Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuffling Recurrent Neural Networks
Paper and Code
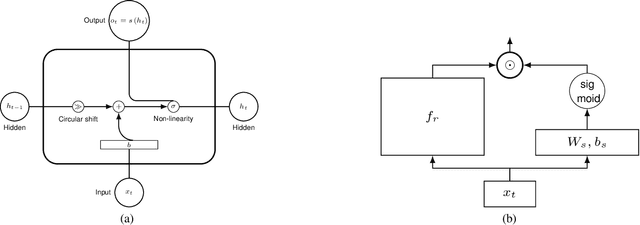

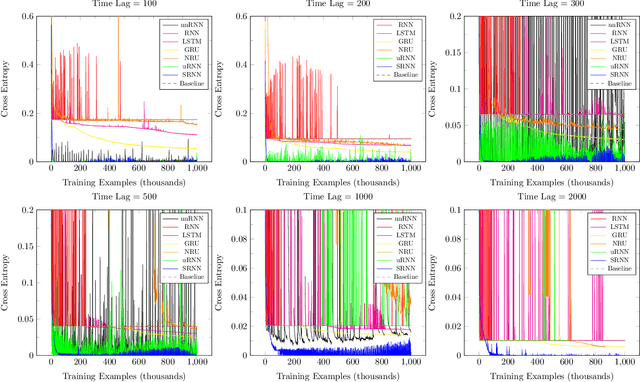
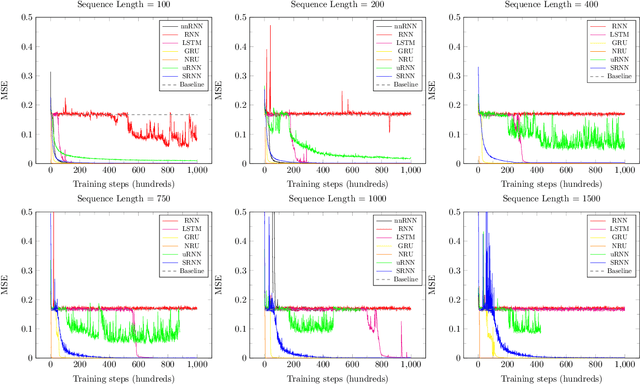
We propose a novel recurrent neural network model, where the hidden state $h_t$ is obtained by permuting the vector elements of the previous hidden state $h_{t-1}$ and adding the output of a learned function $b(x_t)$ of the input $x_t$ at time $t$. In our model, the prediction is given by a second learned function, which is applied to the hidden state $s(h_t)$. The method is easy to implement, extremely efficient, and does not suffer from vanishing nor exploding gradients. In an extensive set of experiments, the method shows competitive results, in comparison to the leading literature baselines.
View paper on