 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigenlanes: Data-Driven Lane Descriptors for Structurally Diverse Lanes
Mar 29, 2022
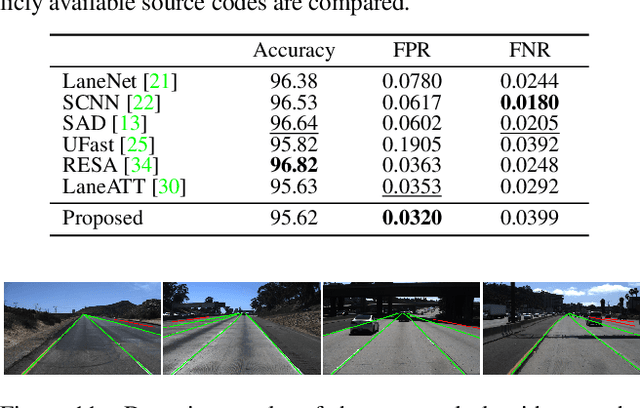
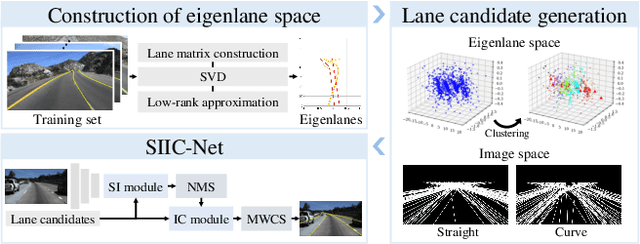
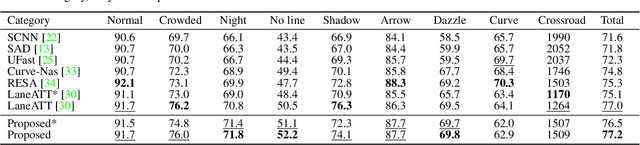
A novel algorithm to detect road lanes in the eigenlane space is proposed in this paper. First, we introduce the notion of eigenlanes, which are data-driven descriptors for structurally diverse lanes, including curved, as well as straight, lanes. To obtain eigenlanes, we perform the best rank-M approximation of a lane matrix containing all lanes in a training set. Second, we generate a set of lane candidates by clustering the training lanes in the eigenlane space. Third, using the lane candidates, we determine an optimal set of lanes by developing an anchor-based detection network, called SIIC-Net. Experimental results demonstrate that the proposed algorithm provides excellent detection performance for structurally diverse lanes. Our codes are available at https://github.com/dongkwonjin/Eigenlanes.
"Good Robot!": Efficient Reinforcement Learning for Multi-Step Visual Tasks via Reward Shaping
Sep 25, 2019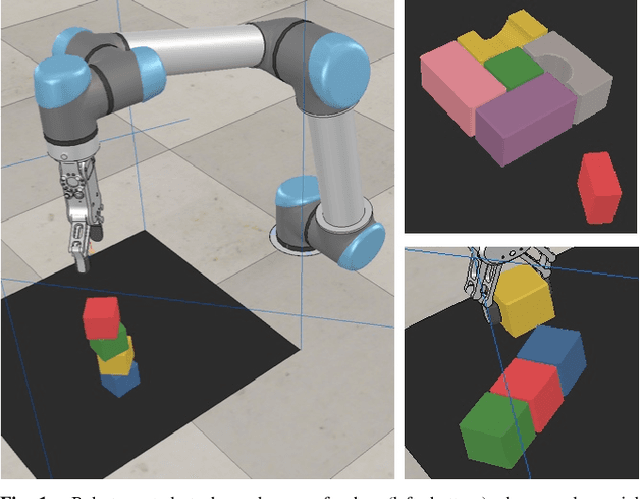
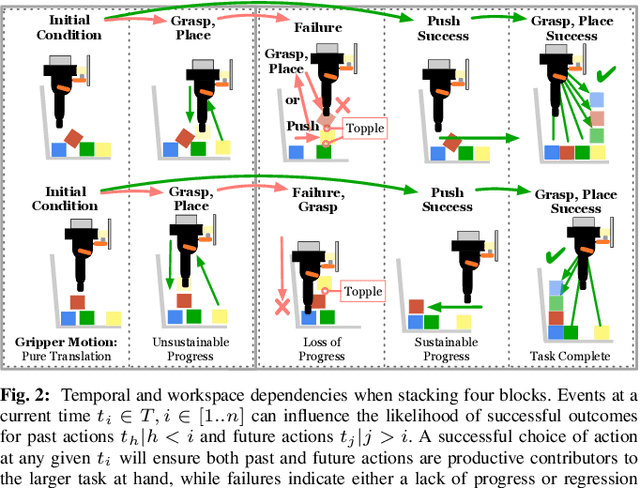
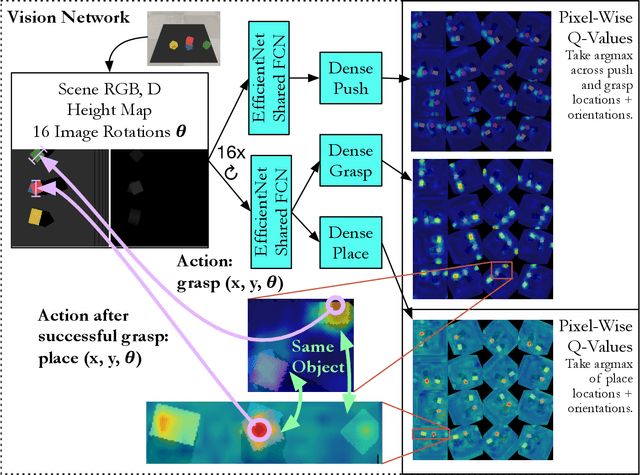
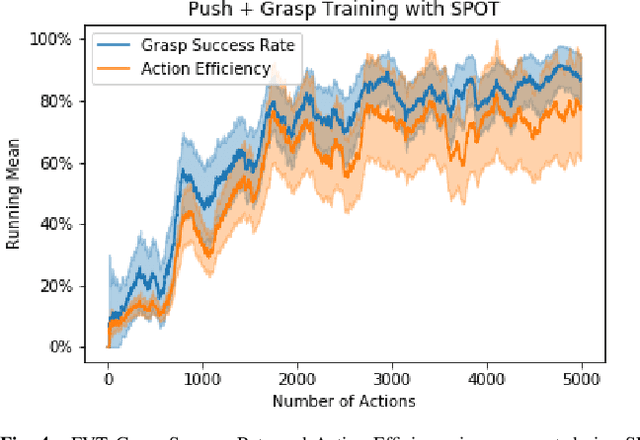
In order to learn effectively, robots must be able to extract the intangible context by which task progress and mistakes are defined. In the domain of reinforcement learning, much of this information is provided by the reward function. Hence, reward shaping is a necessary part of how we can achieve state-of-the-art results on complex, multi-step tasks. However, comparatively little work has examined how reward shaping should be done so that it captures task context, particularly in scenarios where the task is long-horizon and failure is highly consequential. Our Schedule for Positive Task (SPOT) reward trains our Efficient Visual Task (EVT) model to solve problems that require an understanding of both task context and workspace constraints of multi-step block arrangement tasks. In simulation EVT can completely clear adversarial arrangements of objects by pushing and grasping in 99% of cases vs an 82% baseline in prior work. For random arrangements EVT clears 100% of test cases at 86% action efficiency vs 61% efficiency in prior work. EVT + SPOT is also able to demonstrate context understanding and complete stacks in 74% of trials compared to a baseline of 5% with EVT alone. To our knowledge, this is the first instance of a Reinforcement Learning based algorithm successfully completing such a challenge. Code is available at https://github.com/jhu-lcsr/good_robot .