 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegSTRONG-C: Segmenting Surgical Tools Robustly On Non-adversarial Generated Corruptions -- An EndoVis'24 Challenge
Jul 16, 2024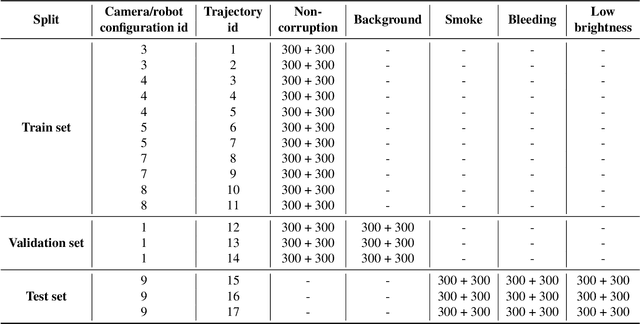


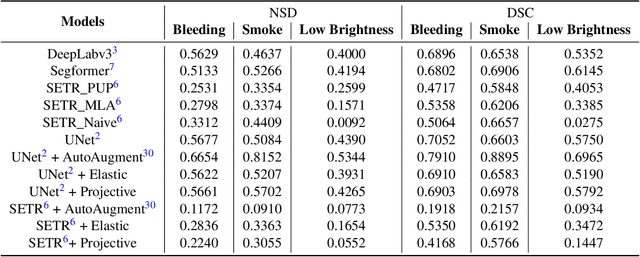
Accurate segmentation of tools in robot-assisted surgery is critical for machine perception, as it facilitates numerous downstream tasks including augmented reality feedback. While current feed-forward neural network-based methods exhibit excellent segmentation performance under ideal conditions, these models have proven susceptible to even minor corruptions, significantly impairing the model's performance. This vulnerability is especially problematic in surgical settings where predictions might be used to inform high-stakes decisions. To better understand model behavior under non-adversarial corruptions, prior work has explored introducing artificial corruptions, like Gaussian noise or contrast perturbation to test set images, to assess model robustness. However, these corruptions are either not photo-realistic or model/task agnostic. Thus, these investigations provide limited insights into model deterioration under realistic surgical corruptions. To address this limitation, we introduce the SegSTRONG-C challenge that aims to promote the development of algorithms robust to unforeseen but plausible image corruptions of surgery, like smoke, bleeding, and low brightness. We collect and release corruption-free mock endoscopic video sequences for the challenge participants to train their algorithms and benchmark them on video sequences with photo-realistic non-adversarial corruptions for a binary robot tool segmentation task. This new benchmark will allow us to carefully study neural network robustness to non-adversarial corruptions of surgery, thus constituting an important first step towards more robust models for surgical computer vision. In this paper, we describe the data collection and annotation protocol, baseline evaluations of established segmentation models, and data augmentation-based techniques to enhance model robustness.
