 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Regularized RNNs for Solving Non-Stationary Bandit Problems
Mar 28, 2023We consider a Multi-Armed Bandit problem in which the rewards are non-stationary and are dependent on past actions and potentially on past contexts. At the heart of our method, we employ a recurrent neural network, which models these sequences. In order to balance between exploration and exploitation, we present an energy minimization term that prevents the neural network from becoming too confident in support of a certain action. This term provably limits the gap between the maximal and minimal probabilities assigned by the network. In a diverse set of experiments, we demonstrate that our method is at least as effective as methods suggested to solve the sub-problem of Rotting Bandits, and can solve intuitive extensions of various benchmark problems. We share our implementation at https://github.com/rotmanmi/Energy-Regularized-RNN.
Gradient Adjusting Networks for Domain Inversion
Feb 22, 2023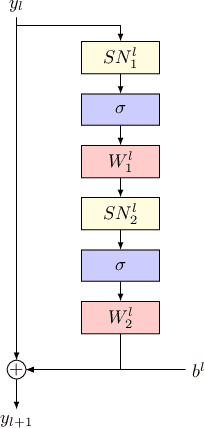
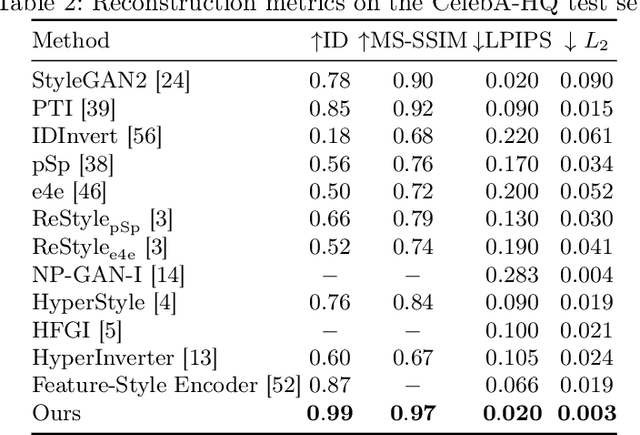

StyleGAN2 was demonstrated to be a powerful image generation engine that supports semantic editing. However, in order to manipulate a real-world image, one first needs to be able to retrieve its corresponding latent representation in StyleGAN's latent space that is decoded to an image as close as possible to the desired image. For many real-world images, a latent representation does not exist, which necessitates the tuning of the generator network. We present a per-image optimization method that tunes a StyleGAN2 generator such that it achieves a local edit to the generator's weights, resulting in almost perfect inversion, while still allowing image editing, by keeping the rest of the mapping between an input latent representation tensor and an output image relatively intact. The method is based on a one-shot training of a set of shallow update networks (aka. Gradient Modification Modules) that modify the layers of the generator. After training the Gradient Modification Modules, a modified generator is obtained by a single application of these networks to the original parameters, and the previous editing capabilities of the generator are maintained. Our experiments show a sizable gap in performance over the current state of the art in this very active domain. Our code is available at \url{https://github.com/sheffier/gani}.
