1]).
Action Recognition Using Volumetric Motion Representations
Nov 19, 2019

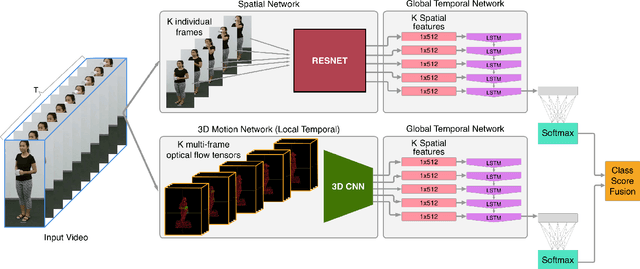
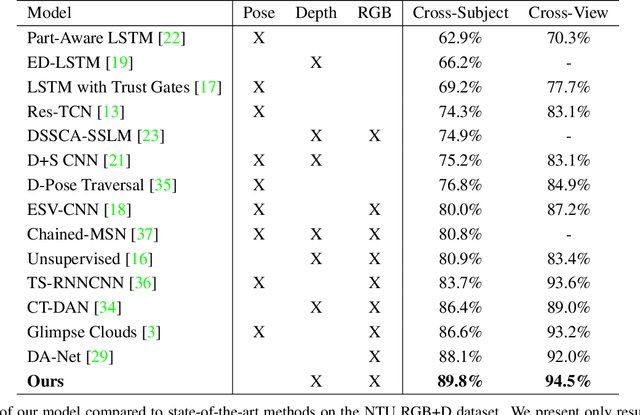
Traditional action recognition models are constructed around the paradigm of 2D perspective imagery. Though sophisticated time-series models have pushed the field forward, much of the information is still not exploited by confining the domain to 2D. In this work, we introduce a novel representation of motion as a voxelized 3D vector field and demonstrate how it can be used to improve performance of action recognition networks. This volumetric representation is a natural fit for 3D CNNs, and allows out-of-plane data augmentation techniques during training of these networks. Both the construction of this representation from RGB-D video and inference can be run in real time. We demonstrate superior results using this representation with our network design on the open-source NTU RGB+D dataset where it outperforms state-of-the-art on both of the defined evaluation metrics. Furthermore, we experimentally show how the out-of-plane augmentation techniques create viewpoint invariance and allow the model trained using this representation to generalize to unseen camera angles. Code is available here: https://github.com/mpeven/ntu_rgb.
Self-supervised Learning for Dense Depth Estimation in Monocular Endoscopy
Feb 20, 2019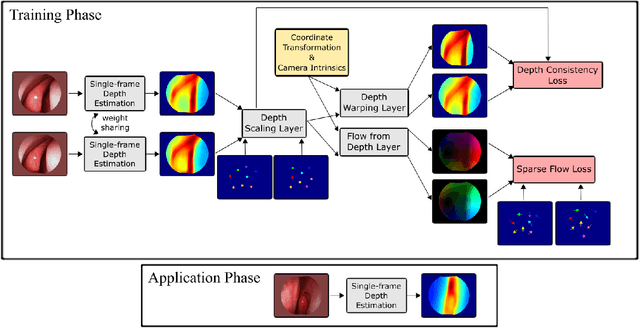
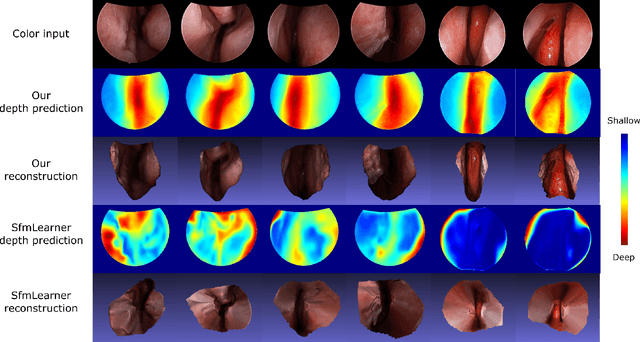
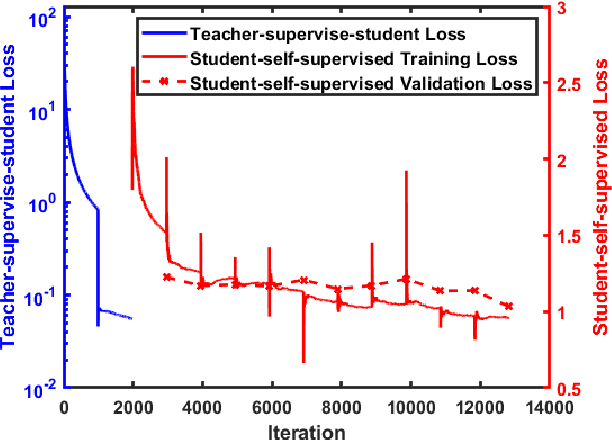
We present a self-supervised approach to training convolutional neural networks for dense depth estimation from monocular endoscopy data without a priori modeling of anatomy or shading. Our method only requires monocular endoscopic video and a multi-view stereo method, e.g. structure from motion, to supervise learning in a sparse manner. Consequently, our method requires neither manual labeling nor patient computed tomography (CT) scan in the training and application phases. In a cross-patient experiment using CT scans as groundtruth, the proposed method achieved submillimeter root mean squared error. In a comparison study to a recent self-supervised depth estimation method designed for natural video on in vivo sinus endoscopy data, we demonstrate that the proposed approach outperforms the previous method by a large margin. The source code for this work is publicly available online at https://github.com/lppllppl920/EndoscopyDepthEstimation-Pytorch.
