 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-QA: A Real-World Medical Q&A Benchmark
Jan 25, 2024



Ensuring the accuracy of responses provided by large language models (LLMs) is crucial, particularly in clinical settings where incorrect information may directly impact patient health. To address this challenge, we construct K-QA, a dataset containing 1,212 patient questions originating from real-world conversations held on K Health (an AI-driven clinical platform). We employ a panel of in-house physicians to answer and manually decompose a subset of K-QA into self-contained statements. Additionally, we formulate two NLI-based evaluation metrics approximating recall and precision: (1) comprehensiveness, measuring the percentage of essential clinical information in the generated answer and (2) hallucination rate, measuring the number of statements from the physician-curated response contradicted by the LLM answer. Finally, we use K-QA along with these metrics to evaluate several state-of-the-art models, as well as the effect of in-context learning and medically-oriented augmented retrieval schemes developed by the authors. Our findings indicate that in-context learning improves the comprehensiveness of the models, and augmented retrieval is effective in reducing hallucinations. We make K-QA available to to the community to spur research into medically accurate NLP applications.
Semi-supervised Learning of Partial Differential Operators and Dynamical Flows
Jul 28, 2022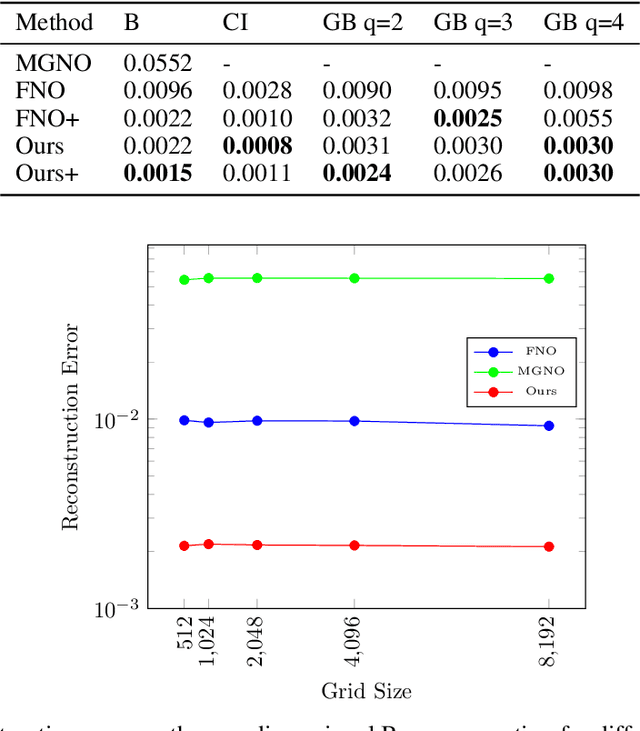
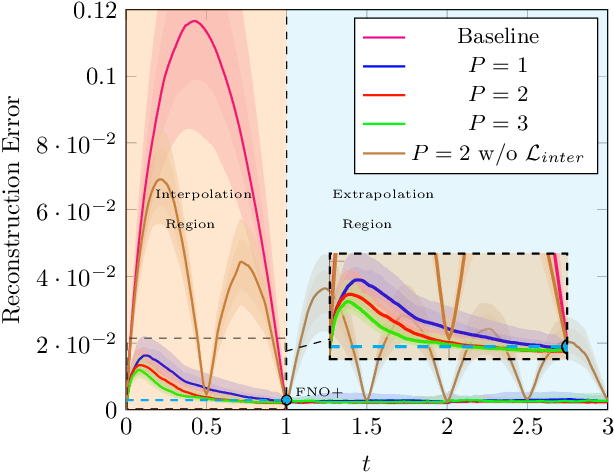

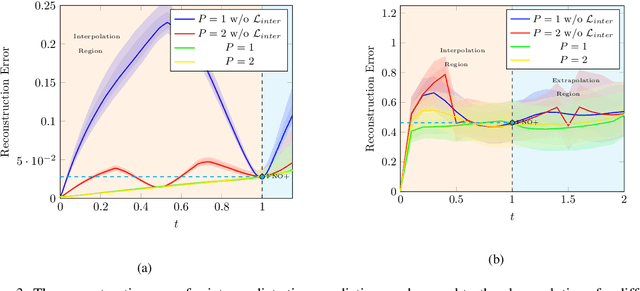
The evolution of dynamical systems is generically governed by nonlinear partial differential equations (PDEs), whose solution, in a simulation framework, requires vast amounts of computational resources. In this work, we present a novel method that combines a hyper-network solver with a Fourier Neural Operator architecture. Our method treats time and space separately. As a result, it successfully propagates initial conditions in continuous time steps by employing the general composition properties of the partial differential operators. Following previous work, supervision is provided at a specific time point. We test our method on various time evolution PDEs, including nonlinear fluid flows in one, two, and three spatial dimensions. The results show that the new method improves the learning accuracy at the time point of supervision point, and is able to interpolate and the solutions to any intermediate time.
Domain Adaptation in Highly Imbalanced and Overlapping Datasets
Jun 02, 2020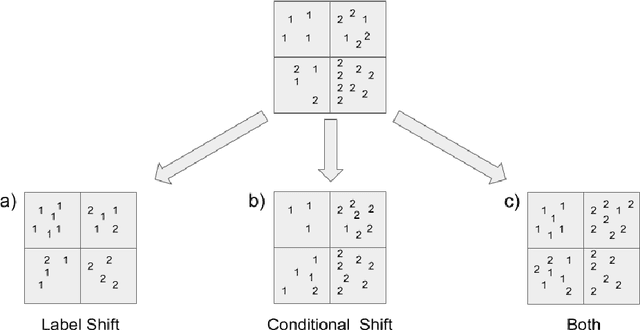

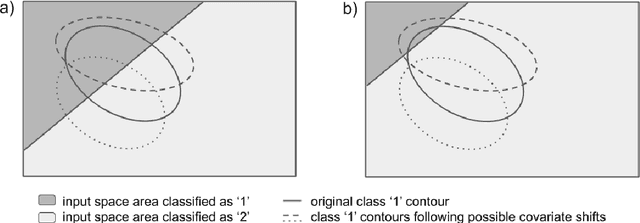
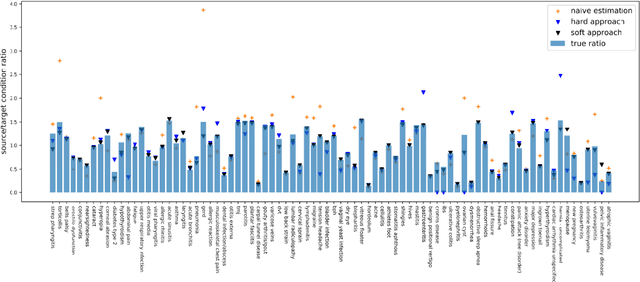
In many machine learning domains, datasets are characterized by highly imbalanced and overlapping classes. Particularly in the medical domain, a specific list of symptoms can be labeled as one of various different conditions. Some of these conditions may be more prevalent than others by several orders of magnitude. Here we present a novel unsupervised domain adaptation scheme for such datasets. The scheme, based on a specific type of Quantification, is designed to work under both label and conditional shifts. It is demonstrated on datasets generated from electronic health records and provides high quality results for both Quantification and Domain Adaptation in very challenging scenarios. Potential benefits of using this scheme in the current COVID-19 outbreak, for estimation of prevalence and probability of infection are discussed.