 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplat and Distill: Augmenting Teachers with Feed-Forward 3D Reconstruction For 3D-Aware Distillation
Feb 05, 2026Vision Foundation Models (VFMs) have achieved remarkable success when applied to various downstream 2D tasks. Despite their effectiveness, they often exhibit a critical lack of 3D awareness. To this end, we introduce Splat and Distill, a framework that instills robust 3D awareness into 2D VFMs by augmenting the teacher model with a fast, feed-forward 3D reconstruction pipeline. Given 2D features produced by a teacher model, our method first lifts these features into an explicit 3D Gaussian representation, in a feedforward manner. These 3D features are then ``splatted" onto novel viewpoints, producing a set of novel 2D feature maps used to supervise the student model, ``distilling" geometrically grounded knowledge. By replacing slow per-scene optimization of prior work with our feed-forward lifting approach, our framework avoids feature-averaging artifacts, creating a dynamic learning process where the teacher's consistency improves alongside that of the student. We conduct a comprehensive evaluation on a suite of downstream tasks, including monocular depth estimation, surface normal estimation, multi-view correspondence, and semantic segmentation. Our method significantly outperforms prior works, not only achieving substantial gains in 3D awareness but also enhancing the underlying semantic richness of 2D features. Project page is available at https://davidshavin4.github.io/Splat-and-Distill/
* Accepted to ICLR 2026
Structurally Disentangled Feature Fields Distillation for 3D Understanding and Editing
Feb 20, 2025
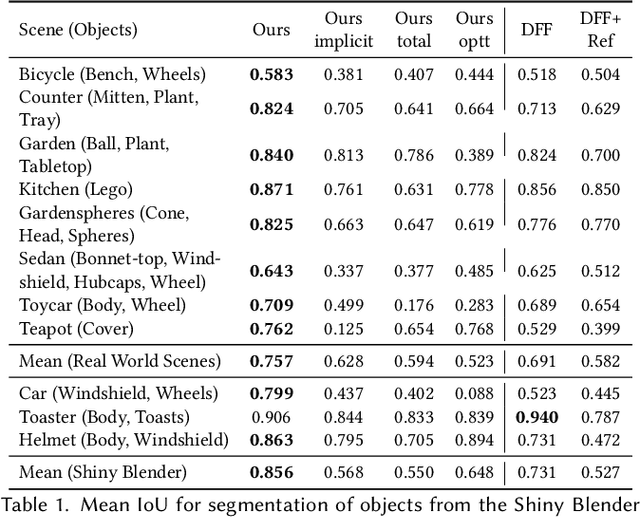
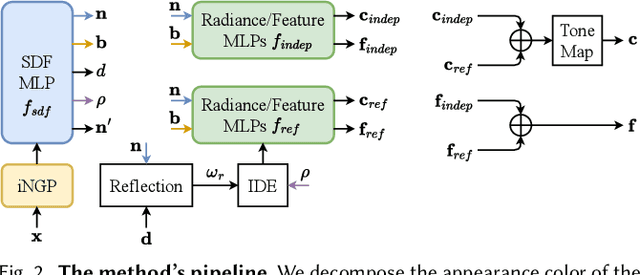
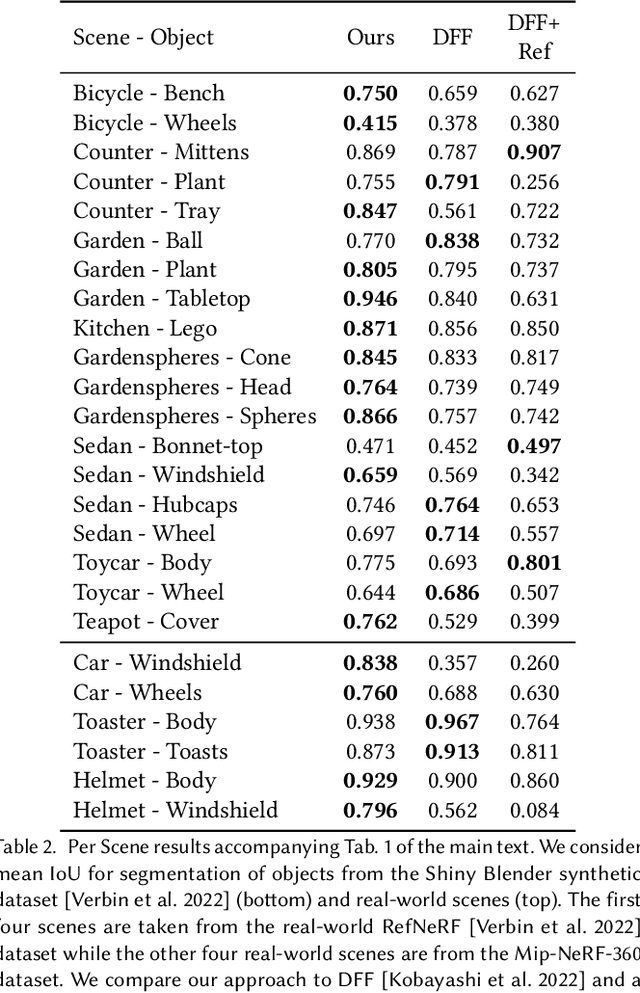
Recent work has demonstrated the ability to leverage or distill pre-trained 2D features obtained using large pre-trained 2D models into 3D features, enabling impressive 3D editing and understanding capabilities using only 2D supervision. Although impressive, models assume that 3D features are captured using a single feature field and often make a simplifying assumption that features are view-independent. In this work, we propose instead to capture 3D features using multiple disentangled feature fields that capture different structural components of 3D features involving view-dependent and view-independent components, which can be learned from 2D feature supervision only. Subsequently, each element can be controlled in isolation, enabling semantic and structural understanding and editing capabilities. For instance, using a user click, one can segment 3D features corresponding to a given object and then segment, edit, or remove their view-dependent (reflective) properties. We evaluate our approach on the task of 3D segmentation and demonstrate a set of novel understanding and editing tasks.