Semi-supervised Learning of Partial Differential Operators and Dynamical Flows
Jul 28, 2022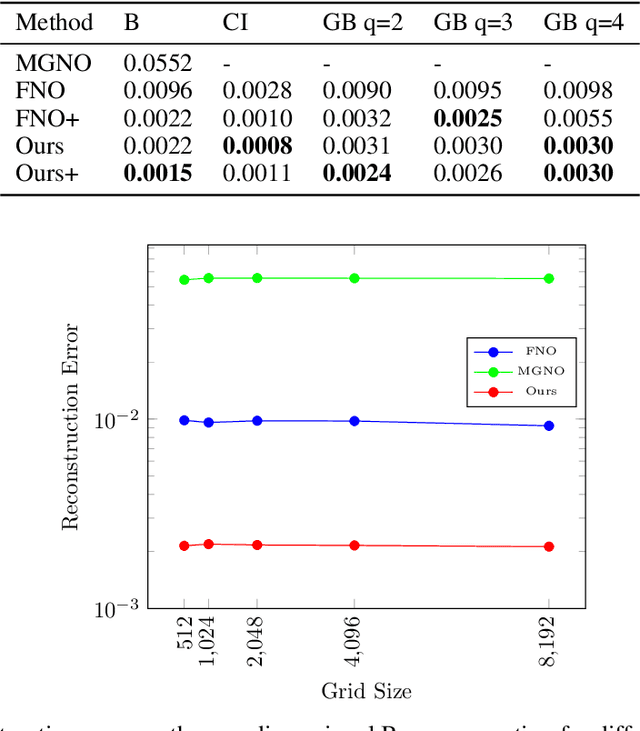
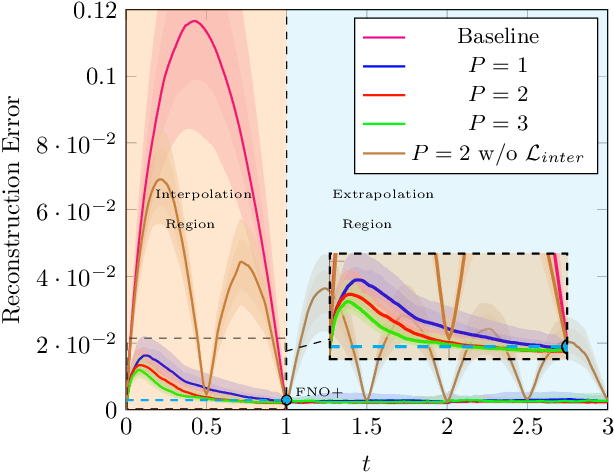

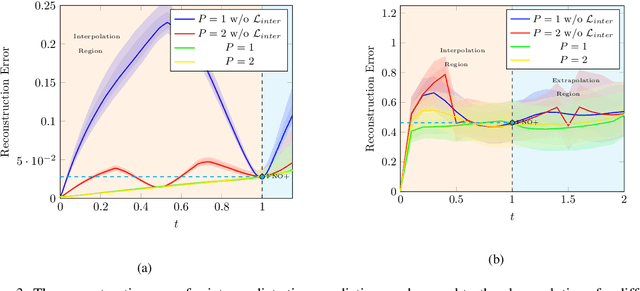
The evolution of dynamical systems is generically governed by nonlinear partial differential equations (PDEs), whose solution, in a simulation framework, requires vast amounts of computational resources. In this work, we present a novel method that combines a hyper-network solver with a Fourier Neural Operator architecture. Our method treats time and space separately. As a result, it successfully propagates initial conditions in continuous time steps by employing the general composition properties of the partial differential operators. Following previous work, supervision is provided at a specific time point. We test our method on various time evolution PDEs, including nonlinear fluid flows in one, two, and three spatial dimensions. The results show that the new method improves the learning accuracy at the time point of supervision point, and is able to interpolate and the solutions to any intermediate time.
