 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation in Highly Imbalanced and Overlapping Datasets
Paper and Code
Jun 02, 2020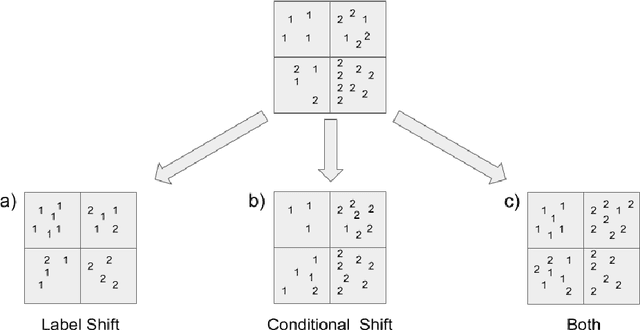

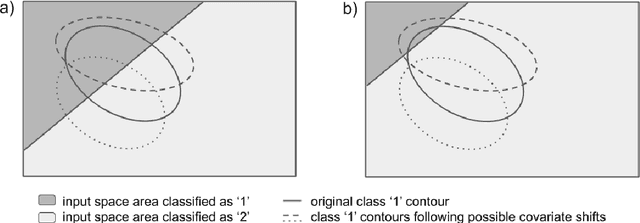
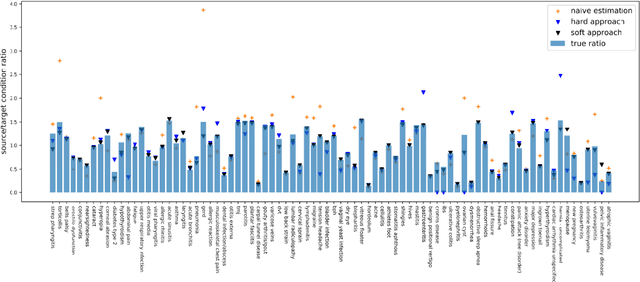
In many machine learning domains, datasets are characterized by highly imbalanced and overlapping classes. Particularly in the medical domain, a specific list of symptoms can be labeled as one of various different conditions. Some of these conditions may be more prevalent than others by several orders of magnitude. Here we present a novel unsupervised domain adaptation scheme for such datasets. The scheme, based on a specific type of Quantification, is designed to work under both label and conditional shifts. It is demonstrated on datasets generated from electronic health records and provides high quality results for both Quantification and Domain Adaptation in very challenging scenarios. Potential benefits of using this scheme in the current COVID-19 outbreak, for estimation of prevalence and probability of infection are discussed.