Learning to See Forces: Surgical Force Prediction with RGB-Point Cloud Temporal Convolutional Networks
Jul 31, 2018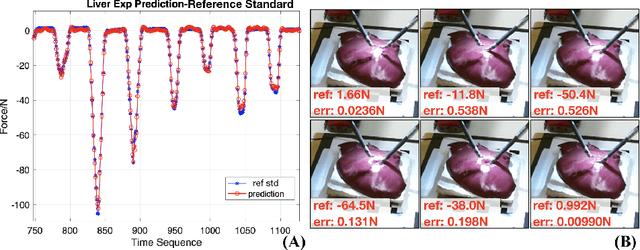
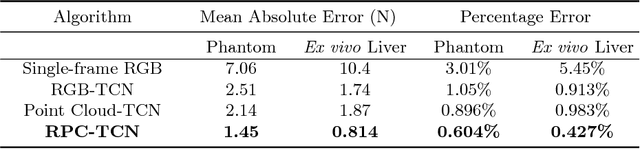

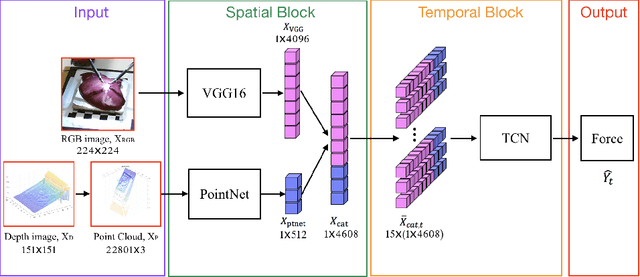
Robotic surgery has been proven to offer clear advantages during surgical procedures, however, one of the major limitations is obtaining haptic feedback. Since it is often challenging to devise a hardware solution with accurate force feedback, we propose the use of "visual cues" to infer forces from tissue deformation. Endoscopic video is a passive sensor that is freely available, in the sense that any minimally-invasive procedure already utilizes it. To this end, we employ deep learning to infer forces from video as an attractive low-cost and accurate alternative to typically complex and expensive hardware solutions. First, we demonstrate our approach in a phantom setting using the da Vinci Surgical System affixed with an OptoForce sensor. Second, we then validate our method on an ex vivo liver organ. Our method results in a mean absolute error of 0.814 N in the ex vivo study, suggesting that it may be a promising alternative to hardware based surgical force feedback in endoscopic procedures.