Unsupervised Disentanglement with Tensor Product Representations on the Torus
Feb 13, 2022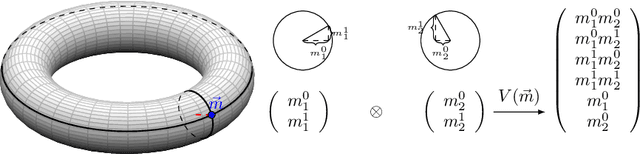
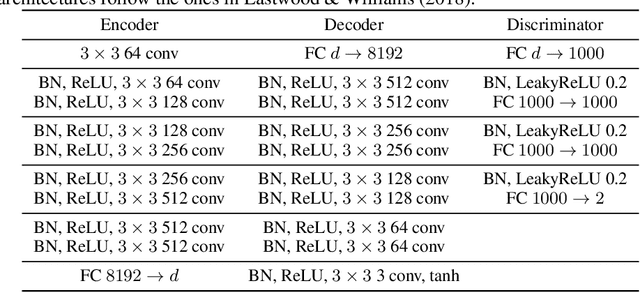
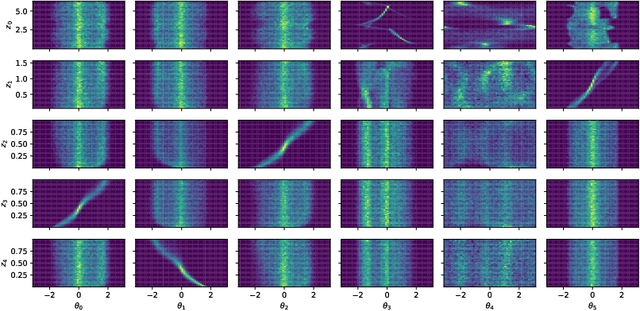
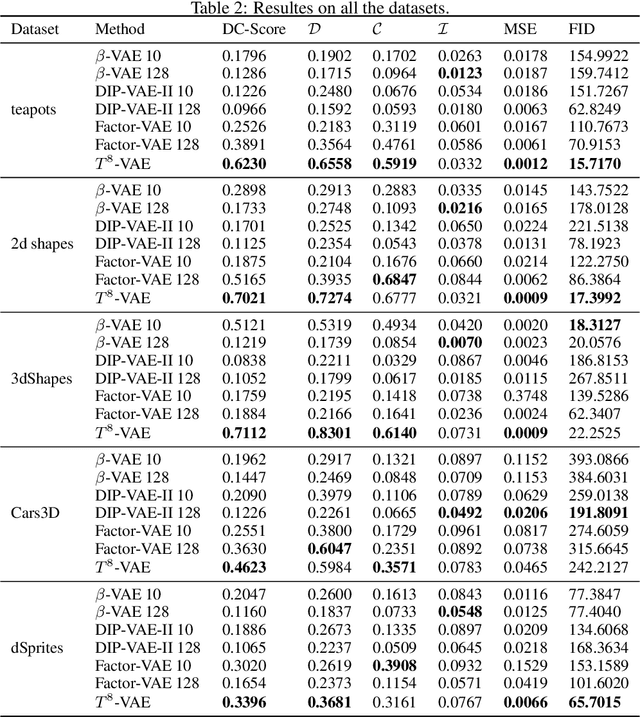
The current methods for learning representations with auto-encoders almost exclusively employ vectors as the latent representations. In this work, we propose to employ a tensor product structure for this purpose. This way, the obtained representations are naturally disentangled. In contrast to the conventional variations methods, which are targeted toward normally distributed features, the latent space in our representation is distributed uniformly over a set of unit circles. We argue that the torus structure of the latent space captures the generative factors effectively. We employ recent tools for measuring unsupervised disentanglement, and in an extensive set of experiments demonstrate the advantage of our method in terms of disentanglement, completeness, and informativeness. The code for our proposed method is available at https://github.com/rotmanmi/Unsupervised-Disentanglement-Torus.
