 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobalSplat: Efficient Feed-Forward 3D Gaussian Splatting via Global Scene Tokens
Apr 16, 2026The efficient spatial allocation of primitives serves as the foundation of 3D Gaussian Splatting, as it directly dictates the synergy between representation compactness, reconstruction speed, and rendering fidelity. Previous solutions, whether based on iterative optimization or feed-forward inference, suffer from significant trade-offs between these goals, mainly due to the reliance on local, heuristic-driven allocation strategies that lack global scene awareness. Specifically, current feed-forward methods are largely pixel-aligned or voxel-aligned. By unprojecting pixels into dense, view-aligned primitives, they bake redundancy into the 3D asset. As more input views are added, the representation size increases and global consistency becomes fragile. To this end, we introduce GlobalSplat, a framework built on the principle of align first, decode later. Our approach learns a compact, global, latent scene representation that encodes multi-view input and resolves cross-view correspondences before decoding any explicit 3D geometry. Crucially, this formulation enables compact, globally consistent reconstructions without relying on pretrained pixel-prediction backbones or reusing latent features from dense baselines. Utilizing a coarse-to-fine training curriculum that gradually increases decoded capacity, GlobalSplat natively prevents representation bloat. On RealEstate10K and ACID, our model achieves competitive novel-view synthesis performance while utilizing as few as 16K Gaussians, significantly less than required by dense pipelines, obtaining a light 4MB footprint. Further, GlobalSplat enables significantly faster inference than the baselines, operating under 78 milliseconds in a single forward pass. Project page is available at https://r-itk.github.io/globalsplat/
RAD: Retrieval-Augmented Monocular Metric Depth Estimation for Underrepresented Classes
Feb 10, 2026Monocular Metric Depth Estimation (MMDE) is essential for physically intelligent systems, yet accurate depth estimation for underrepresented classes in complex scenes remains a persistent challenge. To address this, we propose RAD, a retrieval-augmented framework that approximates the benefits of multi-view stereo by utilizing retrieved neighbors as structural geometric proxies. Our method first employs an uncertainty-aware retrieval mechanism to identify low-confidence regions in the input and retrieve RGB-D context samples containing semantically similar content. We then process both the input and retrieved context via a dual-stream network and fuse them using a matched cross-attention module, which transfers geometric information only at reliable point correspondences. Evaluations on NYU Depth v2, KITTI, and Cityscapes demonstrate that RAD significantly outperforms state-of-the-art baselines on underrepresented classes, reducing relative absolute error by 29.2% on NYU Depth v2, 13.3% on KITTI, and 7.2% on Cityscapes, while maintaining competitive performance on standard in-domain benchmarks.
SemanticMoments: Training-Free Motion Similarity via Third Moment Features
Feb 09, 2026Retrieving videos based on semantic motion is a fundamental, yet unsolved, problem. Existing video representation approaches overly rely on static appearance and scene context rather than motion dynamics, a bias inherited from their training data and objectives. Conversely, traditional motion-centric inputs like optical flow lack the semantic grounding needed to understand high-level motion. To demonstrate this inherent bias, we introduce the SimMotion benchmarks, combining controlled synthetic data with a new human-annotated real-world dataset. We show that existing models perform poorly on these benchmarks, often failing to disentangle motion from appearance. To address this gap, we propose SemanticMoments, a simple, training-free method that computes temporal statistics (specifically, higher-order moments) over features from pre-trained semantic models. Across our benchmarks, SemanticMoments consistently outperforms existing RGB, flow, and text-supervised methods. This demonstrates that temporal statistics in a semantic feature space provide a scalable and perceptually grounded foundation for motion-centric video understanding.
