 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Inverse Kinematics
May 22, 2022

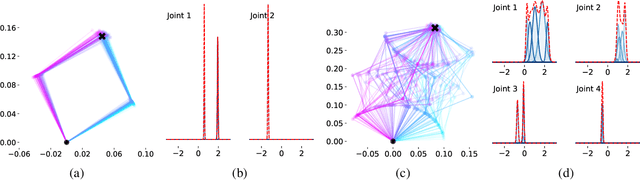

Inverse kinematic (IK) methods recover the parameters of the joints, given the desired position of selected elements in the kinematic chain. While the problem is well-defined and low-dimensional, it has to be solved rapidly, accounting for multiple possible solutions. In this work, we propose a neural IK method that employs the hierarchical structure of the problem to sequentially sample valid joint angles conditioned on the desired position and on the preceding joints along the chain. In our solution, a hypernetwork $f$ recovers the parameters of multiple primary networks {$g_1,g_2,\dots,g_N$, where $N$ is the number of joints}, such that each $g_i$ outputs a distribution of possible joint angles, and is conditioned on the sampled values obtained from the previous primary networks $g_j, j<i$. The hypernetwork can be trained on readily available pairs of matching joint angles and positions, without observing multiple solutions. At test time, a high-variance joint distribution is presented, by sampling sequentially from the primary networks. We demonstrate the advantage of the proposed method both in comparison to other IK methods for isolated instances of IK and with regard to following the path of the end effector in Cartesian space.
Unsupervised Disentanglement with Tensor Product Representations on the Torus
Feb 13, 2022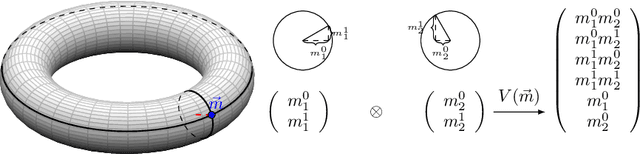
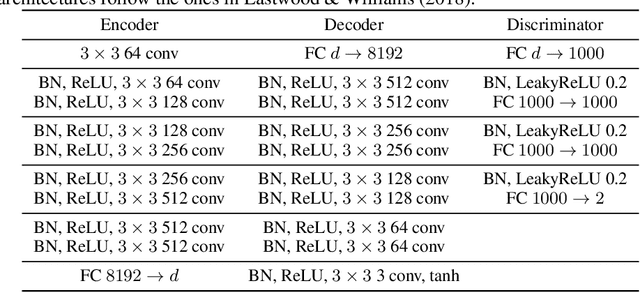
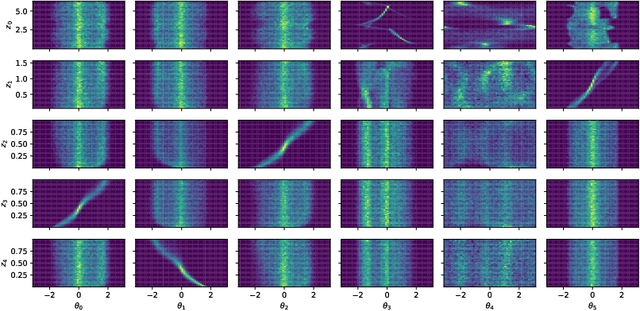
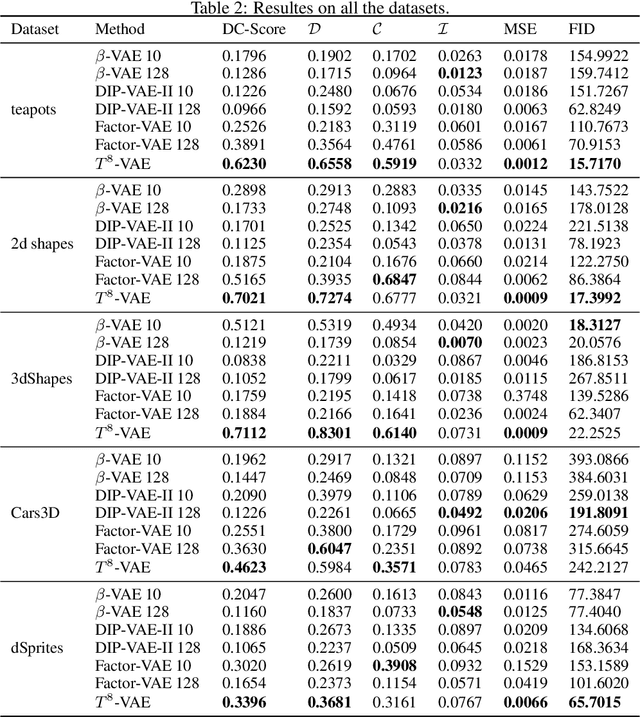
The current methods for learning representations with auto-encoders almost exclusively employ vectors as the latent representations. In this work, we propose to employ a tensor product structure for this purpose. This way, the obtained representations are naturally disentangled. In contrast to the conventional variations methods, which are targeted toward normally distributed features, the latent space in our representation is distributed uniformly over a set of unit circles. We argue that the torus structure of the latent space captures the generative factors effectively. We employ recent tools for measuring unsupervised disentanglement, and in an extensive set of experiments demonstrate the advantage of our method in terms of disentanglement, completeness, and informativeness. The code for our proposed method is available at https://github.com/rotmanmi/Unsupervised-Disentanglement-Torus.
Meta Internal Learning
Oct 06, 2021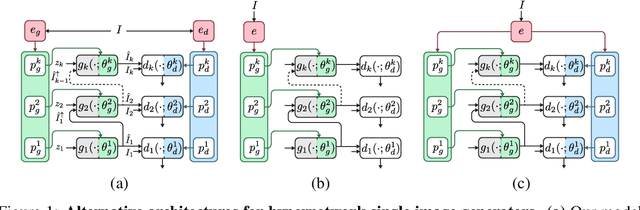
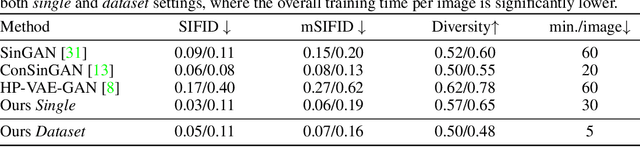