Natural Statistics of Network Activations and Implications for Knowledge Distillation
Jun 01, 2021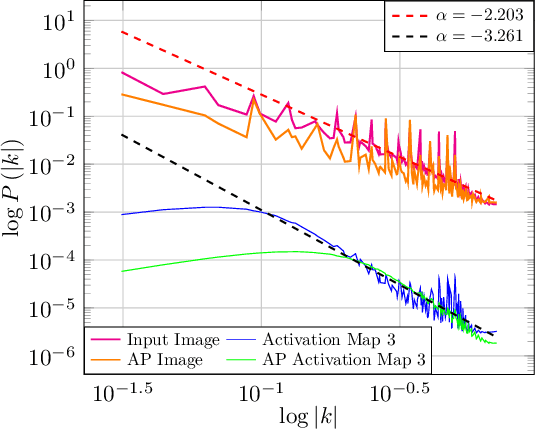
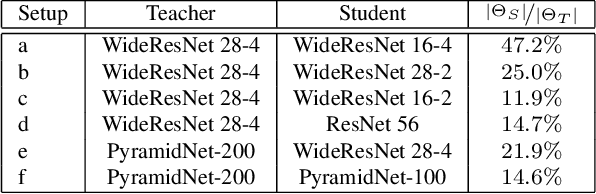
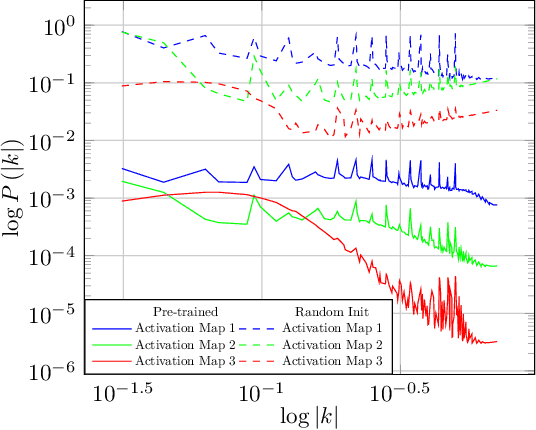

In a matter that is analog to the study of natural image statistics, we study the natural statistics of the deep neural network activations at various layers. As we show, these statistics, similar to image statistics, follow a power law. We also show, both analytically and empirically, that with depth the exponent of this power law increases at a linear rate. As a direct implication of our discoveries, we present a method for performing Knowledge Distillation (KD). While classical KD methods consider the logits of the teacher network, more recent methods obtain a leap in performance by considering the activation maps. This, however, uses metrics that are suitable for comparing images. We propose to employ two additional loss terms that are based on the spectral properties of the intermediate activation maps. The proposed method obtains state of the art results on multiple image recognition KD benchmarks.
Shuffling Recurrent Neural Networks
Jul 14, 2020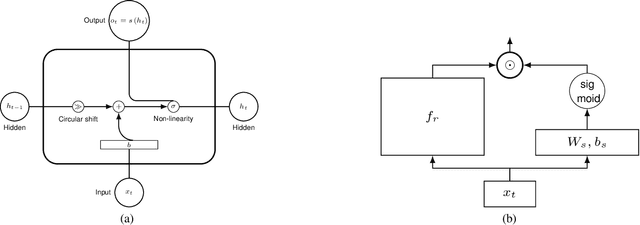

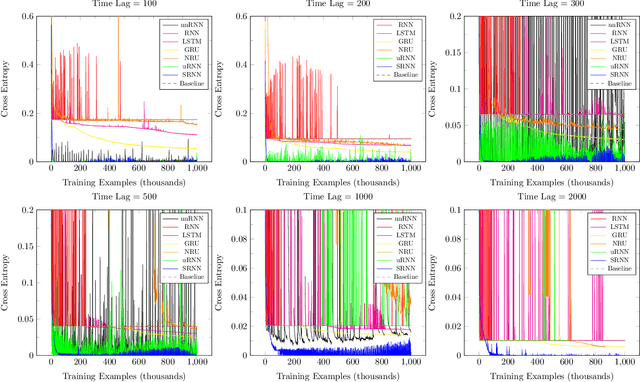
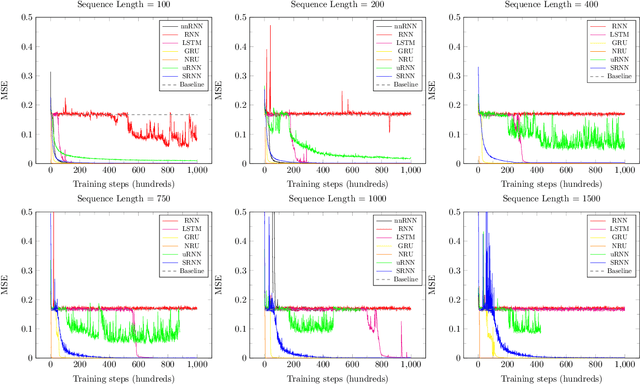
We propose a novel recurrent neural network model, where the hidden state $h_t$ is obtained by permuting the vector elements of the previous hidden state $h_{t-1}$ and adding the output of a learned function $b(x_t)$ of the input $x_t$ at time $t$. In our model, the prediction is given by a second learned function, which is applied to the hidden state $s(h_t)$. The method is easy to implement, extremely efficient, and does not suffer from vanishing nor exploding gradients. In an extensive set of experiments, the method shows competitive results, in comparison to the leading literature baselines.
