 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Driven Stylization of Video Objects
Paper and Code

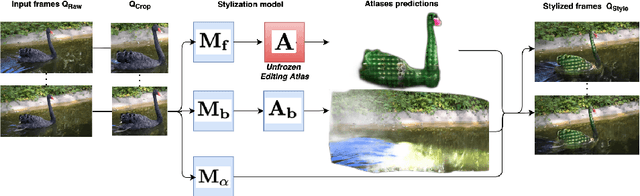
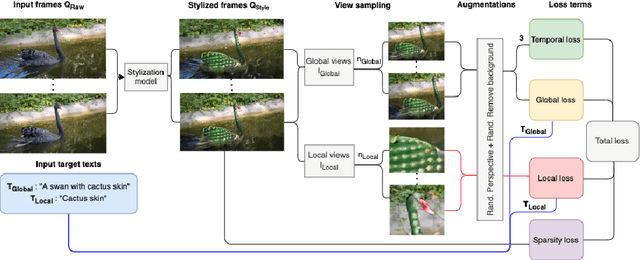

We tackle the task of stylizing video objects in an intuitive and semantic manner following a user-specified text prompt. This is a challenging task as the resulting video must satisfy multiple properties: (1) it has to be temporally consistent and avoid jittering or similar artifacts, (2) the resulting stylization must preserve both the global semantics of the object and its fine-grained details, and (3) it must adhere to the user-specified text prompt. To this end, our method stylizes an object in a video according to two target texts. The first target text prompt describes the global semantics and the second target text prompt describes the local semantics. To modify the style of an object, we harness the representational power of CLIP to get a similarity score between (1) the local target text and a set of local stylized views, and (2) a global target text and a set of stylized global views. We use a pretrained atlas decomposition network to propagate the edits in a temporally consistent manner. We demonstrate that our method can generate consistent style changes over time for a variety of objects and videos, that adhere to the specification of the target texts. We also show how varying the specificity of the target texts and augmenting the texts with a set of prefixes results in stylizations with different levels of detail. Full results are given on our project webpage: https://sloeschcke.github.io/Text-Driven-Stylization-of-Video-Objects/