 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Universal Music Translation Network
Paper and Code
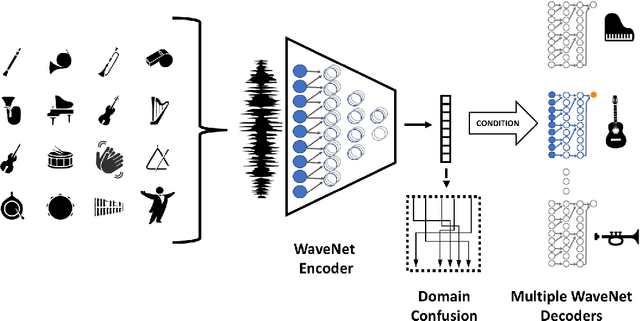
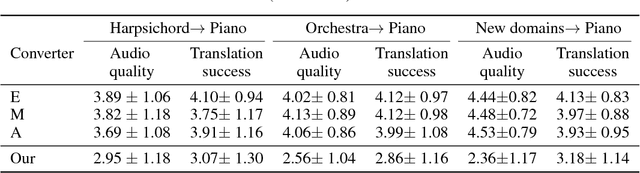
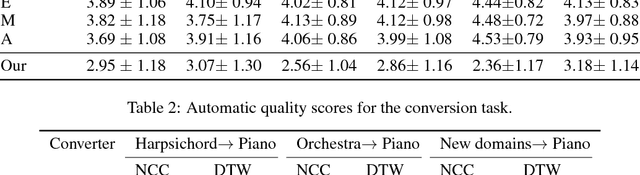
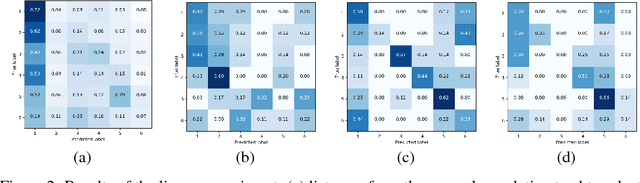
We present a method for translating music across musical instruments, genres, and styles. This method is based on a multi-domain wavenet autoencoder, with a shared encoder and a disentangled latent space that is trained end-to-end on waveforms. Employing a diverse training dataset and large net capacity, the domain-independent encoder allows us to translate even from musical domains that were not seen during training. The method is unsupervised and does not rely on supervision in the form of matched samples between domains or musical transcriptions. We evaluate our method on NSynth, as well as on a dataset collected from professional musicians, and achieve convincing translations, even when translating from whistling, potentially enabling the creation of instrumental music by untrained humans.