 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Recognition Using Volumetric Motion Representations
Paper and Code


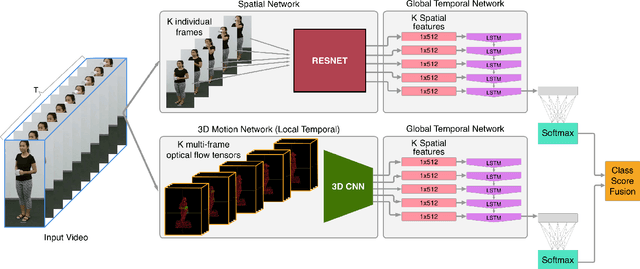
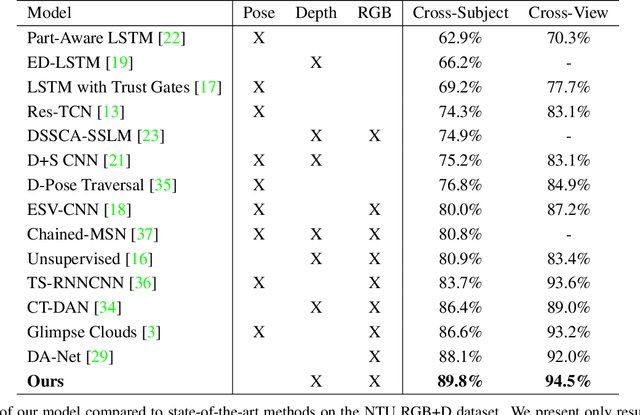
Traditional action recognition models are constructed around the paradigm of 2D perspective imagery. Though sophisticated time-series models have pushed the field forward, much of the information is still not exploited by confining the domain to 2D. In this work, we introduce a novel representation of motion as a voxelized 3D vector field and demonstrate how it can be used to improve performance of action recognition networks. This volumetric representation is a natural fit for 3D CNNs, and allows out-of-plane data augmentation techniques during training of these networks. Both the construction of this representation from RGB-D video and inference can be run in real time. We demonstrate superior results using this representation with our network design on the open-source NTU RGB+D dataset where it outperforms state-of-the-art on both of the defined evaluation metrics. Furthermore, we experimentally show how the out-of-plane augmentation techniques create viewpoint invariance and allow the model trained using this representation to generalize to unseen camera angles. Code is available here: https://github.com/mpeven/ntu_rgb.