Towards automatic initialization of registration algorithms using simulated endoscopy images
Jun 28, 2018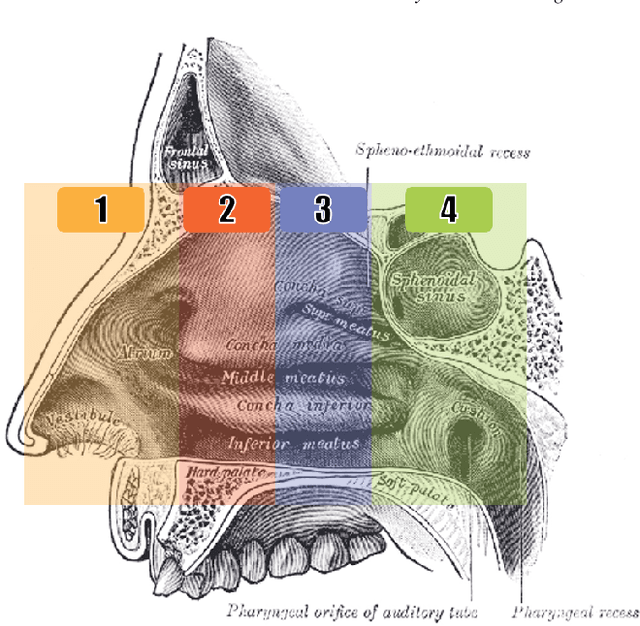
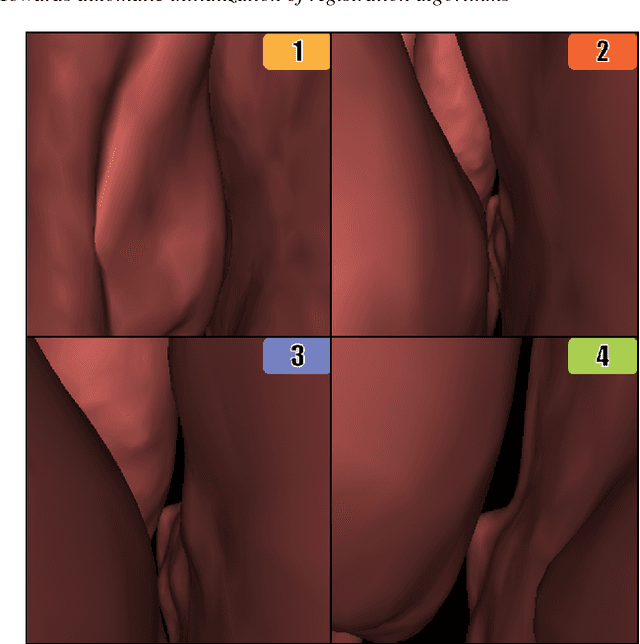
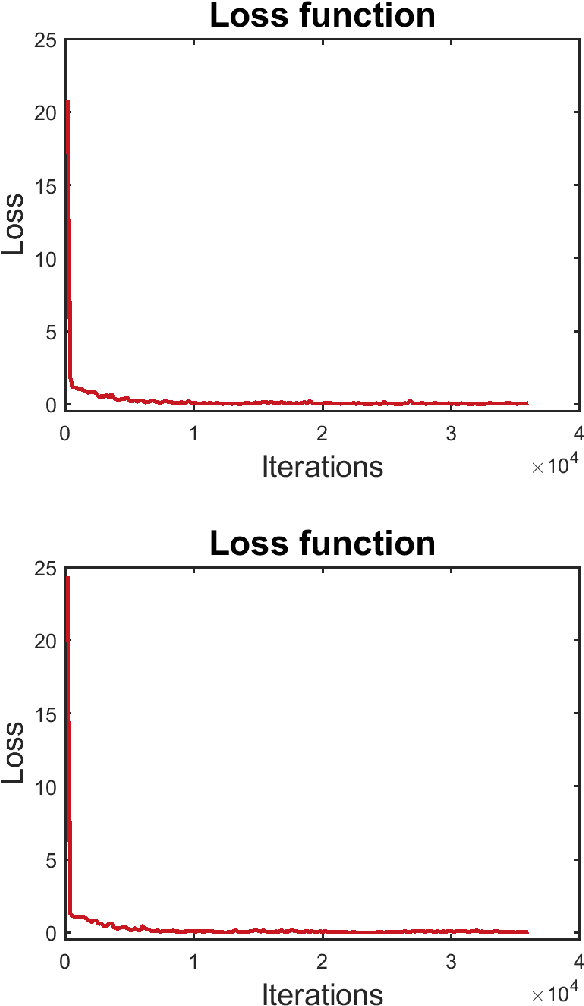
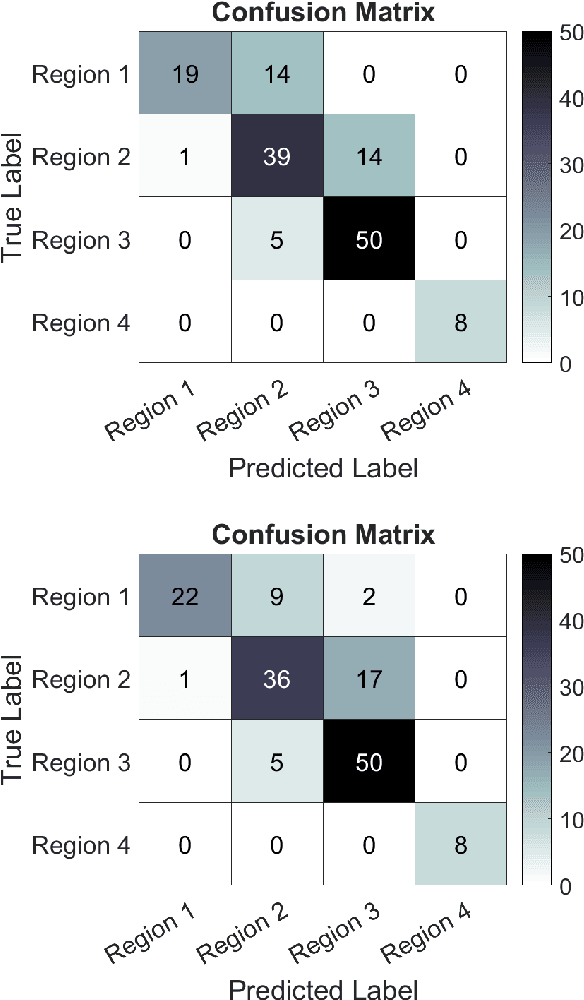
Registering images from different modalities is an active area of research in computer aided medical interventions. Several registration algorithms have been developed, many of which achieve high accuracy. However, these results are dependent on many factors, including the quality of the extracted features or segmentations being registered as well as the initial alignment. Although several methods have been developed towards improving segmentation algorithms and automating the segmentation process, few automatic initialization algorithms have been explored. In many cases, the initial alignment from which a registration is initiated is performed manually, which interferes with the clinical workflow. Our aim is to use scene classification in endoscopic procedures to achieve coarse alignment of the endoscope and a preoperative image of the anatomy. In this paper, we show using simulated scenes that a neural network can predict the region of anatomy (with respect to a