 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes for a Good Stereoscopic Image?
Dec 30, 2024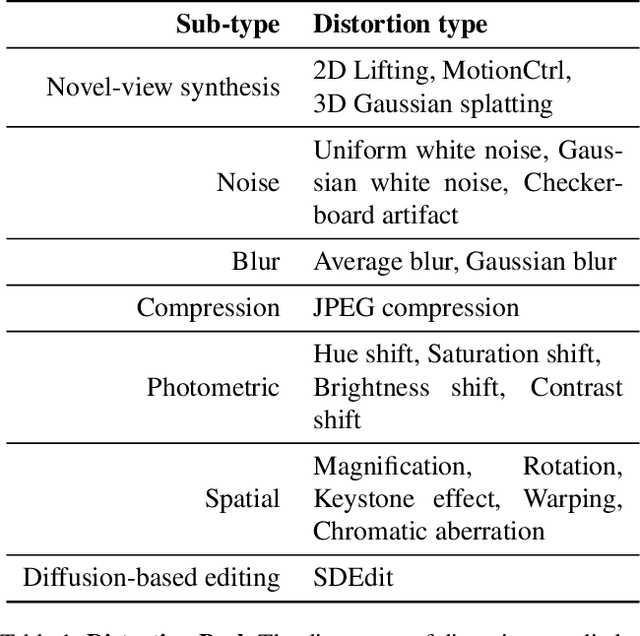

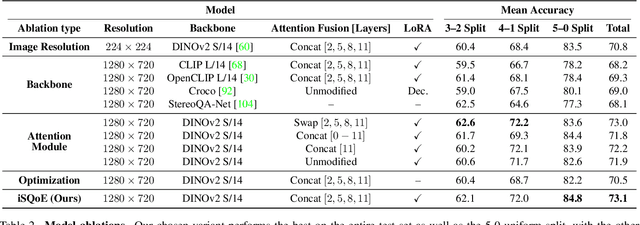
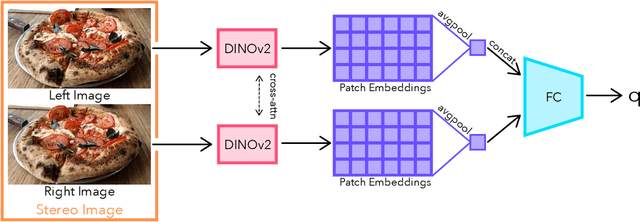
With rapid advancements in virtual reality (VR) headsets, effectively measuring stereoscopic quality of experience (SQoE) has become essential for delivering immersive and comfortable 3D experiences. However, most existing stereo metrics focus on isolated aspects of the viewing experience such as visual discomfort or image quality, and have traditionally faced data limitations. To address these gaps, we present SCOPE (Stereoscopic COntent Preference Evaluation), a new dataset comprised of real and synthetic stereoscopic images featuring a wide range of common perceptual distortions and artifacts. The dataset is labeled with preference annotations collected on a VR headset, with our findings indicating a notable degree of consistency in user preferences across different headsets. Additionally, we present iSQoE, a new model for stereo quality of experience assessment trained on our dataset. We show that iSQoE aligns better with human preferences than existing methods when comparing mono-to-stereo conversion methods.
SPiC-E : Structural Priors in 3D Diffusion Models using Cross-Entity Attention
Nov 30, 2023



We are witnessing rapid progress in automatically generating and manipulating 3D assets due to the availability of pretrained text-image diffusion models. However, time-consuming optimization procedures are required for synthesizing each sample, hindering their potential for democratizing 3D content creation. Conversely, 3D diffusion models now train on million-scale 3D datasets, yielding high-quality text-conditional 3D samples within seconds. In this work, we present SPiC-E - a neural network that adds structural guidance to 3D diffusion models, extending their usage beyond text-conditional generation. At its core, our framework introduces a cross-entity attention mechanism that allows for multiple entities (in particular, paired input and guidance 3D shapes) to interact via their internal representations within the denoising network. We utilize this mechanism for learning task-specific structural priors in 3D diffusion models from auxiliary guidance shapes. We show that our approach supports a variety of applications, including 3D stylization, semantic shape editing and text-conditional abstraction-to-3D, which transforms primitive-based abstractions into highly-expressive shapes. Extensive experiments demonstrate that SPiC-E achieves SOTA performance over these tasks while often being considerably faster than alternative methods. Importantly, this is accomplished without tailoring our approach for any specific task.