 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Prediction for Lexicon-Free OCR
May 28, 2018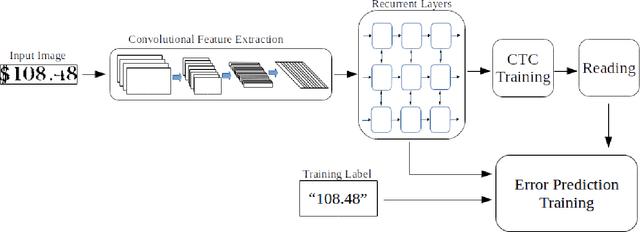
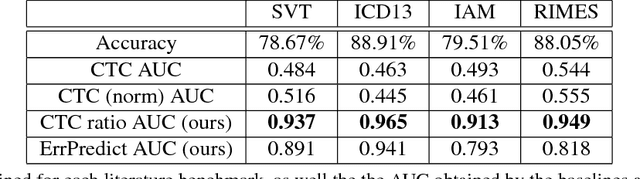

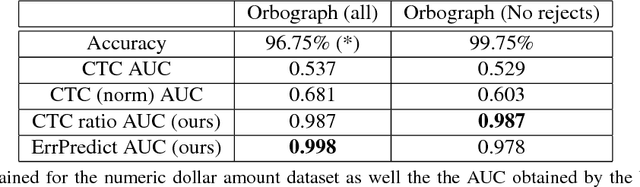
Having a reliable accuracy score is crucial for real world applications of OCR, since such systems are judged by the number of false readings. Lexicon-based OCR systems, which deal with what is essentially a multi-class classification problem, often employ methods explicitly taking into account the lexicon, in order to improve accuracy. However, in lexicon-free scenarios, filtering errors requires an explicit confidence calculation. In this work we show two explicit confidence measurement techniques, and show that they are able to achieve a significant reduction in misreads on both standard benchmarks and a proprietary dataset.
A Universal Music Translation Network
May 23, 2018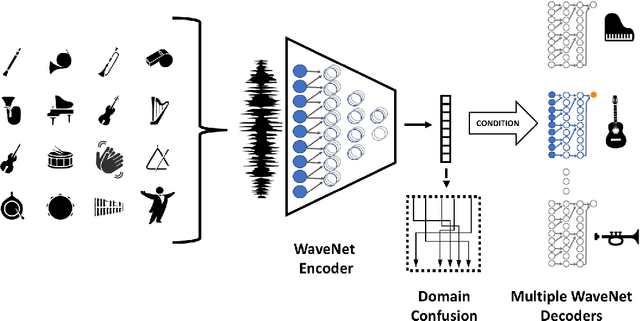
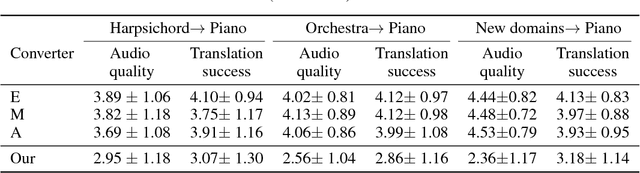
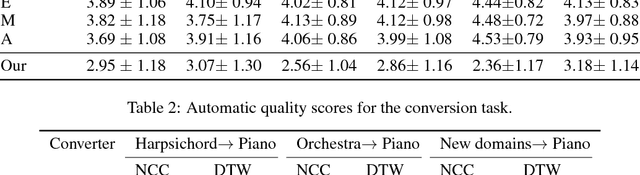
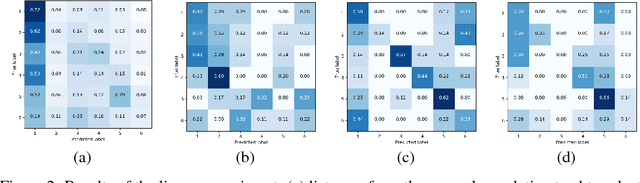
We present a method for translating music across musical instruments, genres, and styles. This method is based on a multi-domain wavenet autoencoder, with a shared encoder and a disentangled latent space that is trained end-to-end on waveforms. Employing a diverse training dataset and large net capacity, the domain-independent encoder allows us to translate even from musical domains that were not seen during training. The method is unsupervised and does not rely on supervision in the form of matched samples between domains or musical transcriptions. We evaluate our method on NSynth, as well as on a dataset collected from professional musicians, and achieve convincing translations, even when translating from whistling, potentially enabling the creation of instrumental music by untrained humans.
Text Segmentation as a Supervised Learning Task
Mar 25, 2018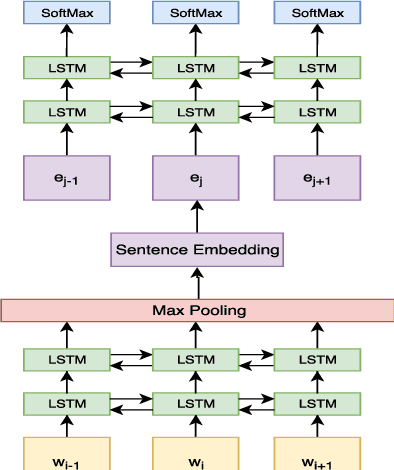
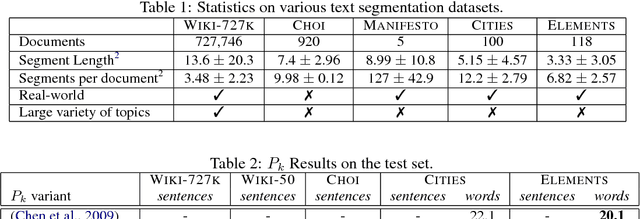
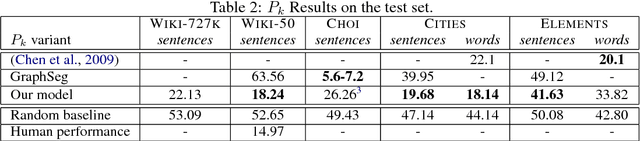
Text segmentation, the task of dividing a document into contiguous segments based on its semantic structure, is a longstanding challenge in language understanding. Previous work on text segmentation focused on unsupervised methods such as clustering or graph search, due to the paucity in labeled data. In this work, we formulate text segmentation as a supervised learning problem, and present a large new dataset for text segmentation that is automatically extracted and labeled from Wikipedia. Moreover, we develop a segmentation model based on this dataset and show that it generalizes well to unseen natural text.