 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes for a Good Stereoscopic Image?
Dec 30, 2024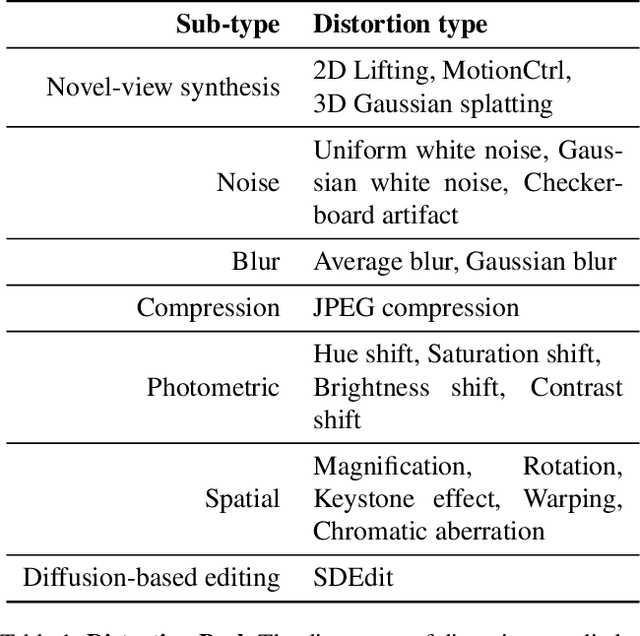

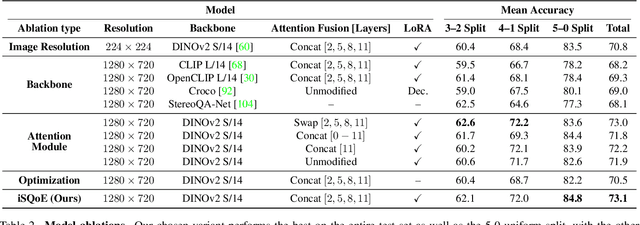
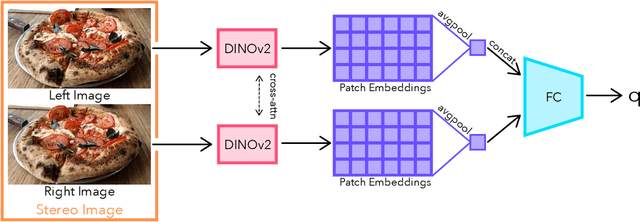
With rapid advancements in virtual reality (VR) headsets, effectively measuring stereoscopic quality of experience (SQoE) has become essential for delivering immersive and comfortable 3D experiences. However, most existing stereo metrics focus on isolated aspects of the viewing experience such as visual discomfort or image quality, and have traditionally faced data limitations. To address these gaps, we present SCOPE (Stereoscopic COntent Preference Evaluation), a new dataset comprised of real and synthetic stereoscopic images featuring a wide range of common perceptual distortions and artifacts. The dataset is labeled with preference annotations collected on a VR headset, with our findings indicating a notable degree of consistency in user preferences across different headsets. Additionally, we present iSQoE, a new model for stereo quality of experience assessment trained on our dataset. We show that iSQoE aligns better with human preferences than existing methods when comparing mono-to-stereo conversion methods.
Novel View Synthesis with Pixel-Space Diffusion Models
Nov 12, 2024Synthesizing a novel view from a single input image is a challenging task. Traditionally, this task was approached by estimating scene depth, warping, and inpainting, with machine learning models enabling parts of the pipeline. More recently, generative models are being increasingly employed in novel view synthesis (NVS), often encompassing the entire end-to-end system. In this work, we adapt a modern diffusion model architecture for end-to-end NVS in the pixel space, substantially outperforming previous state-of-the-art (SOTA) techniques. We explore different ways to encode geometric information into the network. Our experiments show that while these methods may enhance performance, their impact is minor compared to utilizing improved generative models. Moreover, we introduce a novel NVS training scheme that utilizes single-view datasets, capitalizing on their relative abundance compared to their multi-view counterparts. This leads to improved generalization capabilities to scenes with out-of-domain content.