preoperative image) that the endoscope is located in by observing a single endoscopic video frame. With limited training and without any hyperparameter tuning, our method achieves an accuracy of 76.53 (+/-1.19)%. There are several avenues for improvement, making this a promising direction of research. Code is available at https://github.com/AyushiSinha/AutoInitialization.
Endoscopic navigation in the absence of CT imaging
Jun 08, 2018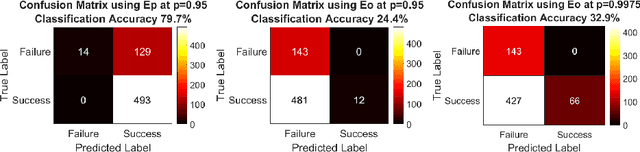
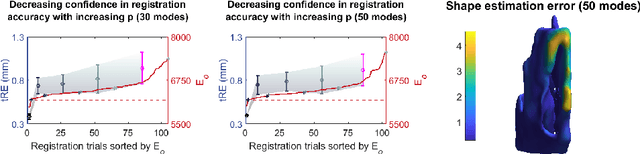
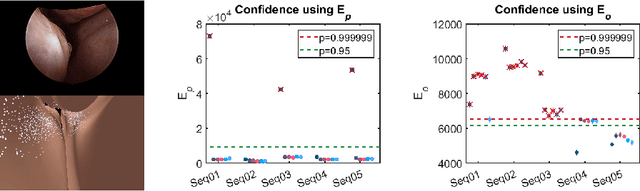
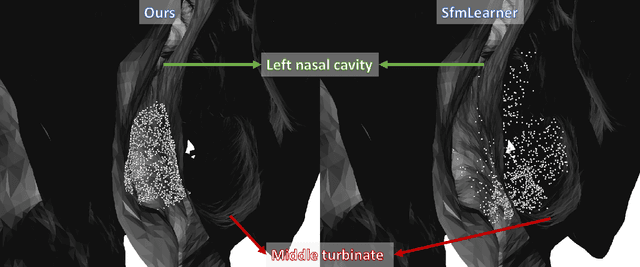
Clinical examinations that involve endoscopic exploration of the nasal cavity and sinuses often do not have a reference image to provide structural context to the clinician. In this paper, we present a system for navigation during clinical endoscopic exploration in the absence of computed tomography (CT) scans by making use of shape statistics from past CT scans. Using a deformable registration algorithm along with dense reconstructions from video, we show that we are able to achieve submillimeter registrations in in-vivo clinical data and are able to assign confidence to these registrations using confidence criteria established using simulated data.