Splat and Distill: Augmenting Teachers with Feed-Forward 3D Reconstruction For 3D-Aware Distillation
Feb 05, 2026Vision Foundation Models (VFMs) have achieved remarkable success when applied to various downstream 2D tasks. Despite their effectiveness, they often exhibit a critical lack of 3D awareness. To this end, we introduce Splat and Distill, a framework that instills robust 3D awareness into 2D VFMs by augmenting the teacher model with a fast, feed-forward 3D reconstruction pipeline. Given 2D features produced by a teacher model, our method first lifts these features into an explicit 3D Gaussian representation, in a feedforward manner. These 3D features are then ``splatted" onto novel viewpoints, producing a set of novel 2D feature maps used to supervise the student model, ``distilling" geometrically grounded knowledge. By replacing slow per-scene optimization of prior work with our feed-forward lifting approach, our framework avoids feature-averaging artifacts, creating a dynamic learning process where the teacher's consistency improves alongside that of the student. We conduct a comprehensive evaluation on a suite of downstream tasks, including monocular depth estimation, surface normal estimation, multi-view correspondence, and semantic segmentation. Our method significantly outperforms prior works, not only achieving substantial gains in 3D awareness but also enhancing the underlying semantic richness of 2D features. Project page is available at https://davidshavin4.github.io/Splat-and-Distill/
* Accepted to ICLR 2026
Lang3D-XL: Language Embedded 3D Gaussians for Large-scale Scenes
Dec 08, 2025Embedding a language field in a 3D representation enables richer semantic understanding of spatial environments by linking geometry with descriptive meaning. This allows for a more intuitive human-computer interaction, enabling querying or editing scenes using natural language, and could potentially improve tasks like scene retrieval, navigation, and multimodal reasoning. While such capabilities could be transformative, in particular for large-scale scenes, we find that recent feature distillation approaches cannot effectively learn over massive Internet data due to challenges in semantic feature misalignment and inefficiency in memory and runtime. To this end, we propose a novel approach to address these challenges. First, we introduce extremely low-dimensional semantic bottleneck features as part of the underlying 3D Gaussian representation. These are processed by rendering and passing them through a multi-resolution, feature-based, hash encoder. This significantly improves efficiency both in runtime and GPU memory. Second, we introduce an Attenuated Downsampler module and propose several regularizations addressing the semantic misalignment of ground truth 2D features. We evaluate our method on the in-the-wild HolyScenes dataset and demonstrate that it surpasses existing approaches in both performance and efficiency.
DyPE: Dynamic Position Extrapolation for Ultra High Resolution Diffusion
Oct 23, 2025Diffusion Transformer models can generate images with remarkable fidelity and detail, yet training them at ultra-high resolutions remains extremely costly due to the self-attention mechanism's quadratic scaling with the number of image tokens. In this paper, we introduce Dynamic Position Extrapolation (DyPE), a novel, training-free method that enables pre-trained diffusion transformers to synthesize images at resolutions far beyond their training data, with no additional sampling cost. DyPE takes advantage of the spectral progression inherent to the diffusion process, where low-frequency structures converge early, while high-frequencies take more steps to resolve. Specifically, DyPE dynamically adjusts the model's positional encoding at each diffusion step, matching their frequency spectrum with the current stage of the generative process. This approach allows us to generate images at resolutions that exceed the training resolution dramatically, e.g., 16 million pixels using FLUX. On multiple benchmarks, DyPE consistently improves performance and achieves state-of-the-art fidelity in ultra-high-resolution image generation, with gains becoming even more pronounced at higher resolutions. Project page is available at https://noamissachar.github.io/DyPE/.
Let it Snow! Animating Static Gaussian Scenes With Dynamic Weather Effects
Apr 07, 2025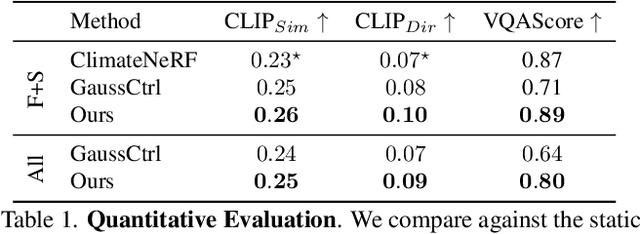
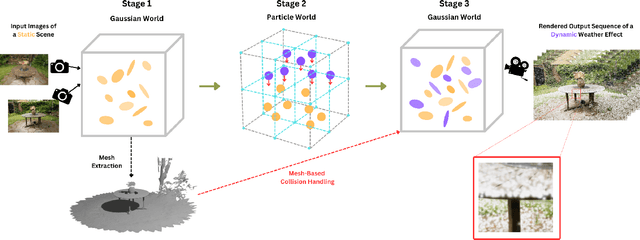


3D Gaussian Splatting has recently enabled fast and photorealistic reconstruction of static 3D scenes. However, introducing dynamic elements that interact naturally with such static scenes remains challenging. Accordingly, we present a novel hybrid framework that combines Gaussian-particle representations for incorporating physically-based global weather effects into static 3D Gaussian Splatting scenes, correctly handling the interactions of dynamic elements with the static scene. We follow a three-stage process: we first map static 3D Gaussians to a particle-based representation. We then introduce dynamic particles and simulate their motion using the Material Point Method (MPM). Finally, we map the simulated particles back to the Gaussian domain while introducing appearance parameters tailored for specific effects. To correctly handle the interactions of dynamic elements with the static scene, we introduce specialized collision handling techniques. Our approach supports a variety of weather effects, including snowfall, rainfall, fog, and sandstorms, and can also support falling objects, all with physically plausible motion and appearance. Experiments demonstrate that our method significantly outperforms existing approaches in both visual quality and physical realism.