Internal learning for single-image generation is a framework, where a generator is trained to produce novel images based on a single image. Since these models are trained on a single image, they are limited in their scale and application. To overcome these issues, we propose a meta-learning approach that enables training over a collection of images, in order to model the internal statistics of the sample image more effectively. In the presented meta-learning approach, a single-image GAN model is generated given an input image, via a convolutional feedforward hypernetwork $f$. This network is trained over a dataset of images, allowing for feature sharing among different models, and for interpolation in the space of generative models. The generated single-image model contains a hierarchy of multiple generators and discriminators. It is therefore required to train the meta-learner in an adversarial manner, which requires careful design choices that we justify by a theoretical analysis. Our results show that the models obtained are as suitable as single-image GANs for many common image applications, significantly reduce the training time per image without loss in performance, and introduce novel capabilities, such as interpolation and feedforward modeling of novel images.
Cross-Modal Retrieval Augmentation for Multi-Modal Classification
Apr 16, 2021
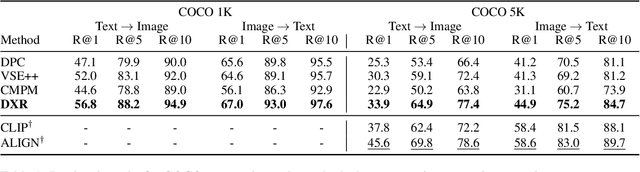