A Novel Approach for Correcting Multiple Discrete Rigid In-Plane Motions Artefacts in MRI Scans
Jun 29, 2020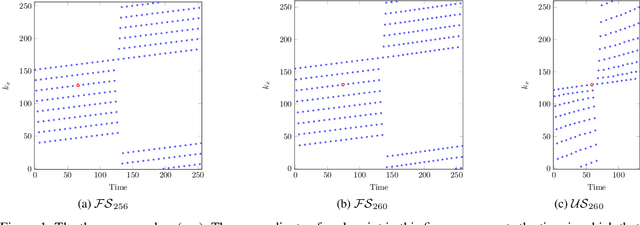


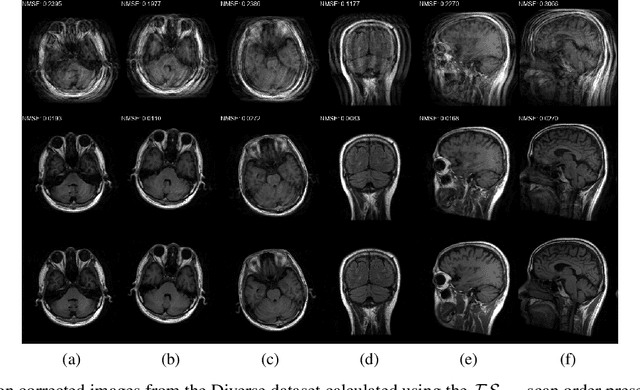
Motion artefacts created by patient motion during an MRI scan occur frequently in practice, often rendering the scans clinically unusable and requiring a re-scan. While many methods have been employed to ameliorate the effects of patient motion, these often fall short in practice. In this paper we propose a novel method for removing motion artefacts using a deep neural network with two input branches that discriminates between patient poses using the motion's timing. The first branch receives a subset of the $k$-space data collected during a single patient pose, and the second branch receives the remaining part of the collected $k$-space data. The proposed method can be applied to artefacts generated by multiple movements of the patient. Furthermore, it can be used to correct motion for the case where $k$-space has been under-sampled, to shorten the scan time, as is common when using methods such as parallel imaging or compressed sensing. Experimental results on both simulated and real MRI data show the efficacy of our approach.
