 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-To-Fine Tensor Trains for Compact Visual Representations
Jun 06, 2024



The ability to learn compact, high-quality, and easy-to-optimize representations for visual data is paramount to many applications such as novel view synthesis and 3D reconstruction. Recent work has shown substantial success in using tensor networks to design such compact and high-quality representations. However, the ability to optimize tensor-based representations, and in particular, the highly compact tensor train representation, is still lacking. This has prevented practitioners from deploying the full potential of tensor networks for visual data. To this end, we propose 'Prolongation Upsampling Tensor Train (PuTT)', a novel method for learning tensor train representations in a coarse-to-fine manner. Our method involves the prolonging or `upsampling' of a learned tensor train representation, creating a sequence of 'coarse-to-fine' tensor trains that are incrementally refined. We evaluate our representation along three axes: (1). compression, (2). denoising capability, and (3). image completion capability. To assess these axes, we consider the tasks of image fitting, 3D fitting, and novel view synthesis, where our method shows an improved performance compared to state-of-the-art tensor-based methods. For full results see our project webpage: https://sebulo.github.io/PuTT_website/
LoQT: Low Rank Adapters for Quantized Training
May 26, 2024



Training of large neural networks requires significant computational resources. Despite advances using low-rank adapters and quantization, pretraining of models such as LLMs on consumer hardware has not been possible without model sharding, offloading during training, or per-layer gradient updates. To address these limitations, we propose LoQT, a method for efficiently training quantized models. LoQT uses gradient-based tensor factorization to initialize low-rank trainable weight matrices that are periodically merged into quantized full-rank weight matrices. Our approach is suitable for both pretraining and fine-tuning of models, which we demonstrate experimentally for language modeling and downstream task adaptation. We find that LoQT enables efficient training of models up to 7B parameters on a consumer-grade 24GB GPU. We also demonstrate the feasibility of training a 13B parameter model using per-layer gradient updates on the same hardware.
Text-Driven Stylization of Video Objects
Jun 27, 2022
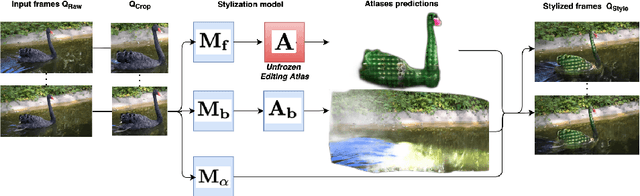
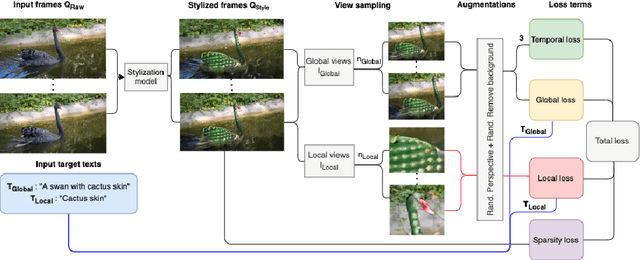

We tackle the task of stylizing video objects in an intuitive and semantic manner following a user-specified text prompt. This is a challenging task as the resulting video must satisfy multiple properties: (1) it has to be temporally consistent and avoid jittering or similar artifacts, (2) the resulting stylization must preserve both the global semantics of the object and its fine-grained details, and (3) it must adhere to the user-specified text prompt. To this end, our method stylizes an object in a video according to two target texts. The first target text prompt describes the global semantics and the second target text prompt describes the local semantics. To modify the style of an object, we harness the representational power of CLIP to get a similarity score between (1) the local target text and a set of local stylized views, and (2) a global target text and a set of stylized global views. We use a pretrained atlas decomposition network to propagate the edits in a temporally consistent manner. We demonstrate that our method can generate consistent style changes over time for a variety of objects and videos, that adhere to the specification of the target texts. We also show how varying the specificity of the target texts and augmenting the texts with a set of prefixes results in stylizations with different levels of detail. Full results are given on our project webpage: https://sloeschcke.github.io/Text-Driven-Stylization-of-Video-Objects/