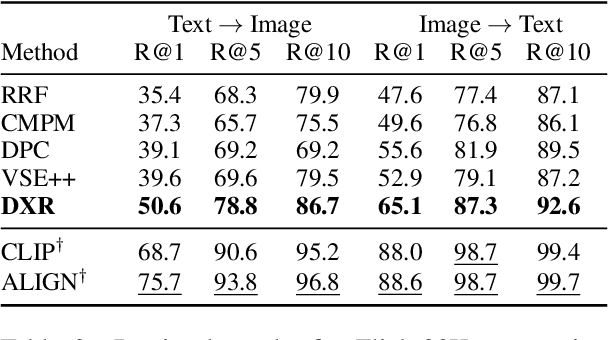
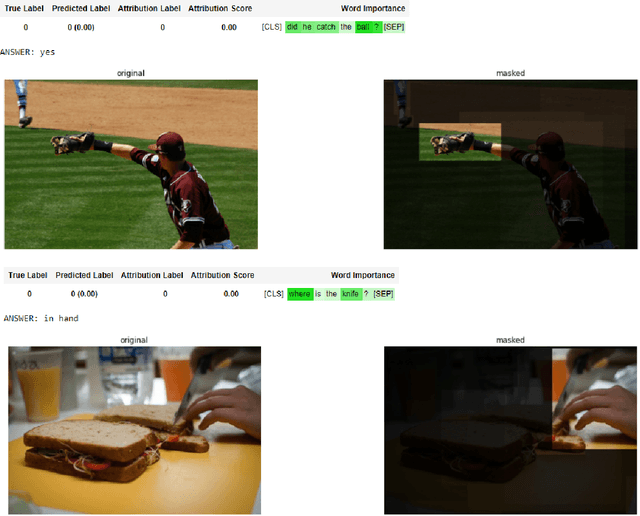
Recent advances in using retrieval components over external knowledge sources have shown impressive results for a variety of downstream tasks in natural language processing. Here, we explore the use of unstructured external knowledge sources of images and their corresponding captions for improving visual question answering (VQA). First, we train a novel alignment model for embedding images and captions in the same space, which achieves substantial improvement in performance on image-caption retrieval w.r.t. similar methods. Second, we show that retrieval-augmented multi-modal transformers using the trained alignment model improve results on VQA over strong baselines. We further conduct extensive experiments to establish the promise of this approach, and examine novel applications for inference time such as hot-swapping indices.
Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers
Mar 29, 2021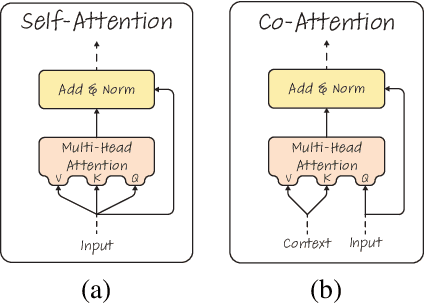


Transformers are increasingly dominating multi-modal reasoning tasks, such as visual question answering, achieving state-of-the-art results thanks to their ability to contextualize information using the self-attention and co-attention mechanisms. These attention modules also play a role in other computer vision tasks including object detection and image segmentation. Unlike Transformers that only use self-attention, Transformers with co-attention require to consider multiple attention maps in parallel in order to highlight the information that is relevant to the prediction in the model's input. In this work, we propose the first method to explain prediction by any Transformer-based architecture, including bi-modal Transformers and Transformers with co-attentions. We provide generic solutions and apply these to the three most commonly used of these architectures: (i) pure self-attention, (ii) self-attention combined with co-attention, and (iii) encoder-decoder attention. We show that our method is superior to all existing methods which are adapted from single modality explainability.
Transformer Interpretability Beyond Attention Visualization
Dec 17, 2020