SyntheX: Scaling Up Learning-based X-ray Image Analysis Through In Silico Experiments
Jun 13, 2022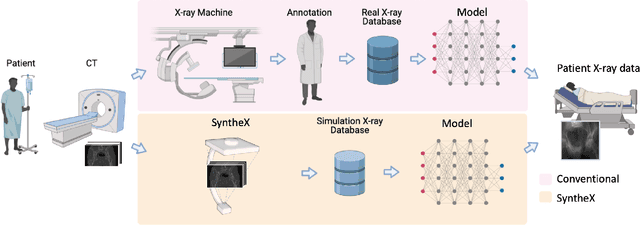

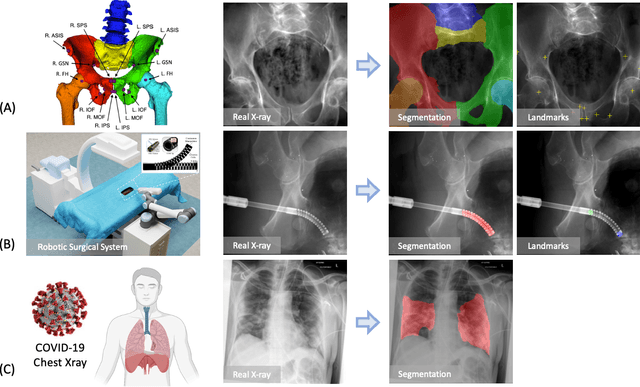

Artificial intelligence (AI) now enables automated interpretation of medical images for clinical use. However, AI's potential use for interventional images (versus those involved in triage or diagnosis), such as for guidance during surgery, remains largely untapped. This is because surgical AI systems are currently trained using post hoc analysis of data collected during live surgeries, which has fundamental and practical limitations, including ethical considerations, expense, scalability, data integrity, and a lack of ground truth. Here, we demonstrate that creating realistic simulated images from human models is a viable alternative and complement to large-scale in situ data collection. We show that training AI image analysis models on realistically synthesized data, combined with contemporary domain generalization or adaptation techniques, results in models that on real data perform comparably to models trained on a precisely matched real data training set. Because synthetic generation of training data from human-based models scales easily, we find that our model transfer paradigm for X-ray image analysis, which we refer to as SyntheX, can even outperform real data-trained models due to the effectiveness of training on a larger dataset. We demonstrate the potential of SyntheX on three clinical tasks: Hip image analysis, surgical robotic tool detection, and COVID-19 lung lesion segmentation. SyntheX provides an opportunity to drastically accelerate the conception, design, and evaluation of intelligent systems for X-ray-based medicine. In addition, simulated image environments provide the opportunity to test novel instrumentation, design complementary surgical approaches, and envision novel techniques that improve outcomes, save time, or mitigate human error, freed from the ethical and practical considerations of live human data collection.
RGB-D Semantic SLAM for Surgical Robot Navigation in the Operating Room
Apr 12, 2022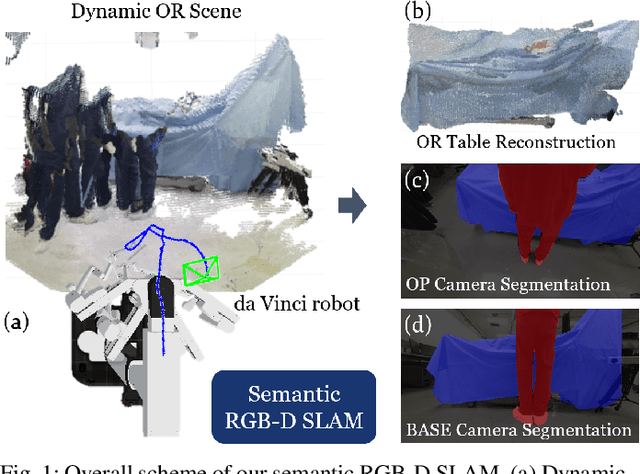
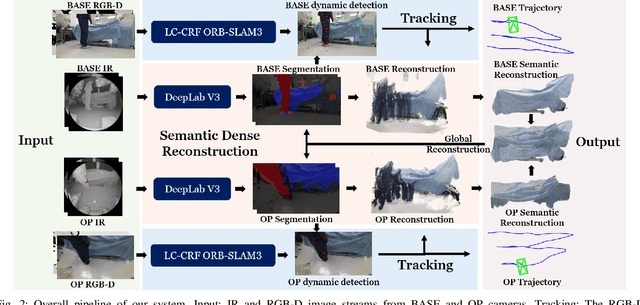


Gaining spatial awareness of the Operating Room (OR) for surgical robotic systems is a key technology that can enable intelligent applications aiming at improved OR workflow. In this work, we present a method for semantic dense reconstruction of the OR scene using multiple RGB-D cameras attached and registered to the da Vinci Xi surgical system. We developed a novel SLAM approach for robot pose tracking in dynamic OR environments and dense reconstruction of the static OR table object. We validated our techniques in a mock OR by collecting data sequences with corresponding optical tracking trajectories as ground truth and manually annotated 100 frame segmentation masks. The mean absolute trajectory error is $11.4\pm1.9$ mm and the mean relative pose error is $1.53\pm0.48$ degrees per second. The segmentation DICE score is improved from 0.814 to 0.902 by using our SLAM system compared to single frame. Our approach effectively produces a dense OR table reconstruction in dynamic clinical environments as well as improved semantic segmentation on individual image frames.
