 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtremely Dense Point Correspondences using a Learned Feature Descriptor
Mar 27, 2020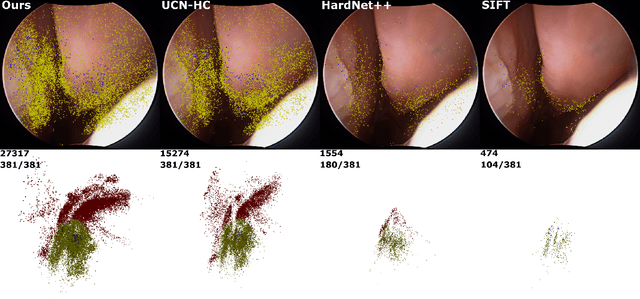

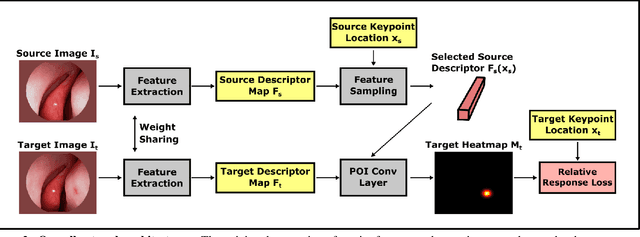
High-quality 3D reconstructions from endoscopy video play an important role in many clinical applications, including surgical navigation where they enable direct video-CT registration. While many methods exist for general multi-view 3D reconstruction, these methods often fail to deliver satisfactory performance on endoscopic video. Part of the reason is that local descriptors that establish pair-wise point correspondences, and thus drive reconstruction, struggle when confronted with the texture-scarce surface of anatomy. Learning-based dense descriptors usually have larger receptive fields enabling the encoding of global information, which can be used to disambiguate matches. In this work, we present an effective self-supervised training scheme and novel loss design for dense descriptor learning. In direct comparison to recent local and dense descriptors on an in-house sinus endoscopy dataset, we demonstrate that our proposed dense descriptor can generalize to unseen patients and scopes, thereby largely improving the performance of Structure from Motion (SfM) in terms of model density and completeness. We also evaluate our method on a public dense optical flow dataset and a small-scale SfM public dataset to further demonstrate the effectiveness and generality of our method. The source code is available at https://github.com/lppllppl920/DenseDescriptorLearning-Pytorch.
Generalizing Spatial Transformers to Projective Geometry with Applications to 2D/3D Registration
Mar 24, 2020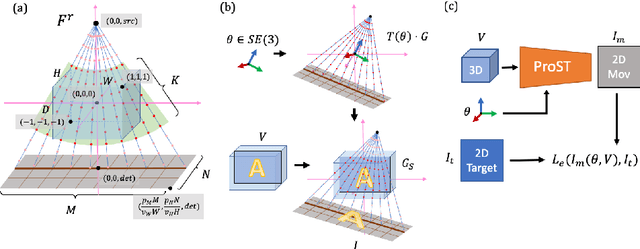
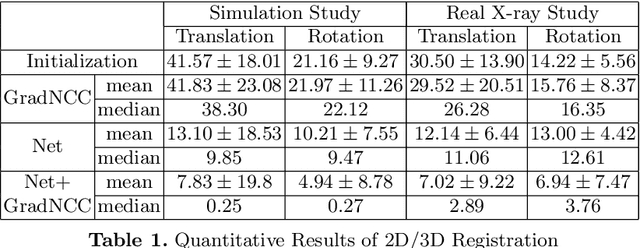
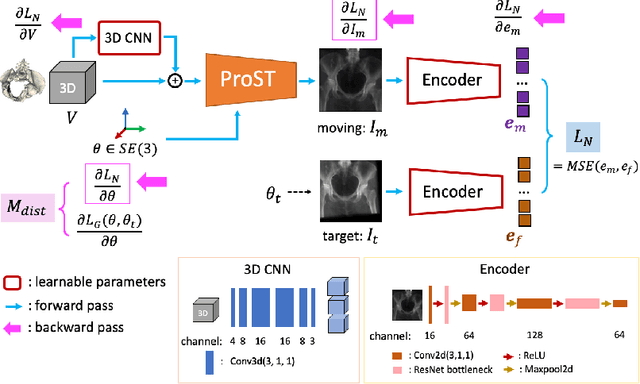
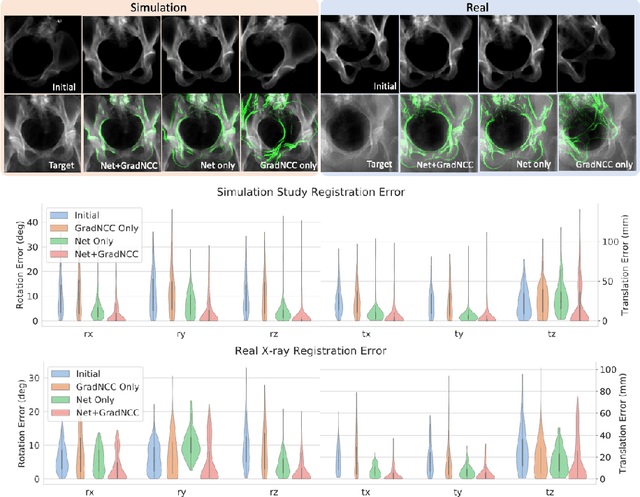
Differentiable rendering is a technique to connect 3D scenes with corresponding 2D images. Since it is differentiable, processes during image formation can be learned. Previous approaches to differentiable rendering focus on mesh-based representations of 3D scenes, which is inappropriate for medical applications where volumetric, voxelized models are used to represent anatomy. We propose a novel Projective Spatial Transformer module that generalizes spatial transformers to projective geometry, thus enabling differentiable volume rendering. We demonstrate the usefulness of this architecture on the example of 2D/3D registration between radiographs and CT scans. Specifically, we show that our transformer enables end-to-end learning of an image processing and projection model that approximates an image similarity function that is convex with respect to the pose parameters, and can thus be optimized effectively using conventional gradient descent. To the best of our knowledge, this is the first time that spatial transformers have been described for projective geometry. The source code will be made public upon publication of this manuscript and we hope that our developments will benefit related 3D research applications.