Electric Analog Circuit Design with Hypernetworks and a Differential Simulator
Nov 08, 2019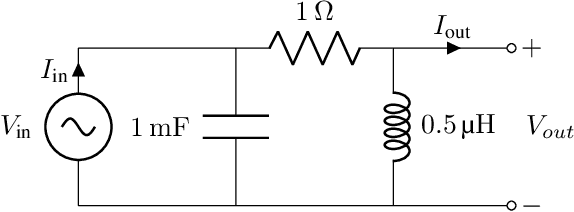
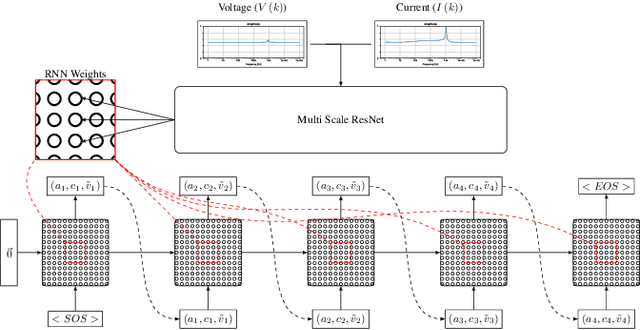
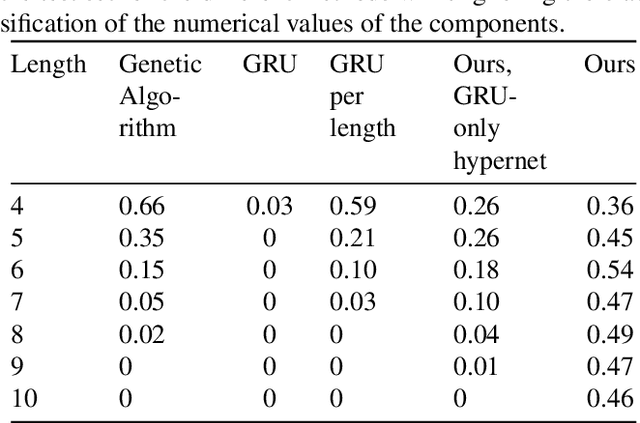
The manual design of analog circuits is a tedious task of parameter tuning that requires hours of work by human experts. In this work, we make a significant step towards a fully automatic design method that is based on deep learning. The method selects the components and their configuration, as well as their numerical parameters. By contrast, the current literature methods are limited to the parameter fitting part only. A two-stage network is used, which first generates a chain of circuit components and then predicts their parameters. A hypernetwork scheme is used in which a weight generating network, which is conditioned on the circuit's power spectrum, produces the parameters of a primal RNN network that places the components. A differential simulator is used for refining the numerical values of the components. We show that our model provides an efficient design solution, and is superior to alternative solutions.
Text Segmentation as a Supervised Learning Task
Mar 25, 2018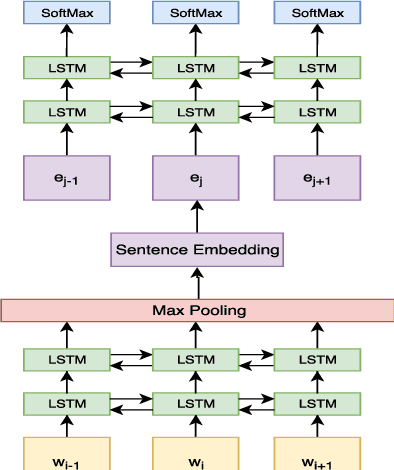
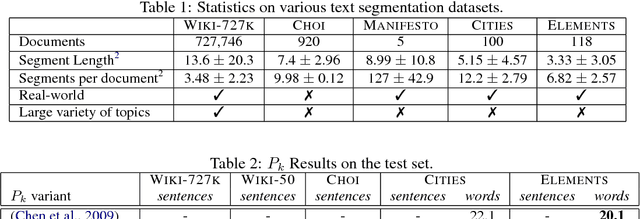
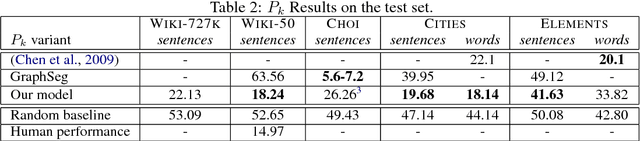
Text segmentation, the task of dividing a document into contiguous segments based on its semantic structure, is a longstanding challenge in language understanding. Previous work on text segmentation focused on unsupervised methods such as clustering or graph search, due to the paucity in labeled data. In this work, we formulate text segmentation as a supervised learning problem, and present a large new dataset for text segmentation that is automatically extracted and labeled from Wikipedia. Moreover, we develop a segmentation model based on this dataset and show that it generalizes well to unseen natural text.