The Impact of Machine Learning on 2D/3D Registration for Image-guided Interventions: A Systematic Review and Perspective
Aug 04, 2021
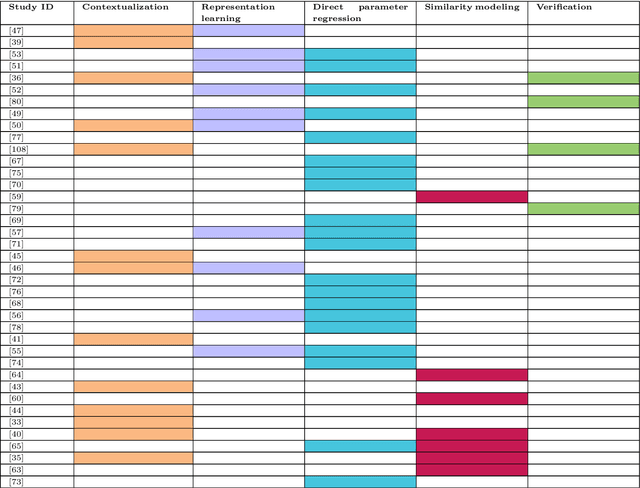

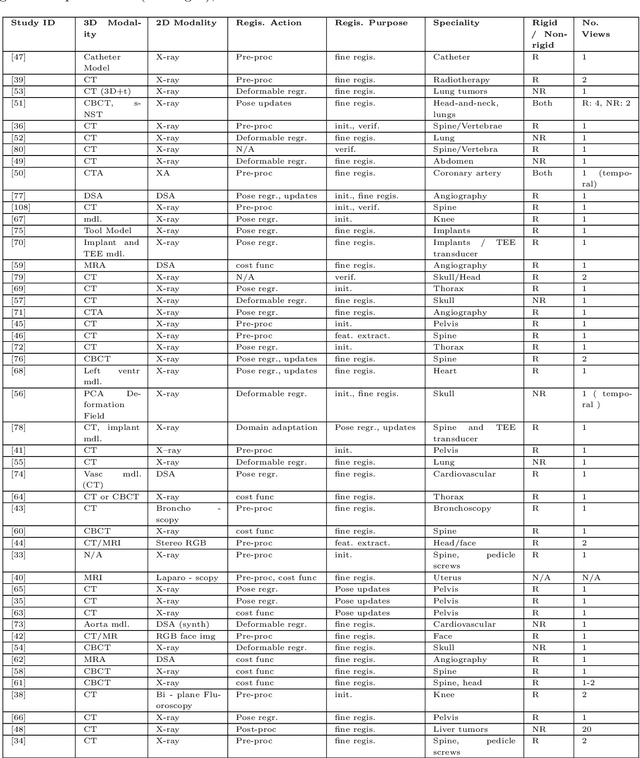
Image-based navigation is widely considered the next frontier of minimally invasive surgery. It is believed that image-based navigation will increase the access to reproducible, safe, and high-precision surgery as it may then be performed at acceptable costs and effort. This is because image-based techniques avoid the need of specialized equipment and seamlessly integrate with contemporary workflows. Further, it is expected that image-based navigation will play a major role in enabling mixed reality environments and autonomous, robotic workflows. A critical component of image guidance is 2D/3D registration, a technique to estimate the spatial relationships between 3D structures, e.g., volumetric imagery or tool models, and 2D images thereof, such as fluoroscopy or endoscopy. While image-based 2D/3D registration is a mature technique, its transition from the bench to the bedside has been restrained by well-known challenges, including brittleness of the optimization objective, hyperparameter selection, and initialization, difficulties around inconsistencies or multiple objects, and limited single-view performance. One reason these challenges persist today is that analytical solutions are likely inadequate considering the complexity, variability, and high-dimensionality of generic 2D/3D registration problems. The recent advent of machine learning-based approaches to imaging problems that, rather than specifying the desired functional mapping, approximate it using highly expressive parametric models holds promise for solving some of the notorious challenges in 2D/3D registration. In this manuscript, we review the impact of machine learning on 2D/3D registration to systematically summarize the recent advances made by introduction of this novel technology. Grounded in these insights, we then offer our perspective on the most pressing needs, significant open problems, and possible next steps.