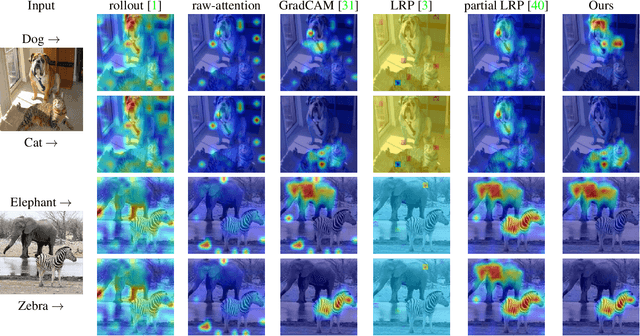
Self-attention techniques, and specifically Transformers, are dominating the field of text processing and are becoming increasingly popular in computer vision classification tasks. In order to visualize the parts of the image that led to a certain classification, existing methods either rely on the obtained attention maps, or employ heuristic propagation along the attention graph. In this work, we propose a novel way to compute relevancy for Transformer networks. The method assigns local relevance based on the deep Taylor decomposition principle and then propagates these relevancy scores through the layers. This propagation involves attention layers and skip connections, which challenge existing methods. Our solution is based on a specific formulation that is shown to maintain the total relevancy across layers. We benchmark our method on very recent visual Transformer networks, as well as on a text classification problem, and demonstrate a clear advantage over the existing explainability methods.
Visualization of Supervised and Self-Supervised Neural Networks via Attribution Guided Factorization
Dec 03, 2020

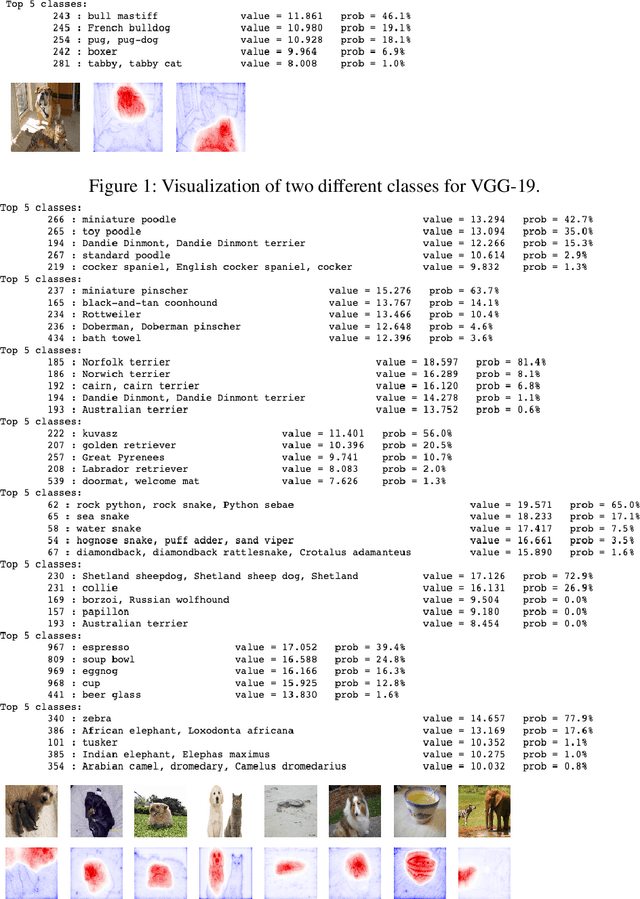

Neural network visualization techniques mark image locations by their relevancy to the network's classification. Existing methods are effective in highlighting the regions that affect the resulting classification the most. However, as we show, these methods are limited in their ability to identify the support for alternative classifications, an effect we name {\em the saliency bias} hypothesis. In this work, we integrate two lines of research: gradient-based methods and attribution-based methods, and develop an algorithm that provides per-class explainability. The algorithm back-projects the per pixel local influence, in a manner that is guided by the local attributions, while correcting for salient features that would otherwise bias the explanation. In an extensive battery of experiments, we demonstrate the ability of our methods to class-specific visualization, and not just the predicted label. Remarkably, the method obtains state of the art results in benchmarks that are commonly applied to gradient-based methods as well as in those that are employed mostly for evaluating attribution methods. Using a new unsupervised procedure, our method is also successful in demonstrating that self-supervised methods learn semantic information.
Hierarchical Patch VAE-GAN: Generating Diverse Videos from a Single Sample
Jun 23, 2020

