Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Prediction for Lexicon-Free OCR
Paper and Code
May 28, 2018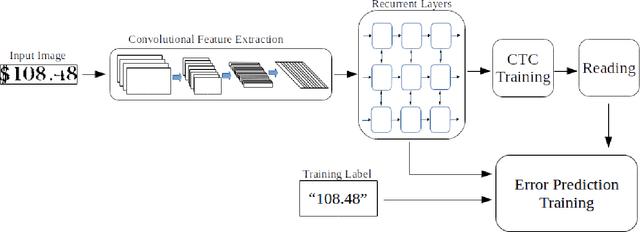
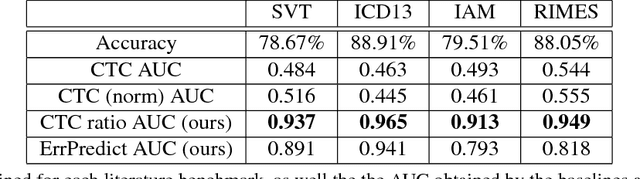

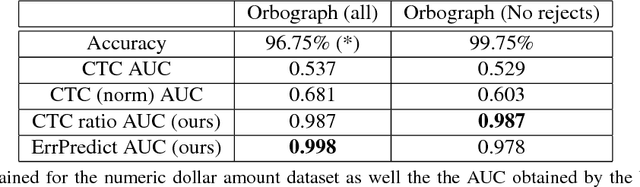
Having a reliable accuracy score is crucial for real world applications of OCR, since such systems are judged by the number of false readings. Lexicon-based OCR systems, which deal with what is essentially a multi-class classification problem, often employ methods explicitly taking into account the lexicon, in order to improve accuracy. However, in lexicon-free scenarios, filtering errors requires an explicit confidence calculation. In this work we show two explicit confidence measurement techniques, and show that they are able to achieve a significant reduction in misreads on both standard benchmarks and a proprietary dataset.
View paper on