A Learning-based Method for Online Adjustment of C-arm Cone-Beam CT Source Trajectories for Artifact Avoidance
Aug 14, 2020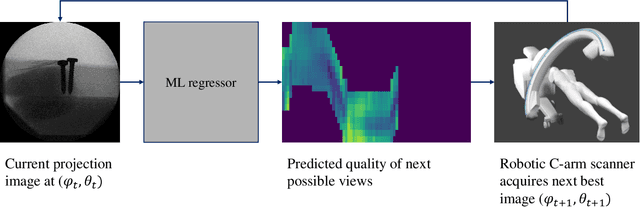
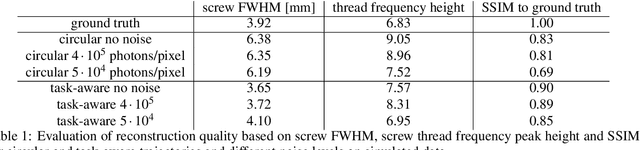
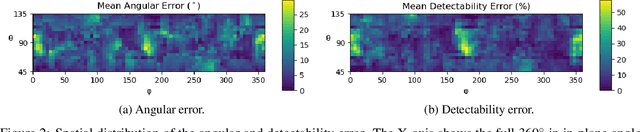
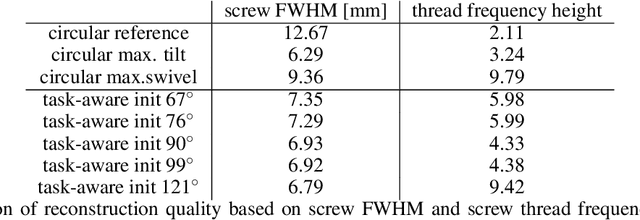
During spinal fusion surgery, screws are placed close to critical nerves suggesting the need for highly accurate screw placement. Verifying screw placement on high-quality tomographic imaging is essential. C-arm Cone-beam CT (CBCT) provides intraoperative 3D tomographic imaging which would allow for immediate verification and, if needed, revision. However, the reconstruction quality attainable with commercial CBCT devices is insufficient, predominantly due to severe metal artifacts in the presence of pedicle screws. These artifacts arise from a mismatch between the true physics of image formation and an idealized model thereof assumed during reconstruction. Prospectively acquiring views onto anatomy that are least affected by this mismatch can, therefore, improve reconstruction quality. We propose to adjust the C-arm CBCT source trajectory during the scan to optimize reconstruction quality with respect to a certain task, i.e. verification of screw placement. Adjustments are performed on-the-fly using a convolutional neural network that regresses a quality index for possible next views given the current x-ray image. Adjusting the CBCT trajectory to acquire the recommended views results in non-circular source orbits that avoid poor images, and thus, data inconsistencies. We demonstrate that convolutional neural networks trained on realistically simulated data are capable of predicting quality metrics that enable scene-specific adjustments of the CBCT source trajectory. Using both realistically simulated data and real CBCT acquisitions of a semi-anthropomorphic phantom, we show that tomographic reconstructions of the resulting scene-specific CBCT acquisitions exhibit improved image quality particularly in terms of metal artifacts. Since the optimization objective is implicitly encoded in a neural network, the proposed approach overcomes the need for 3D information at run-time.