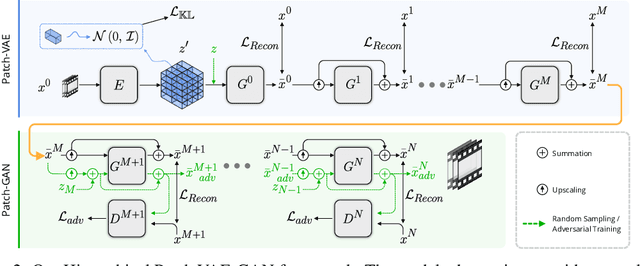

We consider the task of generating diverse and novel videos from a single video sample. Recently, new hierarchical patch-GAN based approaches were proposed for generating diverse images, given only a single sample at training time. Moving to videos, these approaches fail to generate diverse samples, and often collapse into generating samples similar to the training video. We introduce a novel patch-based variational autoencoder (VAE) which allows for a much greater diversity in generation. Using this tool, a new hierarchical video generation scheme is constructed: at coarse scales, our patch-VAE is employed, ensuring samples are of high diversity. Subsequently, at finer scales, a patch-GAN renders the fine details, resulting in high quality videos. Our experiments show that the proposed method produces diverse samples in both the image domain, and the more challenging video domain.
Microvascular Dynamics from 4D Microscopy Using Temporal Segmentation
Jan 14, 2020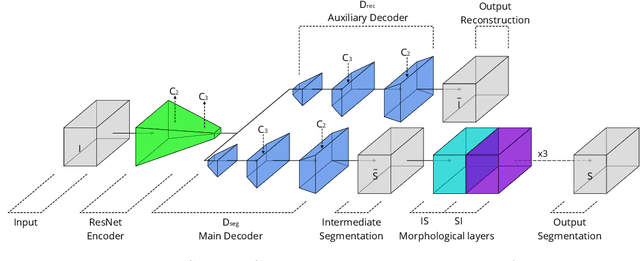



Recently developed methods for rapid continuous volumetric two-photon microscopy facilitate the observation of neuronal activity in hundreds of individual neurons and changes in blood flow in adjacent blood vessels across a large volume of living brain at unprecedented spatio-temporal resolution. However, the high imaging rate necessitates fully automated image analysis, whereas tissue turbidity and photo-toxicity limitations lead to extremely sparse and noisy imagery. In this work, we extend a recently proposed deep learning volumetric blood vessel segmentation network, such that it supports temporal analysis. With this technology, we are able to track changes in cerebral blood volume over time and identify spontaneous arterial dilations that propagate towards the pial surface. This new capability is a promising step towards characterizing the hemodynamic response function upon which functional magnetic resonance imaging (fMRI) is based.
Single Image Depth Estimation Trained via Depth from Defocus Cues
Jan 14, 2020



Estimating depth from a single RGB images is a fundamental task in computer vision, which is most directly solved using supervised deep learning. In the field of unsupervised learning of depth from a single RGB image, depth is not given explicitly. Existing work in the field receives either a stereo pair, a monocular video, or multiple views, and, using losses that are based on structure-from-motion, trains a depth estimation network. In this work, we rely, instead of different views, on depth from focus cues. Learning is based on a novel Point Spread Function convolutional layer, which applies location specific kernels that arise from the Circle-Of-Confusion in each image location. We evaluate our method on data derived from five common datasets for depth estimation and lightfield images, and present results that are on par with supervised methods on KITTI and Make3D datasets and outperform unsupervised learning approaches. Since the phenomenon of depth from defocus is not dataset specific, we hypothesize that learning based on it would overfit less to the specific content in each dataset. Our experiments show that this is indeed the case, and an estimator learned on one dataset using our method provides better results on other datasets, than the directly supervised methods.