"Good Robot!": Efficient Reinforcement Learning for Multi-Step Visual Tasks via Reward Shaping
Sep 25, 2019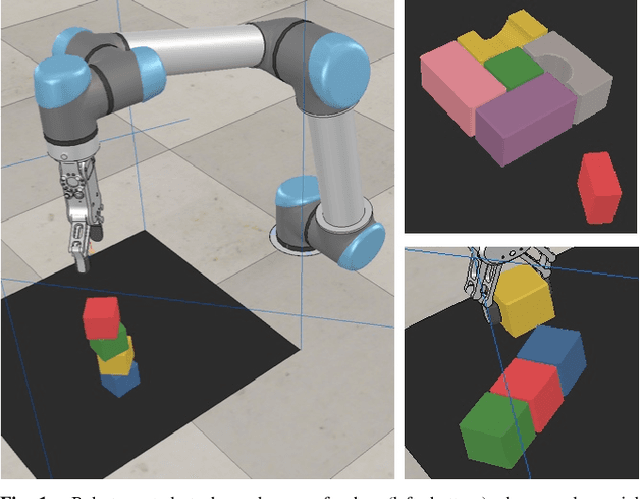
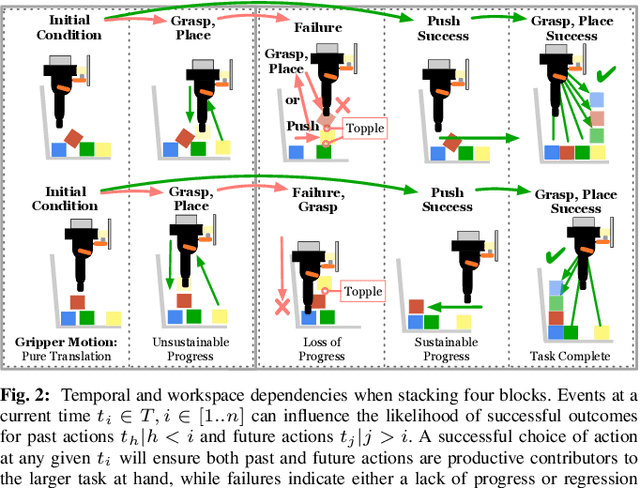
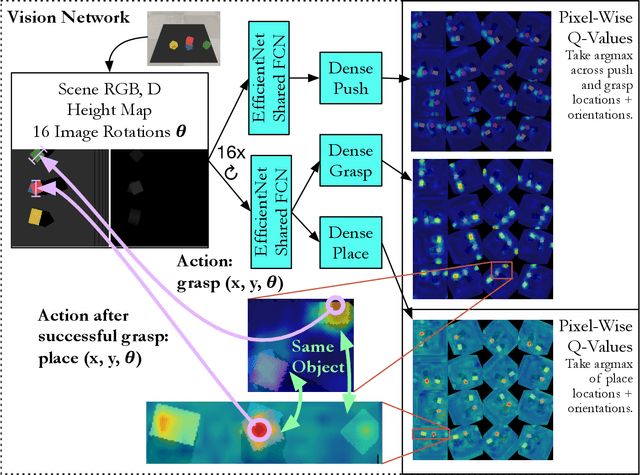
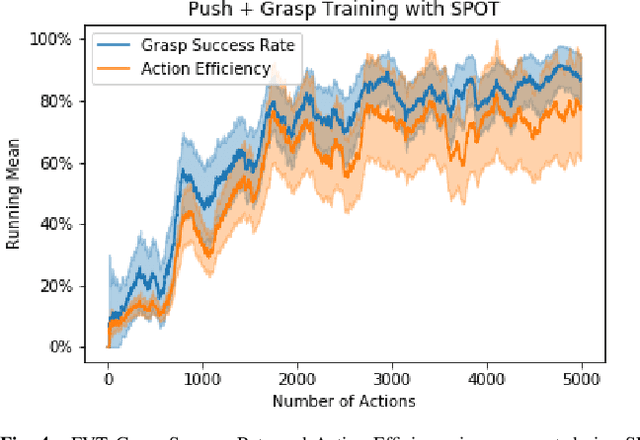
In order to learn effectively, robots must be able to extract the intangible context by which task progress and mistakes are defined. In the domain of reinforcement learning, much of this information is provided by the reward function. Hence, reward shaping is a necessary part of how we can achieve state-of-the-art results on complex, multi-step tasks. However, comparatively little work has examined how reward shaping should be done so that it captures task context, particularly in scenarios where the task is long-horizon and failure is highly consequential. Our Schedule for Positive Task (SPOT) reward trains our Efficient Visual Task (EVT) model to solve problems that require an understanding of both task context and workspace constraints of multi-step block arrangement tasks. In simulation EVT can completely clear adversarial arrangements of objects by pushing and grasping in 99% of cases vs an 82% baseline in prior work. For random arrangements EVT clears 100% of test cases at 86% action efficiency vs 61% efficiency in prior work. EVT + SPOT is also able to demonstrate context understanding and complete stacks in 74% of trials compared to a baseline of 5% with EVT alone. To our knowledge, this is the first instance of a Reinforcement Learning based algorithm successfully completing such a challenge. Code is available at https://github.com/jhu-lcsr/good_robot .