Generalizing Spatial Transformers to Projective Geometry with Applications to 2D/3D Registration
Mar 24, 2020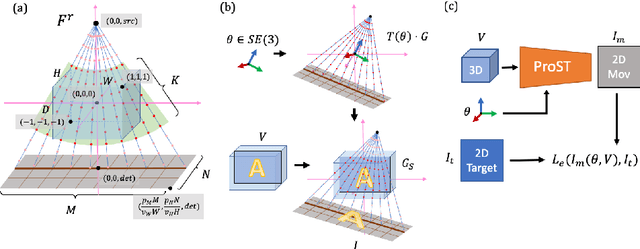
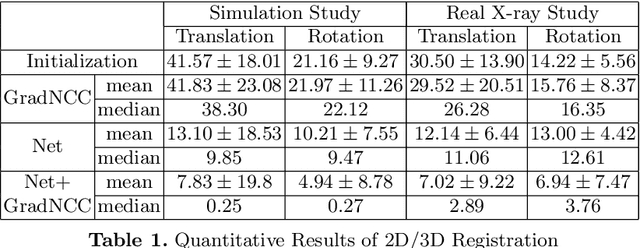
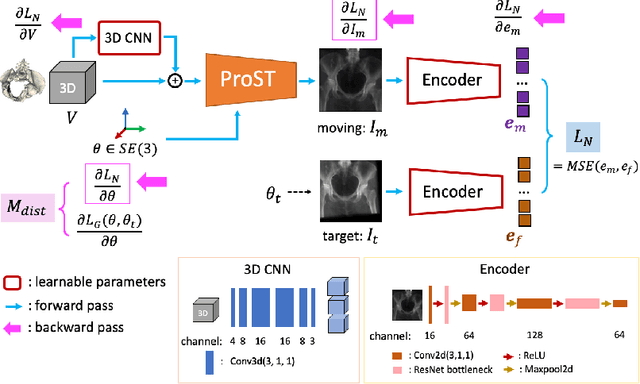
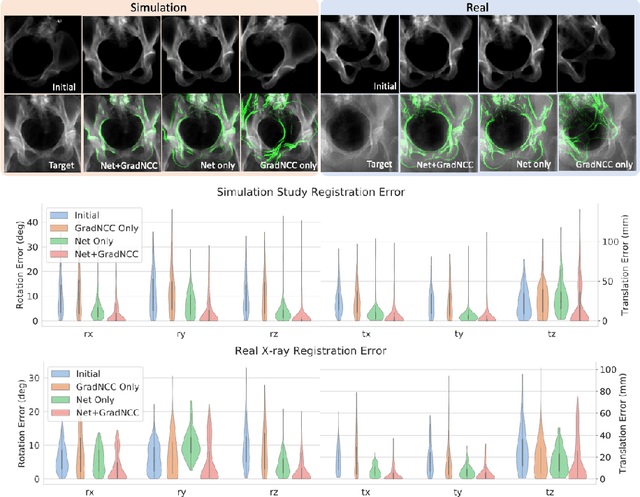
Differentiable rendering is a technique to connect 3D scenes with corresponding 2D images. Since it is differentiable, processes during image formation can be learned. Previous approaches to differentiable rendering focus on mesh-based representations of 3D scenes, which is inappropriate for medical applications where volumetric, voxelized models are used to represent anatomy. We propose a novel Projective Spatial Transformer module that generalizes spatial transformers to projective geometry, thus enabling differentiable volume rendering. We demonstrate the usefulness of this architecture on the example of 2D/3D registration between radiographs and CT scans. Specifically, we show that our transformer enables end-to-end learning of an image processing and projection model that approximates an image similarity function that is convex with respect to the pose parameters, and can thus be optimized effectively using conventional gradient descent. To the best of our knowledge, this is the first time that spatial transformers have been described for projective geometry. The source code will be made public upon publication of this manuscript and we hope that our developments will benefit related 3D research applications.
