 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyGenHOI: Physically-Aware 4D Generation of Dynamic Human-Object Interactions
May 28, 2026We address the task of generating physically accurate and visually faithful 4D Human-Object Interaction (HOI). Given a static 3D human and target object represented as 3D Gaussian Splats (3DGS), our goal is to synthesize dynamic scenes where the human actively engages with the object through actions, such as punching or kicking, in accordance with a given input text. To this end, we introduce PhyGenHOI, a novel framework that couples generative human motion with an explicit physical object simulation. We model the human as a semantic agent driven by a Motion Diffusion Model (MDM) and the object as a physical agent simulated via the Material Point Method (MPM), utilizing 3D Gaussians as a unified, differentiable representation. We supervise their interaction through three coupled mechanisms: (1) A Windowed Attraction Loss that temporally synchronizes generative motion to intercept the object; (2) A Contact-Driven Re-simulation step that triggers physically consistent momentum transfer upon impact; and (3) A Masked Video-SDS objective that injects video-based priors to enhance contact fidelity. Experiments show PhyGenHOI generates physically consistent 4D HOI across diverse actions, humans, and objects, outperforming baselines. Project page and videos: https://omerbenishu.github.io/PhyGenHOI/
Lang3D-XL: Language Embedded 3D Gaussians for Large-scale Scenes
Dec 08, 2025Embedding a language field in a 3D representation enables richer semantic understanding of spatial environments by linking geometry with descriptive meaning. This allows for a more intuitive human-computer interaction, enabling querying or editing scenes using natural language, and could potentially improve tasks like scene retrieval, navigation, and multimodal reasoning. While such capabilities could be transformative, in particular for large-scale scenes, we find that recent feature distillation approaches cannot effectively learn over massive Internet data due to challenges in semantic feature misalignment and inefficiency in memory and runtime. To this end, we propose a novel approach to address these challenges. First, we introduce extremely low-dimensional semantic bottleneck features as part of the underlying 3D Gaussian representation. These are processed by rendering and passing them through a multi-resolution, feature-based, hash encoder. This significantly improves efficiency both in runtime and GPU memory. Second, we introduce an Attenuated Downsampler module and propose several regularizations addressing the semantic misalignment of ground truth 2D features. We evaluate our method on the in-the-wild HolyScenes dataset and demonstrate that it surpasses existing approaches in both performance and efficiency.
Let it Snow! Animating Static Gaussian Scenes With Dynamic Weather Effects
Apr 07, 2025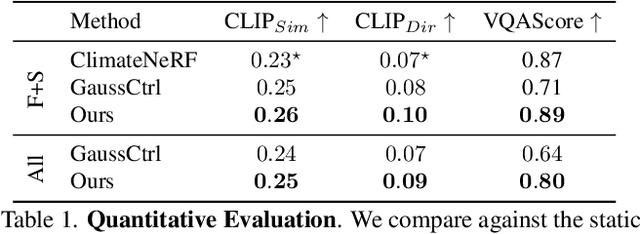
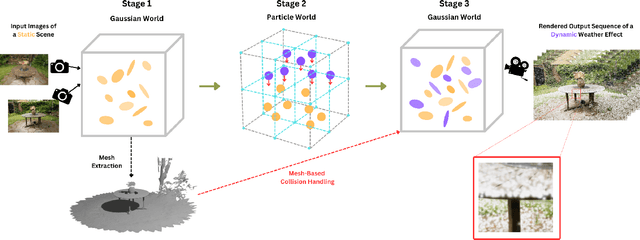


3D Gaussian Splatting has recently enabled fast and photorealistic reconstruction of static 3D scenes. However, introducing dynamic elements that interact naturally with such static scenes remains challenging. Accordingly, we present a novel hybrid framework that combines Gaussian-particle representations for incorporating physically-based global weather effects into static 3D Gaussian Splatting scenes, correctly handling the interactions of dynamic elements with the static scene. We follow a three-stage process: we first map static 3D Gaussians to a particle-based representation. We then introduce dynamic particles and simulate their motion using the Material Point Method (MPM). Finally, we map the simulated particles back to the Gaussian domain while introducing appearance parameters tailored for specific effects. To correctly handle the interactions of dynamic elements with the static scene, we introduce specialized collision handling techniques. Our approach supports a variety of weather effects, including snowfall, rainfall, fog, and sandstorms, and can also support falling objects, all with physically plausible motion and appearance. Experiments demonstrate that our method significantly outperforms existing approaches in both visual quality and physical realism.
4-LEGS: 4D Language Embedded Gaussian Splatting
Oct 15, 2024



The emergence of neural representations has revolutionized our means for digitally viewing a wide range of 3D scenes, enabling the synthesis of photorealistic images rendered from novel views. Recently, several techniques have been proposed for connecting these low-level representations with the high-level semantics understanding embodied within the scene. These methods elevate the rich semantic understanding from 2D imagery to 3D representations, distilling high-dimensional spatial features onto 3D space. In our work, we are interested in connecting language with a dynamic modeling of the world. We show how to lift spatio-temporal features to a 4D representation based on 3D Gaussian Splatting. This enables an interactive interface where the user can spatiotemporally localize events in the video from text prompts. We demonstrate our system on public 3D video datasets of people and animals performing various actions.
SPiC-E : Structural Priors in 3D Diffusion Models using Cross-Entity Attention
Nov 30, 2023



We are witnessing rapid progress in automatically generating and manipulating 3D assets due to the availability of pretrained text-image diffusion models. However, time-consuming optimization procedures are required for synthesizing each sample, hindering their potential for democratizing 3D content creation. Conversely, 3D diffusion models now train on million-scale 3D datasets, yielding high-quality text-conditional 3D samples within seconds. In this work, we present SPiC-E - a neural network that adds structural guidance to 3D diffusion models, extending their usage beyond text-conditional generation. At its core, our framework introduces a cross-entity attention mechanism that allows for multiple entities (in particular, paired input and guidance 3D shapes) to interact via their internal representations within the denoising network. We utilize this mechanism for learning task-specific structural priors in 3D diffusion models from auxiliary guidance shapes. We show that our approach supports a variety of applications, including 3D stylization, semantic shape editing and text-conditional abstraction-to-3D, which transforms primitive-based abstractions into highly-expressive shapes. Extensive experiments demonstrate that SPiC-E achieves SOTA performance over these tasks while often being considerably faster than alternative methods. Importantly, this is accomplished without tailoring our approach for any specific task.
Vox-E: Text-guided Voxel Editing of 3D Objects
Mar 21, 2023Large scale text-guided diffusion models have garnered significant attention due to their ability to synthesize diverse images that convey complex visual concepts. This generative power has more recently been leveraged to perform text-to-3D synthesis. In this work, we present a technique that harnesses the power of latent diffusion models for editing existing 3D objects. Our method takes oriented 2D images of a 3D object as input and learns a grid-based volumetric representation of it. To guide the volumetric representation to conform to a target text prompt, we follow unconditional text-to-3D methods and optimize a Score Distillation Sampling (SDS) loss. However, we observe that combining this diffusion-guided loss with an image-based regularization loss that encourages the representation not to deviate too strongly from the input object is challenging, as it requires achieving two conflicting goals while viewing only structure-and-appearance coupled 2D projections. Thus, we introduce a novel volumetric regularization loss that operates directly in 3D space, utilizing the explicit nature of our 3D representation to enforce correlation between the global structure of the original and edited object. Furthermore, we present a technique that optimizes cross-attention volumetric grids to refine the spatial extent of the edits. Extensive experiments and comparisons demonstrate the effectiveness of our approach in creating a myriad of edits which cannot be achieved by prior works.