RewardSDS: Aligning Score Distillation via Reward-Weighted Sampling
Mar 13, 2025Score Distillation Sampling (SDS) has emerged as an effective technique for leveraging 2D diffusion priors for tasks such as text-to-3D generation. While powerful, SDS struggles with achieving fine-grained alignment to user intent. To overcome this, we introduce RewardSDS, a novel approach that weights noise samples based on alignment scores from a reward model, producing a weighted SDS loss. This loss prioritizes gradients from noise samples that yield aligned high-reward output. Our approach is broadly applicable and can extend SDS-based methods. In particular, we demonstrate its applicability to Variational Score Distillation (VSD) by introducing RewardVSD. We evaluate RewardSDS and RewardVSD on text-to-image, 2D editing, and text-to-3D generation tasks, showing significant improvements over SDS and VSD on a diverse set of metrics measuring generation quality and alignment to desired reward models, enabling state-of-the-art performance. Project page is available at https://itaychachy.github.io/reward-sds/.
Structurally Disentangled Feature Fields Distillation for 3D Understanding and Editing
Feb 20, 2025
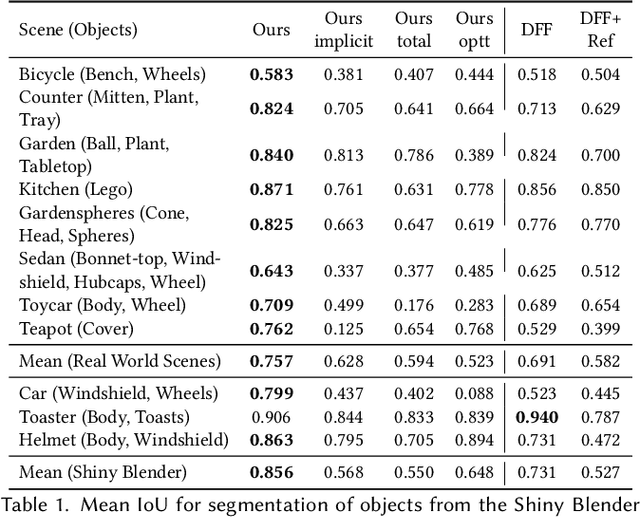
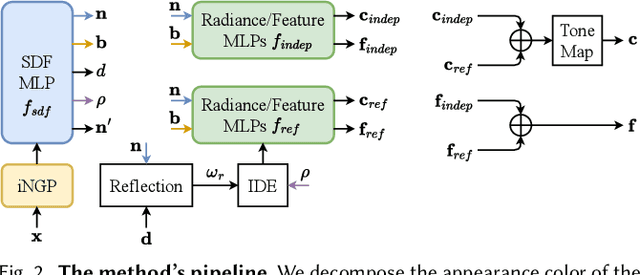
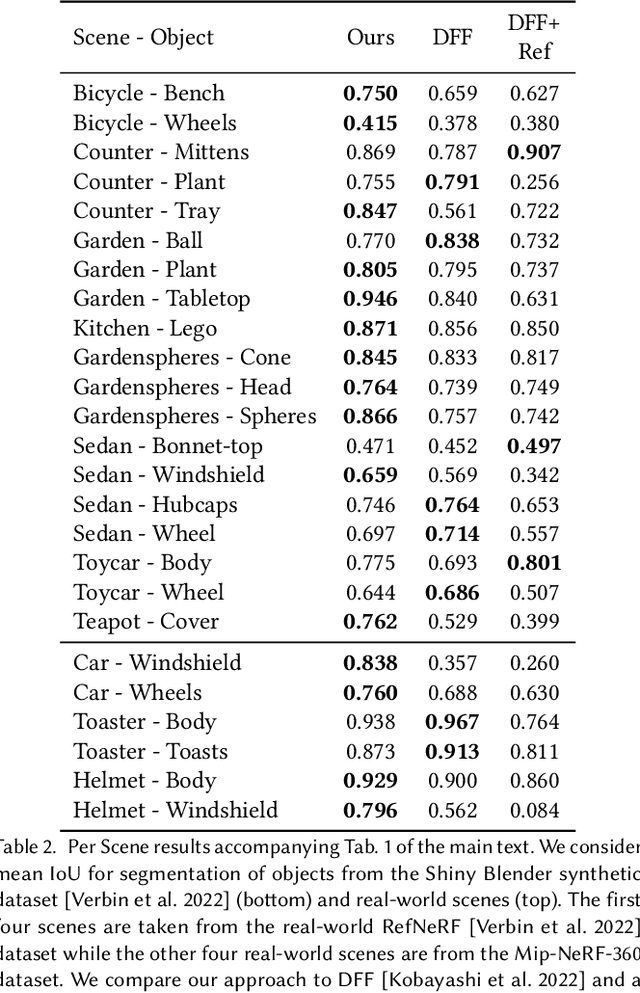
Recent work has demonstrated the ability to leverage or distill pre-trained 2D features obtained using large pre-trained 2D models into 3D features, enabling impressive 3D editing and understanding capabilities using only 2D supervision. Although impressive, models assume that 3D features are captured using a single feature field and often make a simplifying assumption that features are view-independent. In this work, we propose instead to capture 3D features using multiple disentangled feature fields that capture different structural components of 3D features involving