2018 Robotic Scene Segmentation Challenge
Feb 03, 2020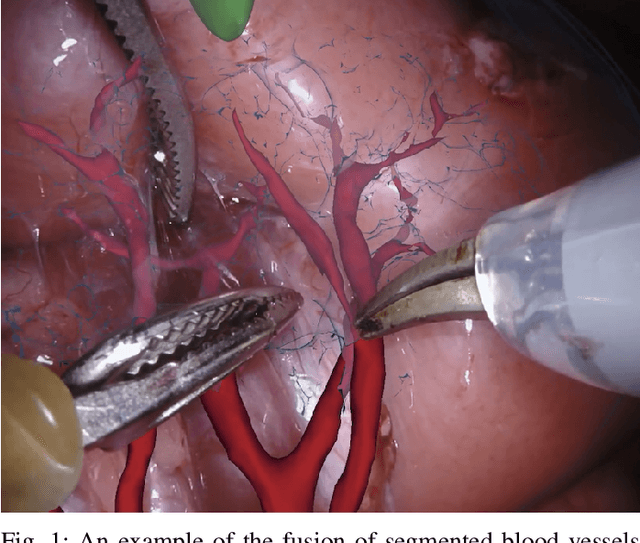
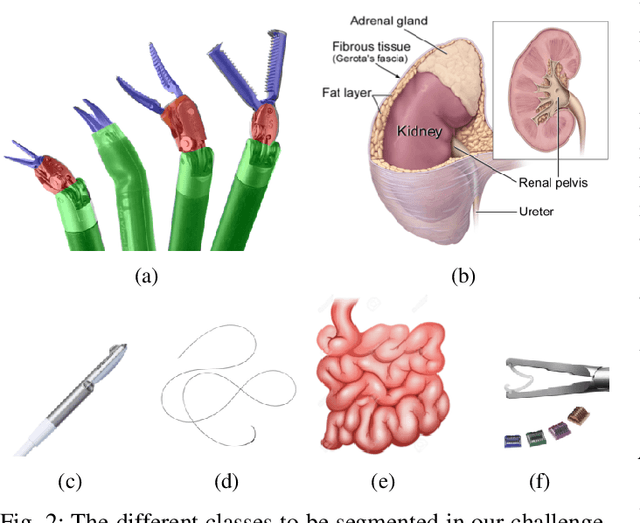
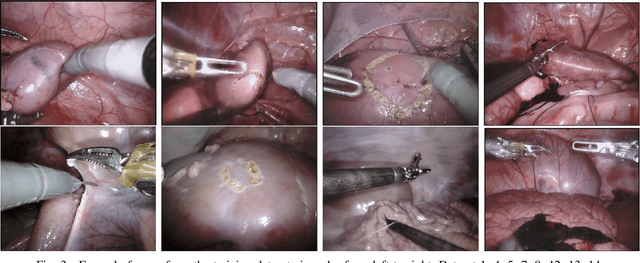
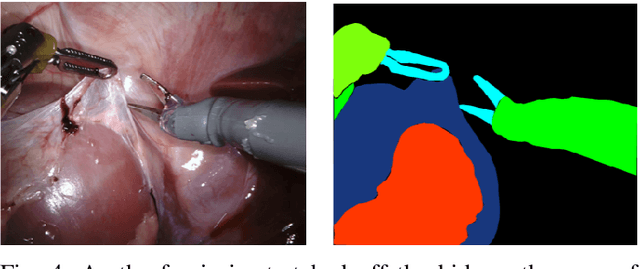
In 2015 we began a sub-challenge at the EndoVis workshop at MICCAI in Munich using endoscope images of ex-vivo tissue with automatically generated annotations from robot forward kinematics and instrument CAD models. However, the limited background variation and simple motion rendered the dataset uninformative in learning about which techniques would be suitable for segmentation in real surgery. In 2017, at the same workshop in Quebec we introduced the robotic instrument segmentation dataset with 10 teams participating in the challenge to perform binary, articulating parts and type segmentation of da Vinci instruments. This challenge included realistic instrument motion and more complex porcine tissue as background and was widely addressed with modifications on U-Nets and other popular CNN architectures. In 2018 we added to the complexity by introducing a set of anatomical objects and medical devices to the segmented classes. To avoid over-complicating the challenge, we continued with porcine data which is dramatically simpler than human tissue due to the lack of fatty tissue occluding many organs.
