 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegSTRONG-C: Segmenting Surgical Tools Robustly On Non-adversarial Generated Corruptions -- An EndoVis'24 Challenge
Paper and Code
Jul 16, 2024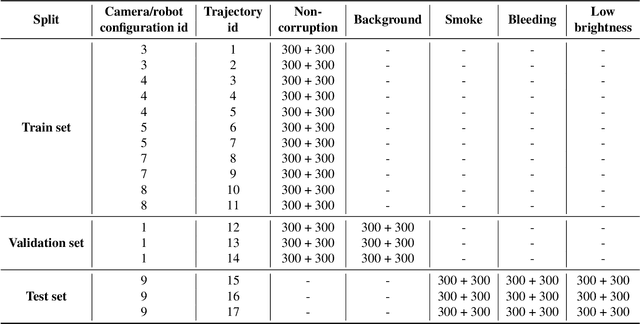


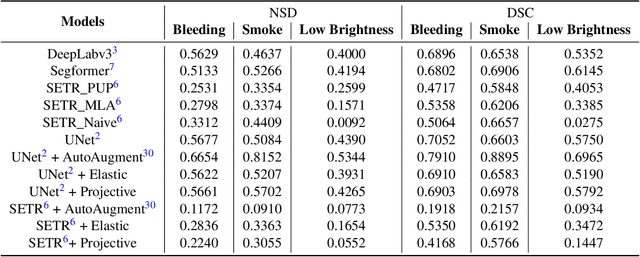
Accurate segmentation of tools in robot-assisted surgery is critical for machine perception, as it facilitates numerous downstream tasks including augmented reality feedback. While current feed-forward neural network-based methods exhibit excellent segmentation performance under ideal conditions, these models have proven susceptible to even minor corruptions, significantly impairing the model's performance. This vulnerability is especially problematic in surgical settings where predictions might be used to inform high-stakes decisions. To better understand model behavior under non-adversarial corruptions, prior work has explored introducing artificial corruptions, like Gaussian noise or contrast perturbation to test set images, to assess model robustness. However, these corruptions are either not photo-realistic or model/task agnostic. Thus, these investigations provide limited insights into model deterioration under realistic surgical corruptions. To address this limitation, we introduce the SegSTRONG-C challenge that aims to promote the development of algorithms robust to unforeseen but plausible image corruptions of surgery, like smoke, bleeding, and low brightness. We collect and release corruption-free mock endoscopic video sequences for the challenge participants to train their algorithms and benchmark them on video sequences with photo-realistic non-adversarial corruptions for a binary robot tool segmentation task. This new benchmark will allow us to carefully study neural network robustness to non-adversarial corruptions of surgery, thus constituting an important first step towards more robust models for surgical computer vision. In this paper, we describe the data collection and annotation protocol, baseline evaluations of established segmentation models, and data augmentation-based techniques to enhance model robustness.