view-dependent and view-independent components, which can be learned from 2D feature supervision only. Subsequently, each element can be controlled in isolation, enabling semantic and structural understanding and editing capabilities. For instance, using a user click, one can segment 3D features corresponding to a given object and then segment, edit, or remove their view-dependent (reflective) properties. We evaluate our approach on the task of 3D segmentation and demonstrate a set of novel understanding and editing tasks.
Designing a Conditional Prior Distribution for Flow-Based Generative Models
Feb 13, 2025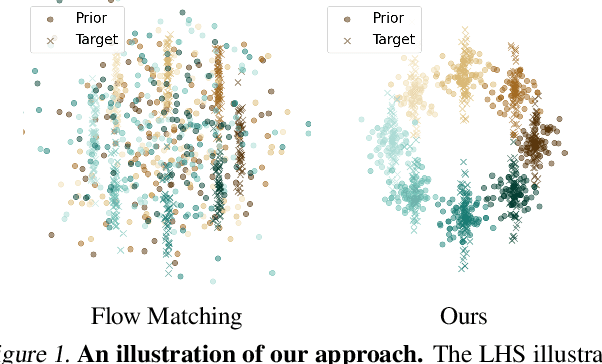

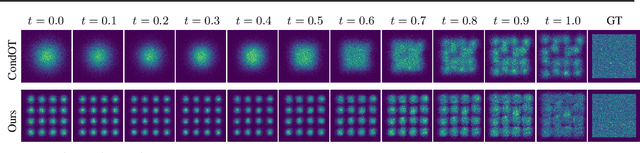
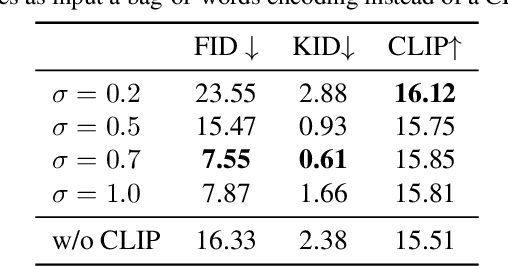
Flow-based generative models have recently shown impressive performance for conditional generation tasks, such as text-to-image generation. However, current methods transform a general unimodal noise distribution to a specific mode of the target data distribution. As such, every point in the initial source distribution can be mapped to every point in the target distribution, resulting in long average paths. To this end, in this work, we tap into a non-utilized property of conditional flow-based models: the ability to design a non-trivial prior distribution. Given an input condition, such as a text prompt, we first map it to a point lying in data space, representing an ``average" data point with the minimal average distance to all data points of the same conditional mode (e.g., class). We then utilize the flow matching formulation to map samples from a parametric distribution centered around this point to the conditional target distribution. Experimentally, our method significantly improves training times and generation efficiency (FID, KID and CLIP alignment scores) compared to baselines, producing high quality samples using fewer sampling steps.