Automatic Annotation of Hip Anatomy in Fluoroscopy for Robust and Efficient 2D/3D Registration
Nov 16, 2019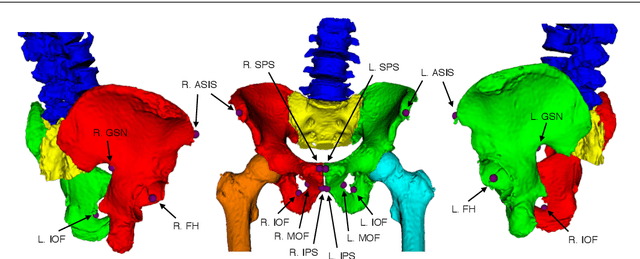

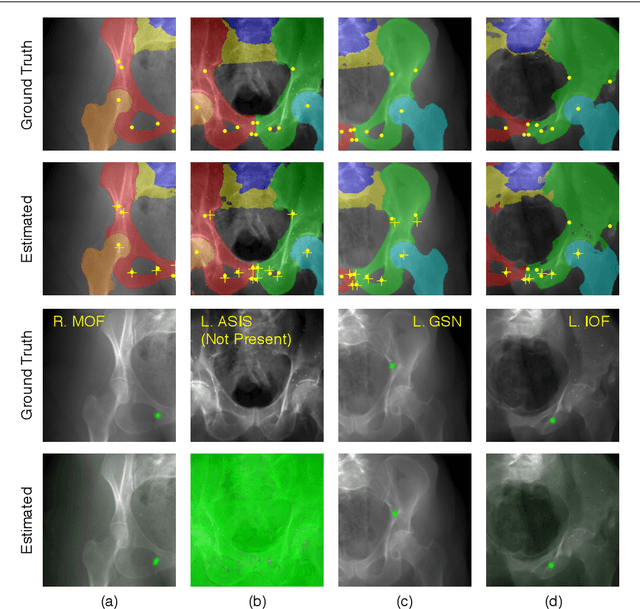

Fluoroscopy is the standard imaging modality used to guide hip surgery and is therefore a natural sensor for computer-assisted navigation. In order to efficiently solve the complex registration problems presented during navigation, human-assisted annotations of the intraoperative image are typically required. This manual initialization interferes with the surgical workflow and diminishes any advantages gained from navigation. We propose a method for fully automatic registration using annotations produced by a neural network. Neural networks are trained to simultaneously segment anatomy and identify landmarks in fluoroscopy. Training data is obtained using an intraoperatively incompatible 2D/3D registration of hip anatomy. Ground truth 2D labels are established using projected 3D annotations. Intraoperative registration couples an intensity-based strategy with annotations inferred by the network and requires no human assistance. Ground truth labels were obtained in 366 fluoroscopic images across 6 cadaveric specimens. In a leave-one-subject-out experiment, networks obtained mean dice coefficients for left and right hemipelves, left and right femurs of 0.86, 0.87, 0.90, and 0.84. The mean 2D landmark error was 5.0 mm. The pelvis was registered within 1 degree for 86% of the images when using the proposed intraoperative approach with an average runtime of 7 seconds. In comparison, an intensity-only approach without manual initialization, registered the pelvis to 1 degree in 18% of images. We have created the first accurately annotated, non-synthetic, dataset of hip fluoroscopy. By using these annotations as training data for neural networks, state of the art performance in fluoroscopic segmentation and landmark localization was achieved. Integrating these annotations allows for a robust, fully automatic, and efficient intraoperative registration during fluoroscopic navigation of the hip.
Learning to Avoid Poor Images: Towards Task-aware C-arm Cone-beam CT Trajectories
Sep 19, 2019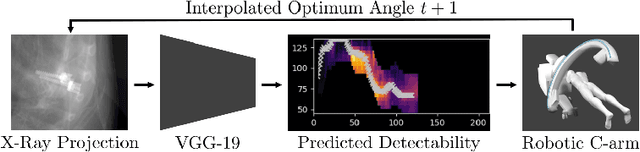
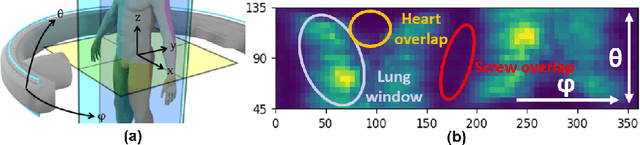

Metal artifacts in computed tomography (CT) arise from a mismatch between physics of image formation and idealized assumptions during tomographic reconstruction. These artifacts are particularly strong around metal implants, inhibiting widespread adoption of 3D cone-beam CT (CBCT) despite clear opportunity for intra-operative verification of implant positioning, e.g. in spinal fusion surgery. On synthetic and real data, we demonstrate that much of the artifact can be avoided by acquiring better data for reconstruction in a task-aware and patient-specific manner, and describe the first step towards the envisioned task-aware CBCT protocol. The traditional short-scan CBCT trajectory is planar, with little room for scene-specific adjustment. We extend this trajectory by autonomously adjusting out-of-plane angulation. This enables C-arm source trajectories that are scene-specific in that they avoid acquiring "poor images", characterized by beam hardening, photon starvation, and noise. The recommendation of ideal out-of-plane angulation is performed on-the-fly using a deep convolutional neural network that regresses a detectability-rank derived from imaging physics.
Learning to See Forces: Surgical Force Prediction with RGB-Point Cloud Temporal Convolutional Networks
Jul 31, 2018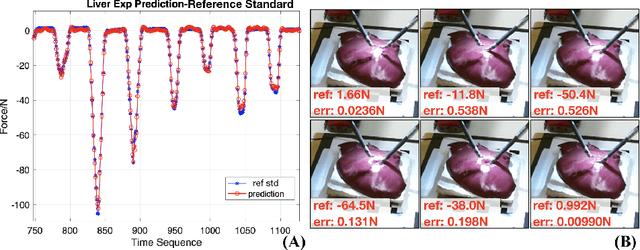
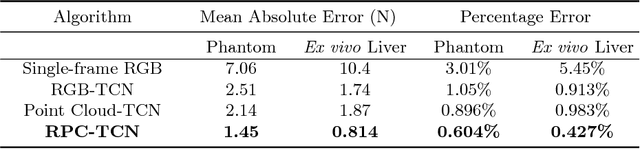

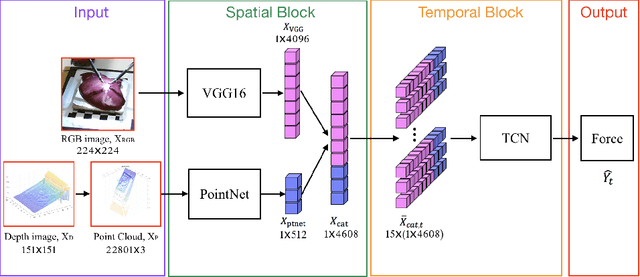
Robotic surgery has been proven to offer clear advantages during surgical procedures, however, one of the major limitations is obtaining haptic feedback. Since it is often challenging to devise a hardware solution with accurate force feedback, we propose the use of "visual cues" to infer forces from tissue deformation. Endoscopic video is a passive sensor that is freely available, in the sense that any minimally-invasive procedure already utilizes it. To this end, we employ deep learning to infer forces from video as an attractive low-cost and accurate alternative to typically complex and expensive hardware solutions. First, we demonstrate our approach in a phantom setting using the da Vinci Surgical System affixed with an OptoForce sensor. Second, we then validate our method on an ex vivo liver organ. Our method results in a mean absolute error of 0.814 N in the ex vivo study, suggesting that it may be a promising alternative to hardware based surgical force feedback in endoscopic procedures.